







1、大数据概念
大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。即,大数据主要解决:海量数据的采集、存储和分析计算问题。
常见数据存储单位(由小到大):
- bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB;
- 1Byte = 8bit 1K = 1024Byte 1MB = 1024K 1G = 1024M 1T = 1024G 1P = 1024T
2、大数据4V特点
-
Volume(大量)
截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级。
-
Velocity(高速)
这是大数据区分于传统数据挖掘的最显著特征。根据IDC的“数字宇宙”的报告,预计到2025年,全球数据使用量将达到163ZB。在如此海量的数据面前,处理数据的效率就是企业的生命。
-
Variety(多样)
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求。
关系数据库用于结构化数据,大多数其他类型的应用程序用于非结构化数据。
▲
结构化数据,可以从名称中看出,是高度组织和整齐格式化的数据。它是可以放入表格和电子表格中的数据类型,计算机可以轻松地搜索它。在项目中,保存和管理这些的数据一般为关系数据库,当使用结构化查询语言或SQL时,计算机程序很容易搜索这些术语。结构化数据具有的明确的关系使得这些数据运用起来十分方便,不过在商业上的可挖掘价值方面就比较差。典型的结构化数据包括:信用卡号码、日期、财务金额、电话号码、地址、产品名称等。
▲
非结构化数据,本质上是结构化数据之外的一切数据。存储在非关系数据库中,并使用NoSQL进行查询。它可能是文本的或非文本的,也可能是人为的或机器生成的。简单的说,非结构化数据就是字段可变的的数据。
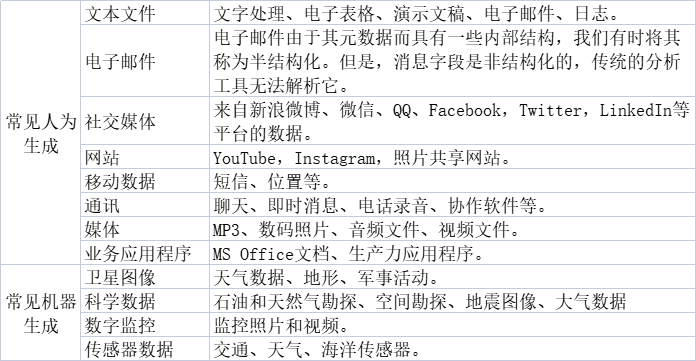
相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。-----吴恩达
-
Value(低价值密度)
价值密度的高低与数据总量的大小成反比。,如何快速对有价值数据“提纯”成为目前大数据背景下待解决的难题。
3、 大数据应用场景
- 热门视频的推荐(推荐的都是你喜欢的类型)
- 电商商品的推荐
- 线下超市商品的摆放(尿不湿和啤酒)
- 物流仓储商品类型数量的存放
- 保险金融房产等商业的精准营销
- 人工智能+5G+物联网+虚拟现实















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









