






Hadoop 在大数据技术体系中的地位至关重要,Hadoop 是大数据技术的基础。这是一篇入门文章,以安装部署 Apache Hadoop2.7.7版本为主线.
一、安装环境说明
- 1、操作系统:这里我们使用的是centos 7,如果没有安装,自行安装。centos 7安装链接
- 2、hadoop:Apache Hadoop2.7.7
- 3、java:这里我使用的是java8版本
- 百度云资源下载
提取码:xqzq
二、安装java
1、安装java
首先通过xshell等工具将包上传到Linux上
我们先解压包,我一般都解压到/opt下:
[root@master ~]# tar -zxvf jdk-8u201-linux-x64.tar.gz -C /opt

2、配置环境
[root@master ~]# vim /etc/profile
然后添加以下代码:
export JAVA_HOME="/opt/jdk1.8.0_201/"
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tool.jar
然后保存退出

配置生效:[root@master ~]# source /etc/profile
3、检验是否安装成功
[root@master ~]# java -version

有以上内容就是表示安装成功了!
三、安装Hadoop
1、安装之前需做的一些事情
(1)、配置hosts
[root@master ~]# vim /etc/hosts
添加以下内容:下面是你自己的ip
192.168.xx.xx master

(2)、免密登录
[root@master ~]# ssh-keygen -t rsa
连续三次按Enter

接着:
[root@master ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
更改权限:
[root@master ~]# chmod 700 ~/.ssh
[root@master ~]# chmod 600 ~/.ssh/authorized_keys
2、安装Hadoop
解压包:
[root@master ~]# tar -zxvf hadoop-2.7.7.tar.gz -C /opt

3、配置环境
[root@master ~]# vim /etc/profile
然后添加一下代码:
export HADOOP_HOME="/opt/hadoop-2.7.7"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

配置生效:[root@master ~]# source /etc/profile
4、配置文件(文件都在/hadoop-2.7.7/etc/hadoop/下)
(1)、hadoop-env.sh文件
添加以下内容:
export JAVA_HOME="/opt/jdk1.8.0_201"
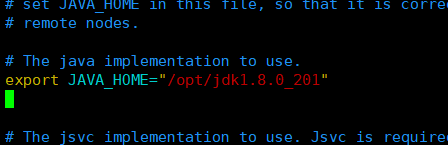
(2)、core-site.xml文件
添加以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
</configuration>

注:hadoop.tmp.dir需要自己手动创建目录文件
[root@master hadoop]# mkdir -p /opt/data/tmp
(3)、hdfs-site.xml文件
添加以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/data/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/data/tmp/dfs/data</value>
</property>
</configuration>

(4)、mapred-site.xml文件
注: 因为没有mapred-site.xml文件,所以
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
添加以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
</configuration>

(5)、yarn-site.xml文件
添加以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>

5、测试
(1)、格式化hdfs
格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中。
[root@master bin]# hdfs namenode -format

(2)、启动 hadoop
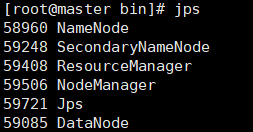
[root@master bin]# start-all.sh
注:这里启动是需要输入密码,所有说为什么之前我们要设置免密登录,不然我们每次都要输入密码很麻烦,但第一次启动它要提醒你输入yes,以后就不用呢。
看到有以下内容就证明我们hadoop配置成功呢!
(3)、查看NameNode格式化后的目录
[root@master ~]# ll /opt/data/tmp/dfs/name/current/

- fsimage是NameNode元数据在内存满了后,持久化保存到的文件;
- fsimage*.md5 是校验文件,用于校验fsimage的完整性;
- seen_txid 是hadoop的版本;
- vession文件里保存:
namespaceID:NameNode的唯一ID。
clusterID:集群ID,NameNode和DataNode的集群ID应该一致,表明是一个集群。
最后关闭hadoop
[root@master ~]# stop-all.sh
到这里我们就可使用Hadoop呢~~















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









