









PaddleSeg部署到windows详细流程
概要
在vs2017上使用C++部署PaddleSeg模型并成功推理。
相关链接:
https://blog.csdn.net/Vertira/article/details/122936086
https://github.com/PaddlePaddle/PaddleSeg
https://github.com/PaddlePaddle/PaddleX/blob/develop/deploy/cpp/docs/compile/paddle/windows.md
https://github.com/PaddlePaddle/PaddleX/tree/release/2.0.0/examples/C%23_deploy
环境依赖
这一部分参照
https://github.com/PaddlePaddle/PaddleX/blob/develop/deploy/cpp/docs/compile/paddle/windows.md
教程中的环境为
本机环境为:
Visual Studio 2017
CUDA 10.1, CUDNN 7.6.5
CMake 3.0+
下载预测代码PaddleX
一开始用的PaddleSeg,但是PaddleX教程多,索性就用paddleX了。本机所用PaddleX版本为2.0。去github上下载。
d:
mkdir projects
cd projects
git clone https://github.com/PaddlePaddle/PaddleX.git
说明:其中C++预测代码在PaddleX\dygraph\deploy\cpp 目录,该目录不依赖任何PaddleX下其他目录。所有的公共实现代码在model_deploy目录下,所有示例代码都在demo目录下。
下载PaddlePaddle C++ 预测库
PaddlePaddle C++ 预测库针对是否使用GPU、是否支持TensorRT、以及不同的CUDA版本提供了已经编译好的预测库。
本机所用预测库不包含TensorRT,因此所下载的的预测库为:
预测库链接:
https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#c
请根据实际情况选择下载,如若以上版本不满足您的需求,请至C++预测库下载列表选择符合的版本。
将预测库解压后,其所在目录(例如D:\projects\paddle_inference_install_dir\)下主要包含的内容有:
├── \paddle\ # paddle核心库和头文件
|
├── \third_party\ # 第三方依赖库和头文件
|
└── \version.txt # 版本和编译信息
安装配置OpenCV
在OpenCV官网下载适用于Windows平台的版本,选择你适用的版本,下载windows版本的,opencv链接:
https://opencv.org/releases/
运行下载的可执行文件,将OpenCV解压至指定目录,例如D:\projects\opencv
配置环境变量,如下流程所示
我的电脑->属性->高级系统设置->环境变量
在系统变量中找到Path(如没有,自行创建),并双击编辑
新建,将opencv路径填入并保存,如D:\projects\opencv\build\x64\vc15\bin
在进行cmake构建时,会有相关提示,请注意输出。
编译PaddleX,Opencv以及paddleinference预测库
为了便于项目管理,将所有的文件汇总到一个文件夹中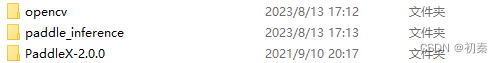
使用Cmake进行编译,我们主要对PaddleX/deploy/cpp中代码进行编译,并创建build文件夹用来承接编译生成的内容,

打开cmake-gui界面,导入相关路径

点击Configure进行,选择x64和vs2017。之后,在红色区域输入相关路径,(CUDA_LIB,OPENCV_DIR,PADDLE_DIR).如下,请不要勾选TENSORRT,要勾选WITH_GPU。若要进行TENSORRT加速,请去官方文档内下载相关文件,并查看教程,这里不做赘述。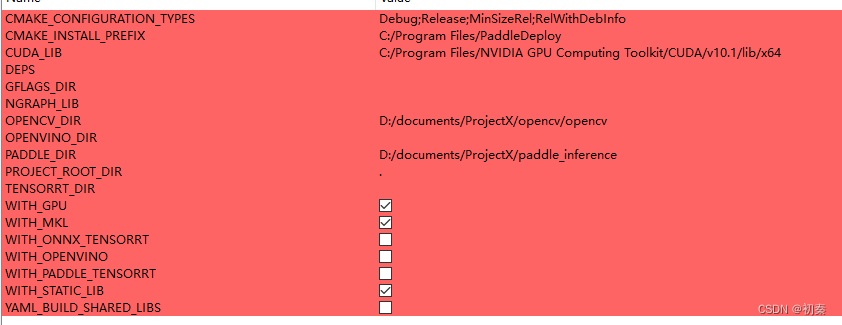
点击Generate进行生成,最终在build文件夹中出现了.sln文件,则表示通过cmake生成成功了解决方案。

打开sln文件,会发现在PaddleDeploy目录下生成了7个项目,其中关键的是
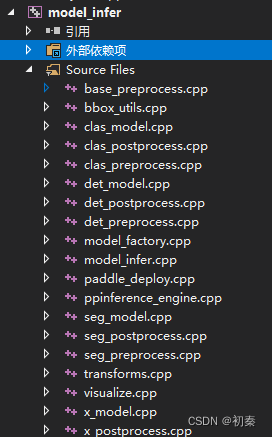
下载并编译yaml
这一步很关键,我看到网上大部分教程没有,我也是查了很久才知道要下载这个。
yaml项目链接:
https://github.com/jbeder/yaml-cpp/releases/tag/yaml-cpp-0.7.0

下载完后解压并建立build文件夹:
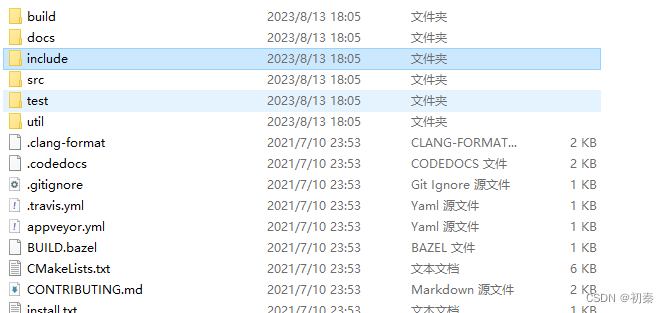
编译参照以下链接:
https://www.cnblogs.com/mxnote/articles/16742022.html
编译完yaml后,将以下目录中lib文件取出来,要复制到paddlx中,详细路径请看下面 转到VS2017,将model_infer设为启动项
转到VS2017,将model_infer设为启动项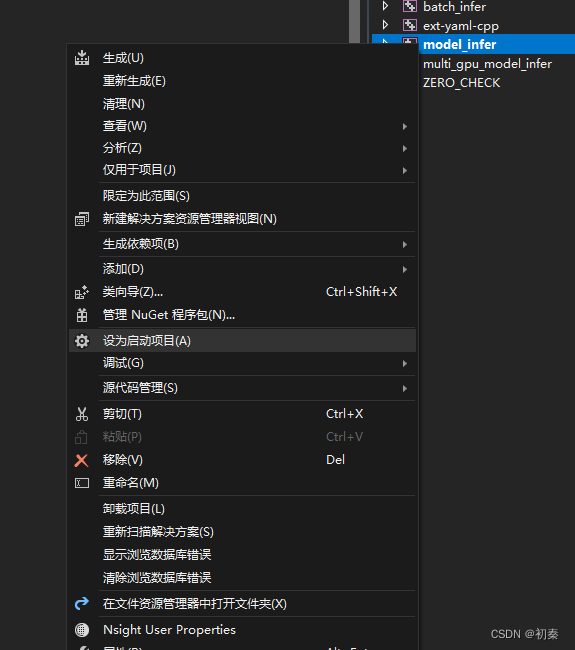
打开model_infer属性,找到附加包含目录,可以看到目录下有一个关于yaml-cpp的路径,但如果你按照这个路径去看,文件内是没有东西,但是我们编译的时候需要yaml-cpp的头文件。包括进行paddleseg的C++部署时,也是缺少了yaml-cpp。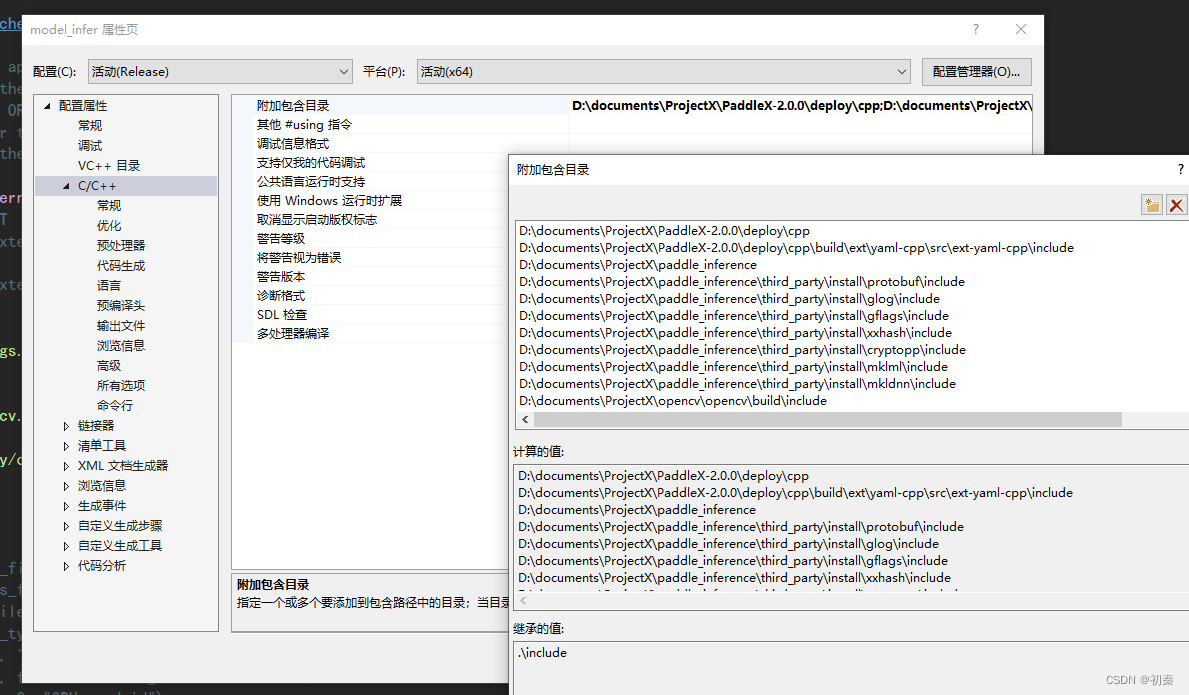
接下来就是将yaml-cpp-0.7.0中include中的文件复制到PaddleX中去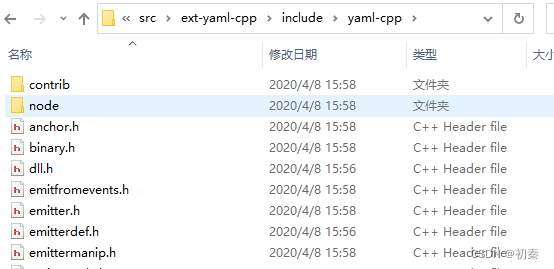
我们在链接器中也要增加lib路径和相关文件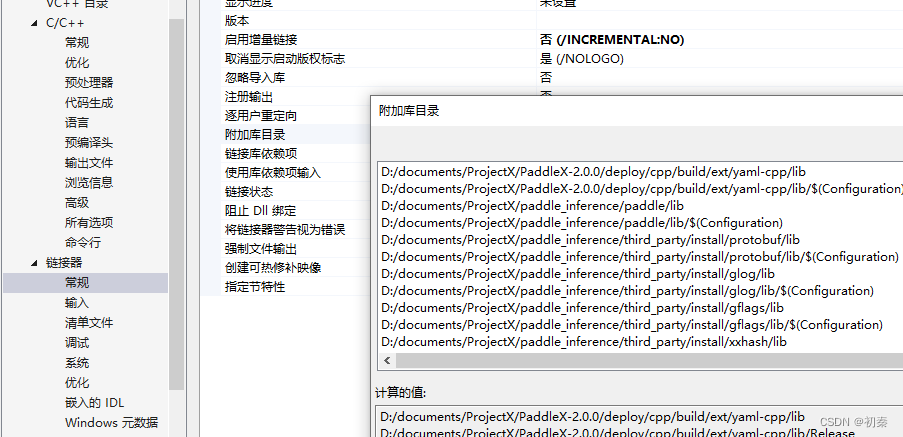
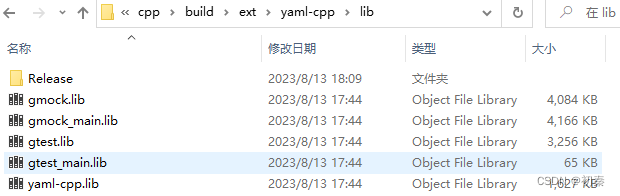
编译model_infer
将其中的model_infer.cpp更改如下:
// Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <gflags/gflags.h>
#include <string>
#include <vector>
#include<opencv2/opencv.hpp>
#include<iostream>
#include "model_deploy/common/include/paddle_deploy.h"
using namespace cv;
using namespace std;
//DEFINE_string(model_filename, "", "Path of det inference model");
//DEFINE_string(params_filename, "", "Path of det inference params");
//DEFINE_string(cfg_file, "", "Path of yaml file");
//DEFINE_string(model_type, "", "model type");
//DEFINE_string(image, "", "Path of test image file");
//DEFINE_bool(use_gpu, false, "Infering with GPU or CPU");
//DEFINE_int32(gpu_id, 0, "GPU card id");
// 这里的struct是为了在自己的项目中接收推理结果,因为推理结果是
//vector<PaddleDeploy::Result>类型,我们自己的项目中没有
struct result_local
{
std::vector<uint8_t> data;
// the shape of mask
std::vector<float> score;
};
//为了导出dll。
#define DLLEXPORT extern "C" _declspec(dllexport)
string model_type = "seg";
PaddleDeploy::Model* model;
//设置接口
DLLEXPORT void Init(string model_filename, string cfg_file, string params_filename, int gpu_id)
{
// create model
model = PaddleDeploy::CreateModel(model_type);
// model init
model->Init(cfg_file);
// inference engine init
PaddleDeploy::PaddleEngineConfig engine_config;
engine_config.model_filename = model_filename;
engine_config.params_filename = params_filename;
engine_config.use_gpu = true;
engine_config.gpu_id = gpu_id;
model->PaddleEngineInit(engine_config);
}
DLLEXPORT void Predict(vector<Mat> imgs, vector<result_local>& results_back)
{
cout << "enter Predict imgs.size(): " << imgs.size() << endl;
vector<cv::Mat> imgs_local;
if (imgs.size() == 0)
{
cout << "nothing pic in";
}
for (int i = 0; i < imgs.size(); i++)
{
imgs_local.push_back(std::move(imgs[i]));
}
// predict
std::vector<PaddleDeploy::Result> results;
model->Predict(imgs_local, &results, 1);
for (int i = 0; i < results.size(); i++)
{
result_local temp;
vector<uint8_t> data = results[i].seg_result->label_map.data;
vector<float> score = results[i].seg_result->score_map.data;
temp.data = data;
temp.score = score;
results_back.push_back(temp);
}
}
//int main(int argc, char** argv) {
// // Parsing command-line
// google::ParseCommandLineFlags(&argc, &argv, true);
//
// // create model
// PaddleDeploy::Model* model = PaddleDeploy::CreateModel(FLAGS_model_type);
//
// // model init
// model->Init(FLAGS_cfg_file);
//
// // inference engine init
// PaddleDeploy::PaddleEngineConfig engine_config;
// engine_config.model_filename = FLAGS_model_filename;
// engine_config.params_filename = FLAGS_params_filename;
// engine_config.use_gpu = FLAGS_use_gpu;
// engine_config.gpu_id = FLAGS_gpu_id;
// model->PaddleEngineInit(engine_config);
//
// // prepare data
// std::vector<cv::Mat> imgs;
// imgs.push_back(std::move(cv::imread(FLAGS_image)));
//
// // predict
// std::vector<PaddleDeploy::Result> results;
// model->Predict(imgs, &results, 1);
//
// std::cout << results[0] << std::endl;
// delete model;
// return 0;
//}
打开属性页-配置属性-常规,将配置类型改为动态库dll,目标文件扩展名改为.dll。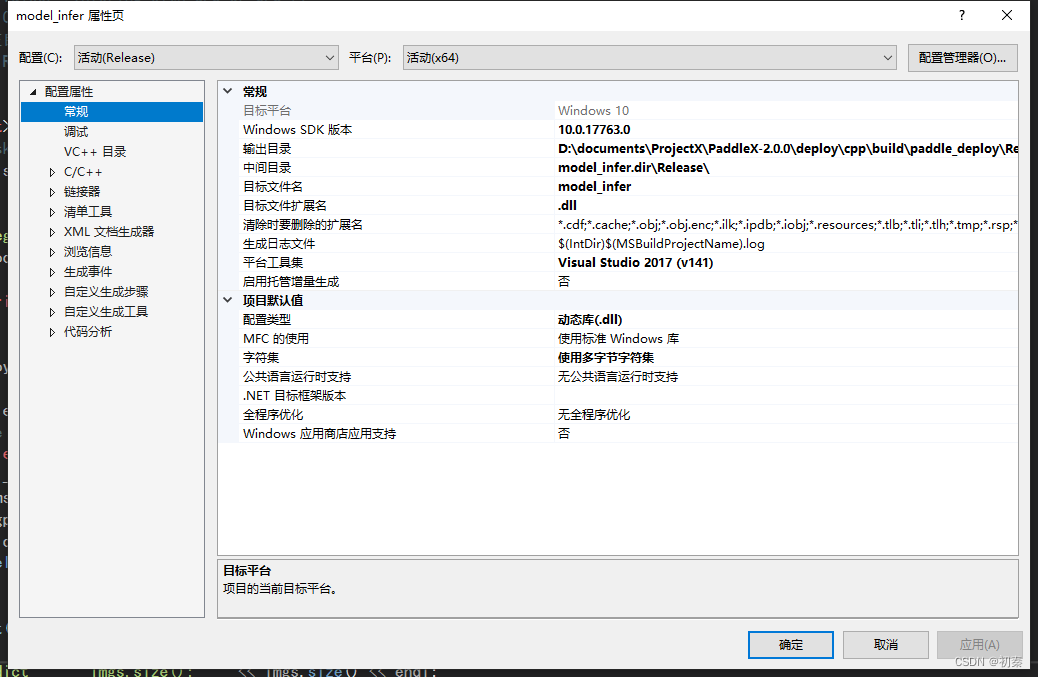
右键项目-点击生成

在VS中新建项目
#include<iostream>
#include<opencv2/opencv.hpp>
#include<Windows.h>
using namespace std;
using namespace cv;
struct result_now
{
std::vector<uint8_t> data;
// the shape of mask
std::vector<float> score;
};
typedef void(*ptrSub_Init)(string model_filename, string cfg_file, string params_filename, int gpu_id);
typedef void(*ptrSub_predict)(vector<cv::Mat> imgs, vector<result_now>& results_back);
HMODULE hMod = LoadLibrary("model_infer.dll");
typedef void(*ptrSub_batch_Init)(string model_filename, string cfg_file, string params_filename, int gpu_id,bool use_trt);
typedef void(*ptrSub_batch_predict)(std::vector<std::string> image_paths, vector<result_now>& results_back, int batch_size);
HMODULE hMod_batch = LoadLibrary("batch_infer.dll");
//这部分是用于接收model_infer的结果
void normal_infer()
{
string imgs_path = "D:/VS_projects/test/";
string cfg_file = "D:/PaddleSeg_projects/PaddleX_DLL/test/deploy.yaml";
string params_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdiparams";
string model_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdmodel";
vector<string> img_names;
glob(imgs_path, img_names);
vector<Mat> imgs;
for (int i = 0; i < img_names.size(); i++)
{
Mat img = imread(img_names[i]);
imgs.push_back(img);
}
vector<result_now> results;
if (hMod != NULL)
{
ptrSub_Init Init = (ptrSub_Init)GetProcAddress(hMod, "Init");
ptrSub_predict Predict = (ptrSub_predict)GetProcAddress(hMod, "Predict");
if (Init != NULL)
{
Init(model_filename, cfg_file, params_filename, 0);
}
if (Predict != NULL)
{
Predict(imgs, results);
}
}
std::cout << results.size() << endl;
std::vector<uint8_t> data = results[0].data;
for (int i = 0; i < imgs[0].rows; i++)
{
for (int j = 0; j < imgs[0].cols; j++)
{
if (data[j + imgs[0].cols * i] == 0)
{
continue;
}
imgs[0].at<Vec3b>(i, j)[0] = data[j + imgs[0].cols * i] * 100;
imgs[0].at<Vec3b>(i, j)[1] = data[j + imgs[0].cols * i] * 100;
imgs[0].at<Vec3b>(i, j)[2] = data[j + imgs[0].cols * i] * 100;
}
}
std::vector<uint8_t> data1 = results[1].data;
for (int i = 0; i < imgs[1].rows; i++)
{
for (int j = 0; j < imgs[1].cols; j++)
{
if (data1[j + imgs[1].cols * i] == 0)
{
continue;
}
imgs[1].at<Vec3b>(i, j)[0] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at<Vec3b>(i, j)[1] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at<Vec3b>(i, j)[2] = data1[j + imgs[1].cols * i] * 100;
}
}
namedWindow("re", WINDOW_AUTOSIZE);
imshow("re", imgs[0]);
namedWindow("re2", WINDOW_AUTOSIZE);
imshow("re2", imgs[1]);
waitKey(0);
}
//这部分用于接收batch_infer的结果
void batch_infer()
{
string imgs_path = "D:/VS_projects/test/";
string cfg_file = "D:/PaddleSeg_projects/PaddleX_DLL/test/deploy.yaml";
string params_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdiparams";
string model_filename = "D:/PaddleSeg_projects/PaddleX_DLL/test/model.pdmodel";
vector<std::string> img_names;
glob(imgs_path, img_names);
vector<Mat> imgs;
for (int i = 0; i < img_names.size(); i++)
{
Mat img = imread(img_names[i]);
imgs.push_back(img);
}
vector<result_now> results;
if (hMod_batch != NULL)
{
ptrSub_batch_Init Init = (ptrSub_batch_Init)GetProcAddress(hMod_batch, "Init");
ptrSub_batch_predict Predict = (ptrSub_batch_predict)GetProcAddress(hMod_batch, "Predict");
if (Init != NULL)
{
Init(model_filename, cfg_file, params_filename,0,false);
}
if (Predict != NULL)
{
Predict(img_names, results,1);
}
}
std::cout << "local result size "<<results.size() << endl;
std::vector<uint8_t> data = results[0].data;
for (int i = 0; i < imgs[0].rows; i++)
{
for (int j = 0; j < imgs[0].cols; j++)
{
if (data[j + imgs[0].cols * i] == 0)
{
continue;
}
imgs[0].at<Vec3b>(i, j)[0] = data[j + imgs[0].cols * i] * 100;
imgs[0].at<Vec3b>(i, j)[1] = data[j + imgs[0].cols * i] * 100;
imgs[0].at<Vec3b>(i, j)[2] = data[j + imgs[0].cols * i] * 100;
}
}
std::vector<uint8_t> data1 = results[1].data;
for (int i = 0; i < imgs[1].rows; i++)
{
for (int j = 0; j < imgs[1].cols; j++)
{
if (data1[j + imgs[1].cols * i] == 0)
{
continue;
}
imgs[1].at<Vec3b>(i, j)[0] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at<Vec3b>(i, j)[1] = data1[j + imgs[1].cols * i] * 100;
imgs[1].at<Vec3b>(i, j)[2] = data1[j + imgs[1].cols * i] * 100;
}
}
namedWindow("re", WINDOW_AUTOSIZE);
imshow("re", imgs[0]);
namedWindow("re2", WINDOW_AUTOSIZE);
imshow("re2", imgs[1]);
waitKey(0);
}
int main()
{
//normal_infer();
batch_infer();
}
这部分代码感谢该博主
注意,新建项目的属性页需要更改两处:

部署中也遇到了很多其他问题,翻阅官方部署文档和百度即可解决多数。
PS:在cmake过程中如果遇到了Could NOT find Git (missing: GIT_EXECUTABLE)这个问题,请去git官网页面下载git windows版本并安装,重启后尝试。















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









