









2022-11-28近期记录
一、CAM
CAM是在神经网络可解释性研究中,对最后一层全连接层修改为GAP的,之后进行可解释性地定位研究。
具体推导过程:

计算方法如下图所示。对于一个CNN模型,对其最后一个feature map做全局平均池化(GAP)计算各通道均值,然后通过全连接层等映射到class score,找出argmax,计算最大的那一类的输出相对于最后一个feature map的梯度,再把这个梯度可视化到原图上即可。直观来说,就是看一下网络抽取到的高层特征的哪部分对最终的classifier影响更大。
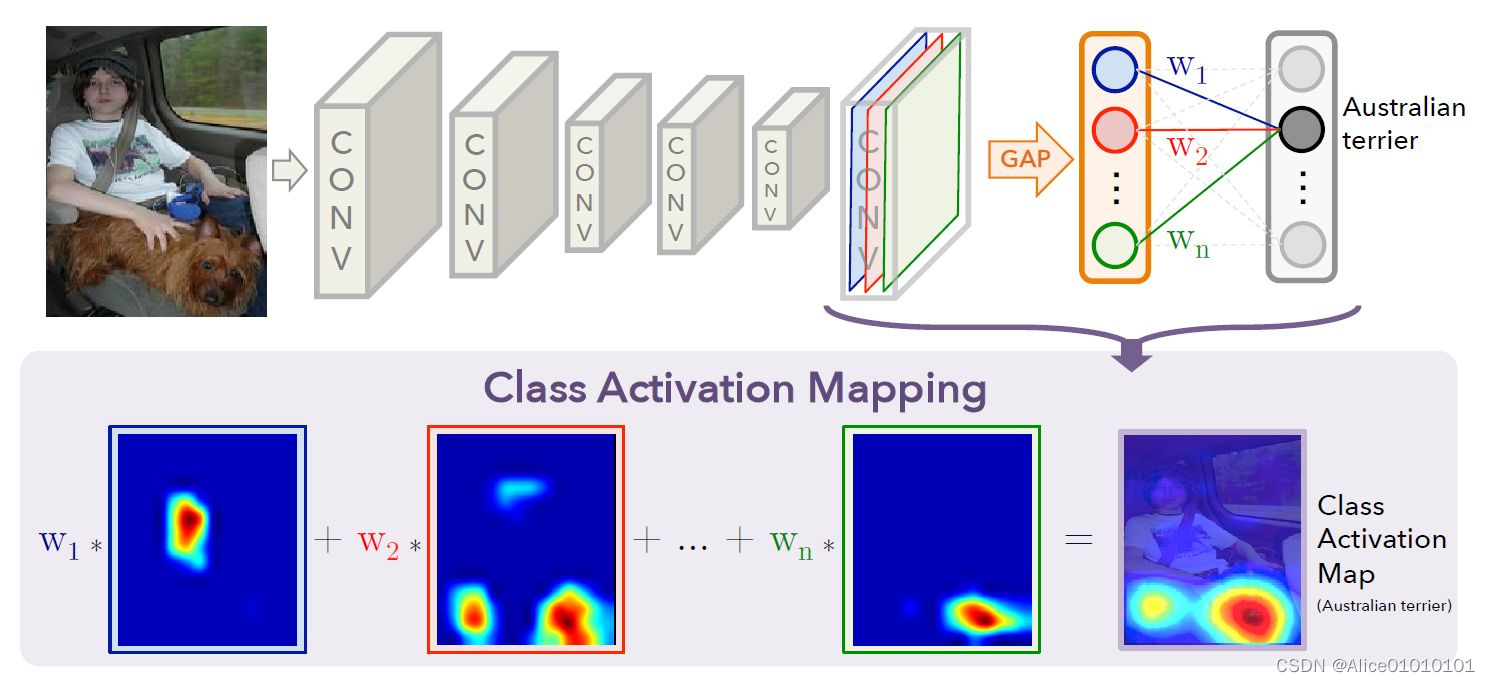
GAP操作后输出最后一个卷积层每个单元feature-map的平均值,之后再接一个softmax层用于分类,而该层的所有参数作为权重wck,对前方的GAP得到的feature-map做加权总和得到最后的输出,即CAM输出。此时CAM的输出尺寸和feature-map大小一致,故需要通过上采样方式还原叠加到原图中。
二、TAS未来展望:
- Input features:使用的特征都是预先计算好的。To the best of our knowledge, no empirical study has thoroughly compared pre-computedfeatures to training from raw images in an end-to-end way,as it is highly challenging in terms of training effificiency and GPU memory requirements.
- Segment-level Modeling:目前针对动作的时序建模,都是迭代进行的。并且模型严重依赖后处理。One promising yet under-explored directionis to explore how to incorporate the sequence-related losses,e.g., edit score penalizing segment wise errors, as a part of the learning. (时序动作分割结果的两种基本表示,segment-based是每段的起始结束和分类,frame-based是每帧的类别,两者可以相互转换。)上面英文强调设计基于segment-based的loss还有待探索。目前大多数loss都是frame-based,也有待于进一步的探索。
- Forms of Supervision:相邻帧之间存在冗余,提倡弱监督和半监督的探索。在实际标注中,how to deal with the possible of missing actions仍然是一个问题。另外,如何更准确地定义(标注)动作边界仍然是一个问题。
- online end-to-end model
三、在TAS中尝试引入Transformer存在的问题
- 目前针对TAS任务的数据集都较小,而transformer存在inductive biases,需要大量的视频来确保有效地训练。
- Another problem indicated by is that the self-attention mechanism may not learn meaningful weights from a extended span of inputs.个人理解是,自注意力模型会进行长距离建模,而时序动作分割任务不需要过长的帧之间建立联系权重。
四、survey中对使用prototype的comment
A recent work, DP-DTW [145], learns class-specific discriminative action prototypes for weakly- supervised segmentation and propose that videos could be represented by concatenating prototypes according to transcripts. The model aims at increasing the inter-class difference among prototypes via discriminative losses.
Rethinking:
和之前为每一个class类学习一个权重weight或者query不同,我们的模型将每个class类表示为一组(a set of)non-learnable prototypes,仅仅依赖当前class中的几个training pixels的feature的平均值。 跨类别,取cosine-similarity相似度最大的那个proto,该proto有自己对于每个类别的相似度。
Transcript:每个action作为一个proto,所有的proto和所有的帧之间进行dtw。
Rethinking是每一个frame到每一个proto的cosine相似度;DP-DTW是每一个序列(一段视频)到每一组proto(动作序列)的相似度计算。
Proto是通过DTW的计算来更新的,DTW的计算是基于上一次的proto和当前倒数第二层的输出来进行计算。
Loss对_c倒数第二层进行更新,对proto不进行更新。
Proto更新的过程没有聚类的思想。
五、EM-TSS:A Generalized & Robust Framework For Timestamp Supervision in Temporal Action Segmentation
基于timestamp的另一篇文章,提出不刻意针对每一个动作片段抽取一帧,减少标注时间,并且引入action missing的问题。文章认为每段视频中各个动作片段的长度服从泊松分布,并进行了相应的处理。文章利用EM方法生成伪标签,迭代更新进行学习。
The E-step is defined to train the network for the label estimation, while the M-step maximizes the timestamp segment likelihood and finds the boundary accordingly.E-step根据网络参数和已知标签来预测未知标签;M-step根据当前网络参数和预测的标签来更新下一次的网络参数。
EM算法的经典解释:

Timestamps action segmentation:
gtea和breakfast的帧率都是15fps,sample_rate=1;50salads的帧率为30fps,实验中sample_rate=2。
抽取的timestamps是提前抽取好,做成了annotation.npy的。50salads中每个视频抽取20帧,gtea中每个视频抽取30帧,breakfast中大概3-11帧不等。beakfast每个视频平均6.9个动作。
timestamps就是每个动作一帧。
六、ICC:Iterative Contrast-Classify For Semi-supervised Temporal Action Segmentation半监督

半监督是对少量视频进行全标注;弱监督是对所有视频进行部分标注。
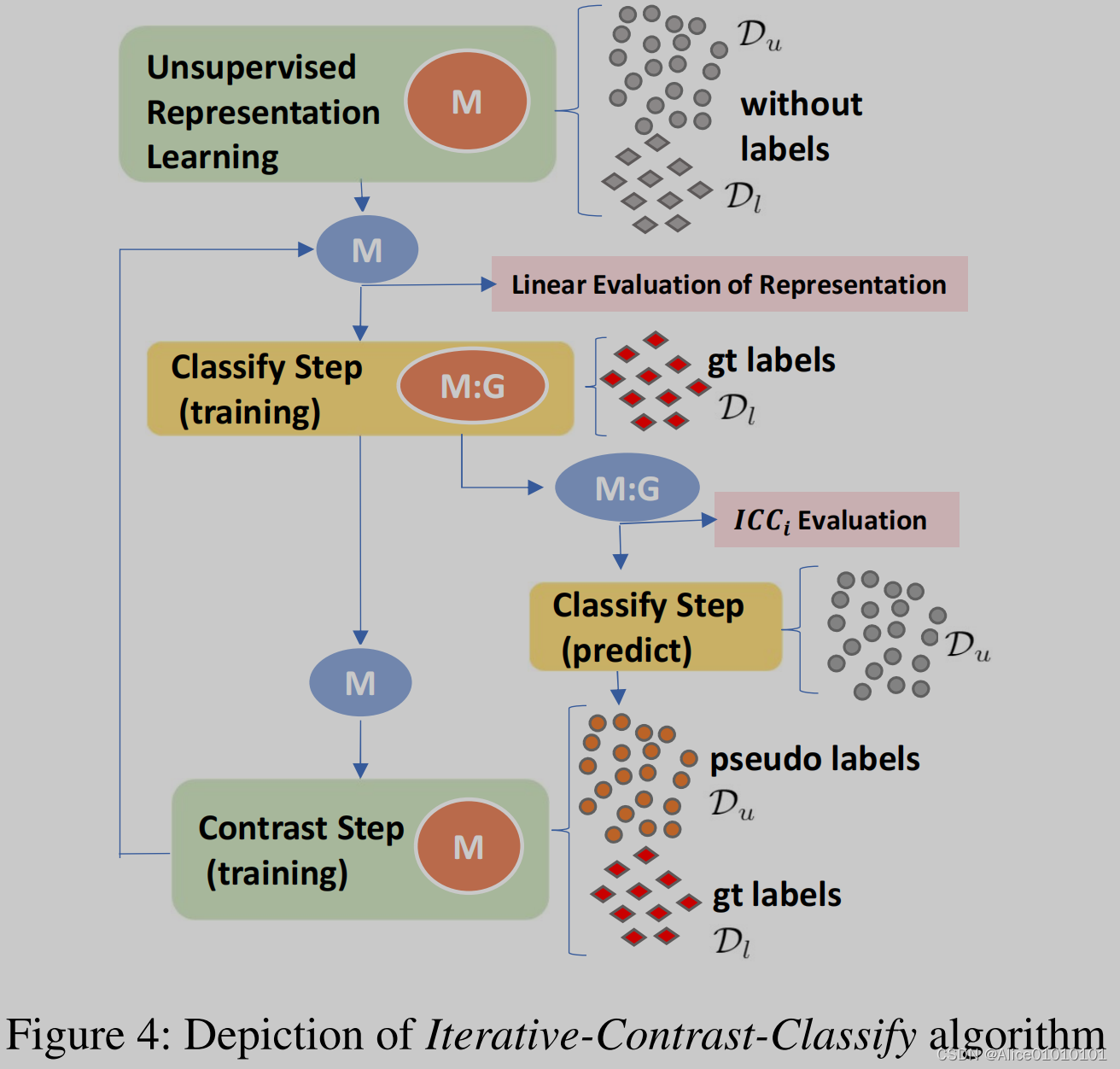
最开始利用所有的数据,借助聚类(不使用标签)进行对比学习,初始化模型参数M。之后利用带标签的数据训练训练模型M和分类头G,其次利用无标签的数据通过M:G生成伪标签。将伪标签和真实标签一起,带入对比学习中训练,更新模型M的参数。
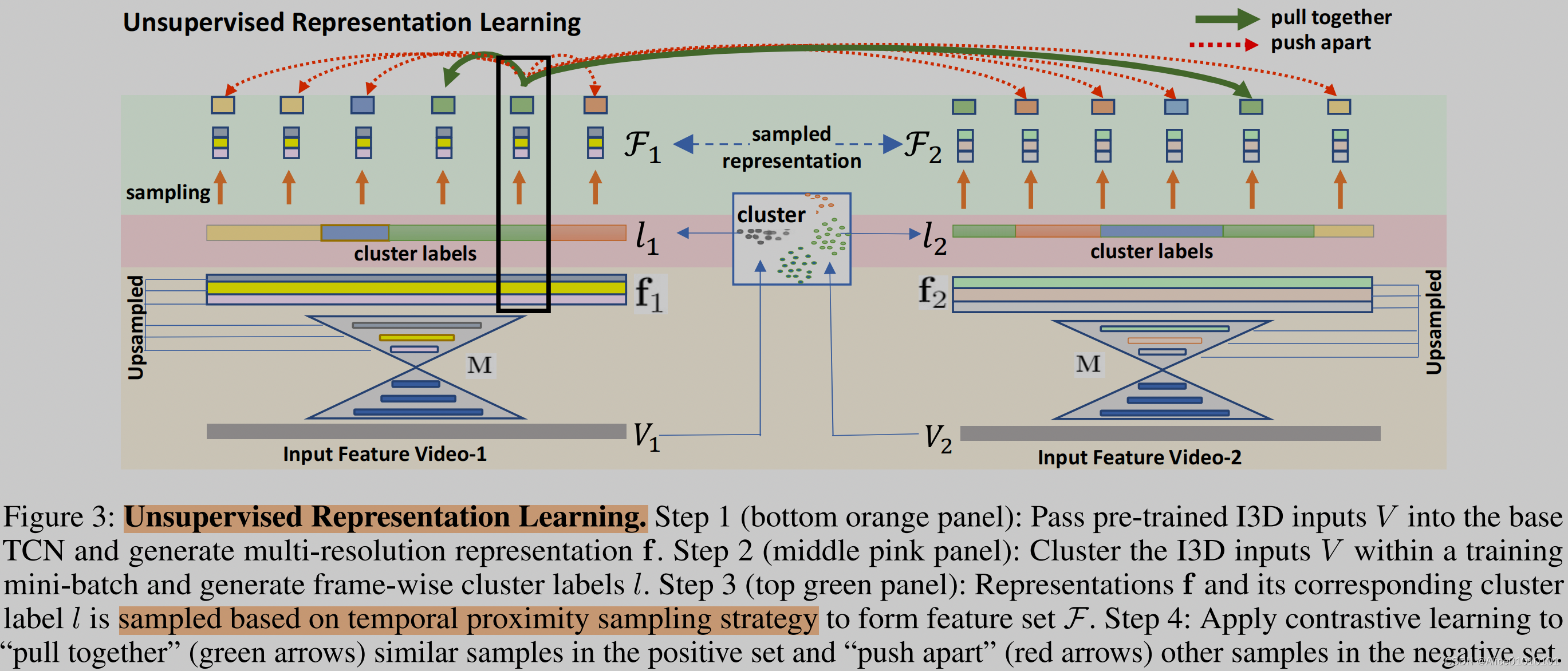
整个操作是所有视频一起进行的。frame-level的对比学习时,正样本对由同一视频、同一聚类标签、时间差距小于阈值的样本对,和不同视频中、同一聚类标签的样本对组成。同一视频、同一聚类标签、时间差距大于阈值的样本不参与计算。负样本对由除了正样本对、不予考虑的样本对和自己之外的样本对组成(同一视频不同聚类标签,不同视频不同聚类标签)。之后video-level的对比学习,因为之后breakfast数据集有高阶语义标签,所以只对它起作用(将两个loss加起来)。
七、数据集
assemble101:
之前数据集的缺陷:
small:GTEA;50salads
have little ordering variations: breakfast
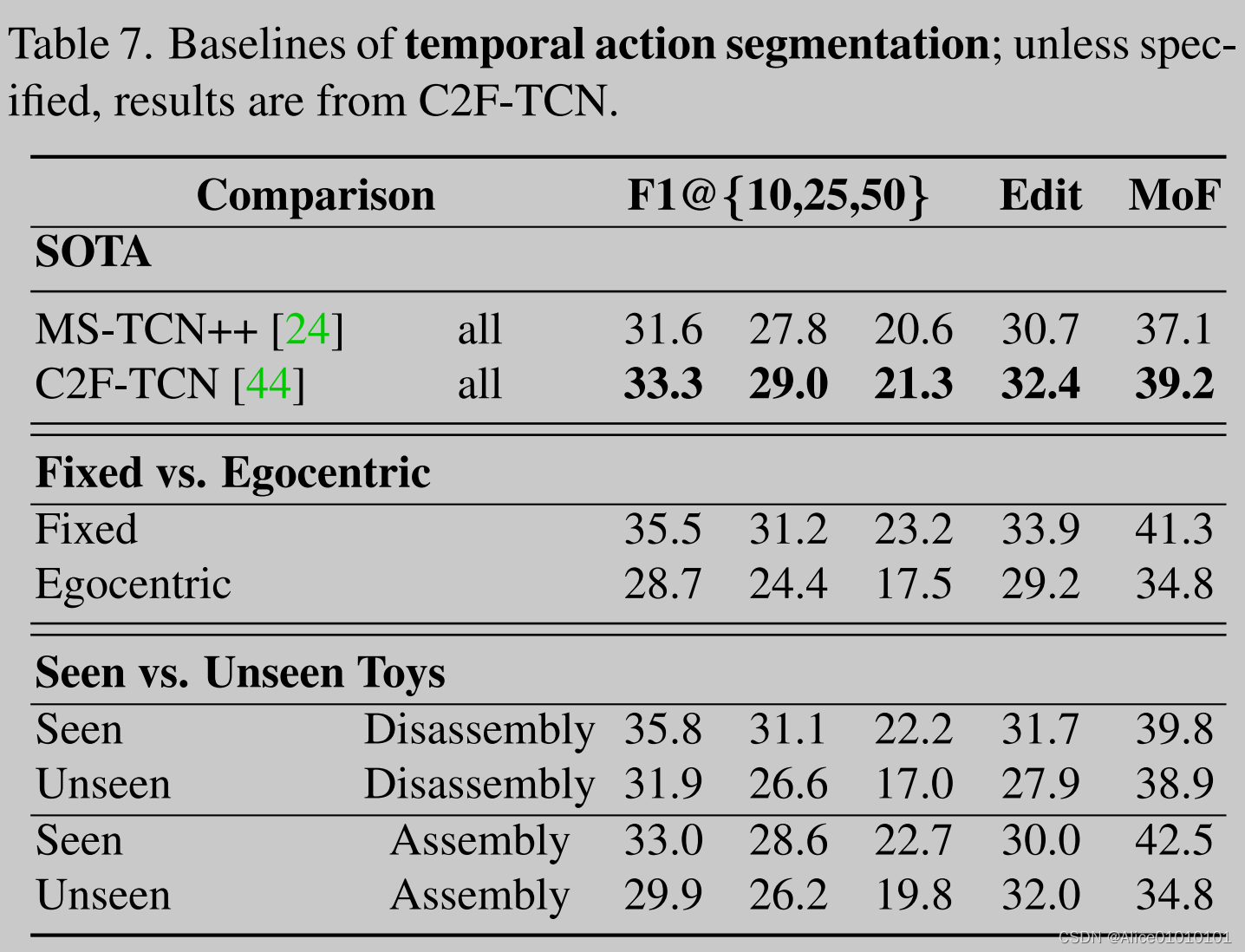
图中SOTA方法使用的backbone是TSM对Assemble101数据集进行特征提取(直接拿文中上一个针对action recognition 的任务提取的特征进行)。
Unsurprisingly, fixed viewpoints perform better than egocentric viewpoints. 多视角比自我中心的视角效果好。说明以自我为中心的视角更具有挑战性(更难)。
指标edit是关于顺序的,edit指标越大,预测的order和真实的order越接近。
Assemble没有给录制视频的人提供动作步骤。
There are also toy instances that are not a part of the training set to facilitate zero-shot learning.
八、Rethinking Semantic Segmentation: A Prototype View
目前流行的语义分割方法,除了它们不同的网络设计(基于FCN或者基于attention),和不同的掩码解码策略(基于参数化的softmax或者基于pixel-query),当将softmax weights,或者query vectors视为可学习的类别原型时,这些方法都可以被归为一类。从这种原型的角度,研究揭示了这种参数化分割方法的几处局限,并且提出了一个基于非参数化原型的非参数化可选择策略。和先前在完全参数化方法中,为每个类只使用一个单一的权重或者query不同,我们的模型将每个类表示为一系列的非参数化原型,仅仅依赖于当前类中几个训练像素的平均特征值。模型通过非参数化最近邻元素检索,实现密集预测。这使得我们的模型通过优化嵌入像素和锚点原型之间的安排,来直接生成像素嵌入空间。它能够用一定数量的可学习参数来处理任意数量的类。实验表明,在FCN-based和attention-based分割模型,以及backbone上面,我们非参数化框架性能良好。

九、Unsupervised Feature Learning via Non-Parametric Instance Discrimination
使用带有类别标签的数据进行训练的神经网络分类器也可以隐式地捕捉类别之间的视觉相似性。我们研究这一结果是否可以扩展到传统监督学习领域之外:我们是否能够仅仅通过使每个样例的特征具有可判别性,从而学习到一个很好的表示,能够捕捉到样例之间而不是类别之间明显的相似性。
我们将这种观点表述为实例级别的非参数分类问题,并且使用噪声弹性估计来处理由大量实例带来的计算挑战。
我们的实验结果表明,在无监督学习的设定下,我们的方法在很大程度上超越了在ImageNet classification上的sota方法。我们的方法也在使用更多的训练数据和更好的网络结构得时候,大幅度持续性地提高测试性能。通过在学习到的特征上面微调,我们进一步在半监督学习和目标检测任务上获得了较好的结果。我们的非参数化模型是高度紧凑的:每张图片拥有128个特征,我们的方法针对100万张图片只需要600MB存储空间,运行时启用快速的最近邻检索。
However, obtaining annotated data is often very costly or even infeasible in certain cases.

















 3124
3124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









