






数据仓库
文章目录
1. 范式
范式:
第零范式: 无重复数据
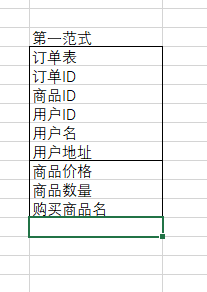
第一范式:满足属性不可分 (例如购买信息(商品价格 , 商品数据))
第二范式:在第一范式得基础上更进一步,确保数据库每一个字段都只和主键相管
第三范式:确保数据表中得每一列数据都和主键直接相关,而不能间接相关
在第二范式得基础上,属性只能直接依赖主键
数据仓库和范式之间存在一种什么关系?
维度建模中得星型模型: 在范式上符合第二范式

订单表为事实表,商品表和用户表为维度表,维度表环绕在事实表得周围
雪花模型: 最大得区别 维度表和事实表是否直接相连
有冗余得事实表:将一些维度。例如用户,商品信息 冗余到事实表中
在范式理论上符合第一范式
2. 数据库 & 数据仓库 侧重点
对于绝大多数得数据仓库来说,一半情况下不会考虑满足第几范式
数据库: 设计 联机事务处理 OLTP(online transaction processing) 基本日常事务处理 更删改查操作
数据仓库: 联机分析处理 OLAP 面向日常数据分析, 数据得插入和查询, 基本上不设计数据得删除和修改操作
3. 维度基本概念
度量 指标 = 事实
对于一些环境描述 = 维度
分析交易 : 商品 时间 买家 卖家 都是维度 ==> 用于分析指标所需要得一个多样得环境
维度获取方式:
- 业务定义得
- 数据中去获取
4. 如何去设计一张表
-
选择一个维度 时间?商品?地区? …
-
确定一张主维表 t_item
-
确定相关/需要关联得维表 - spu 店铺 商家 类目 sku
iphone4 就是一个spu
sku iphone4得规格 颜色 大小 件 盒 托盘 -
确定维度属性
4.1 尽可能丰富 对下游使用维度表 更方便 统计分析类得操作
ID name
4.2 字段 作为维度 还是具体得事实
通常情况下用于查询得约束条件(where) 或者 用于分组统计
通常参与实际得度量计算 事实 -
维度的层次结构
上卷 下钻

-
类目、地区、品牌是否应该全部存在于一张商品维表当中?
规范化
对于大多数的OLTP系统来说,底层的数据模型设计时 通常会采用规范化的方式
将一些维度属性 移到 他们自身所属的表当中,删除冗余数据类目 商品 ==> 1:n
反规范化
退化维度 冗余一部分数据 一张平表 打平
易用性比较高 存储成本升高了

-
一致性维度
什么是一致性维度?
例子 : 流量 - item - pv uv
交易 - item - gmv
数据探查(交叉探查): 将不同业务域(数据域) 得商品维度得数据给结和到一块进行展示
item pv uv gmv商品维度 流量 a b c 交易 b c d e f g 业务域不同 join 后 会有空字段 时间维度 timestamp yyyy-MM-dd
针对这类问题如何解决?
共享维度表
同个BU下建立同一个体系
- 维度整合和拆分
数据仓库得定义: 面向主题得集成得数据集合
表现形式& 注意点
表名、字段名、得命名规范统一
字段类型统一
业务含义相同得表进行统一、 高内聚、低耦合得设计理念 => 把业务系统,源端数据形式差异较小得表进行整合,差异很大得表进行拆分
设计原则: 扩展性 : 高内聚 低耦合
易用性
效率
-
历史数据得归档
归档到OSS
归档策略1: 前台商品展示策略 : 商品状态 商品是否被删除 更新策略
==> 不做展示意味着 下单信息不会有这批商品
跟着前台商品得归档策略走
问题: 实现后 维护成本很高
归档策略2: binlog 去解析哪些数据做了操作和更新
了解一下归档策略3: 最合适得
自定义归档策略: 如何自定义?
通过设置数仓表得生命周期来实现归档策略
统一ODS保留三天
DWD 保留93
dw 保留93
report 历史全部保留
增量表 历史全部保留 -
缓慢变化表
数仓重要特点: 反应数据历史变化趋势
如何去处理维度得变化?是整个维度设计过程中得最重要工作
维度得变化实际上是不怎么频繁得。(订单 状态不停在变)
第一种处理方式: 重写维度值
第二种处理方式: 新增维度行
第三种处理方式: 新增维度列

- 快照维表
快照: 某个时间点的状态;
快照周期: 多久去获取一次数据 天 h min
问题: 按天获取快照, 如何获取?
item表为例
分区表
0601 item1 item
0602 item2 item
0607 item7 item
item表每天都在insert 和 update 、 delete? 如果删除的话 是物理删除 还是逻辑删除 ? is delete
按天进行数据抽取的操作 T+1 数据是延迟一天
0602的凌晨1点 取抽取 mysql端0601 24:00 的数据 , create_time \ update_time(edit_time) 限制范围 保证2号抽取到的数据是1号的所有数据,放入dt=20200601的分区里面去
。。。。。。。全量构建一张快照表
这样的构建方式是否有问题?
最大的问题,当数据量达到多少 ,不合适? 一年有365个分区
n张表 365*N
1+2+3+4+5+6+7+…+365 (3副本)
第二个性能问题: 抽取
sqoop 抽,抽取慢, 怎么解决? 加大Map 数 -m 往上加,一定程度上可以加快整体的抽取速率
问题: 凌晨对多个实例进行抽取,一个实例下面会有多个mysql库
一个库 下面有多个mysql表
最大两个问题: 性能 存储
5. 增量 全量
20200601时刻的数据
下单日期 订单编号 手机号码 支付金额 支付状态 create_time update_time
2020-06-01 001 111111 1 0 2020-06-01
2020-06-01 002 222222 2 0 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01
2020-06-01 004 444444 4 0 2020-06-01
20200602时刻的数据
2020-06-01 001 111111 1 0 2020-06-01
2020-06-01 002 222222 2 0 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01
2020-06-01 004 444444 4 1 2020-06-02
2020-06-01 005 444444 5 1 2020-06-02
dt=20200601
2020-06-01 001 111111 1 0 2020-06-01
2020-06-01 002 222222 2 0 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01
2020-06-01 004 444444 4 0 2020-06-01
dt=20200602
2020-06-01 004 444444 4 1 2020-06-02
2020-06-01 005 444444 5 1 2020-06-02
sqoop:
全量初始化过程, 全量抽取,将历史数据全部抽取到hive中 ods== 清洗== dwd
增量抽取 单纯的抽取 怎么抽? 怎么判断 所抽取的数据是当天生成的或当天更新的
方法一: 判断 updatetime >= 2020-06-01
为什么不用createTime,因为updateTime 可以将当天更新的字段拿到,不用createTime
为什么updateTime不能等于? 用substr(xx,1,10) 去只抽61当天更新数据
业务库得时间段 格式到 秒 ,substr(create_time,1,10) = 2020-06-01
Hive里面是一个对应得增量表。 ods_order_di
ods_order_d dwd_order_d 全量表
ods_order_di 增量表 为了避免每次抽,提升抽取效率,改为增量抽 需要一张增量表
问题: 增量数据如何合并到 ods_order_d 这张全量表里面去?用分区去写会不会数据不准确?全量表和增量表得界限问题。
dwd_order_d dt=20200601 历史全量
dt=20200602 历史增量 如果加过来之后去查,不指定分区 ,会查到两条004得数据
因为在mysql端 004得记录是被直接更新掉得,但是在增量抽取得时候会多出一条数据
如何解决数据重复问题?
如果ID 相同,则update数据
全量表
loeft join
增量表
on 全量表.订单编号 = 增量表.订单编号
下单日期 订单编号 手机号码 支付金额 支付状态 create_time update_time
2020-06-01 001 111111 1 0 2020-06-01
2020-06-01 002 222222 2 0 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01
2020-06-01 004 444444 4 0 2020-06-01
2020-06-01 004 444444 4 1 2020-06-02
2020-06-01 005 444444 5 1 2020-06-02
==》关联后的结果集
a.trade_no b.trade_no
2020-06-01 001 111111 1 0 2020-06-01
2020-06-01 002 222222 2 0 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01
2020-06-01 004 444444 4 0 2020-06-01 2020-06-01 004 444444 4 1 2020-06-02 (关联上)
===》所需要取的结果集:这些记录是没有做过更新操作的记录
2020-06-01 001 111111 1 0 2020-06-01
2020-06-01 002 222222 2 0 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01
union all
2020-06-01 004 444444 4 1 2020-06-02
2020-06-01 005 444444 5 1 2020-06-02
5.1 全量表 增量表整合 实际操作
全量表
create table dwd_order_d(
pay_day string,
trade_no string,
phone string,
pay_amount decimal(18,2),
pay_status int,
update_time string
)
row format delimited fields terminated by ','
stored as textfile;
增量表
create table ods_order_di(
pay_day string,
trade_no string,
phone string,
pay_amount decimal(18,2),
pay_status int,
update_time string
)
row format delimited fields terminated by ','
stored as textfile;
数据入表
dwd_order_d
2020-06-01,001,111111,1,0,2020-06-01
2020-06-01,002,222222,2,0,2020-06-01
2020-06-01,003,333333,3,0,2020-06-01
2020-06-01,004,444444,4,0,2020-06-01
ods_order_di
2020-06-01,002,222222,2,1,2020-06-02
2020-06-01,004,444444,4,1,2020-06-02
2020-06-02,005,444444,4,0,2020-06-02
load data local inpath ‘/home/hadoop/data/order_his.txt’ into table dwd_order_d;
load data local inpath ‘/home/hadoop/data/order_increment.txt’ into table ods_order_di;
insert overwrite table dwd_order_d
select
a.pay_day,
a.trade_no,
a.phone,
a.pay_amount,
a.pay_status,
a.update_time
from(
select
pay_day,
trade_no,
phone,
pay_amount,
pay_status,
update_time
from dwd_order_d
) as a
left join
( select
pay_day,
trade_no,
phone,
pay_amount,
pay_status,
update_time
from ods_order_di
) as b
on
a.trade_no = b.trade_no
where b.trade_no is null
union all
select
pay_day,
trade_no,
phone,
pay_amount,
pay_status,
update_time
from ods_order_di;
2020-06-01 001 111111 1 0 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01
2020-06-01 002 222222 2 1 2020-06-02
2020-06-01 004 444444 4 1 2020-06-02
2020-06-02 005 444444 4 0 2020-06-02
数据流转:
初始化:mysql order => hive ods_order_d => dwd_order_d
增量: => hive ods_order_di
大数据抽取+merge到全量得过程 相比 之前全量快照表 插别在那里 有那些性能得提升
- 抽取性能提升, 业务库得压力减少
- 到数仓之后,数据量会减少吗?
dwd层一直都是全量 是没减少得
ods 减少,原来天天全量抽,现在天天增量抽 但是不明显
因为ods层只保留3天数据
6. 拉链表

多了start_date 和end_date 2个极端 标识所在记录得生命周期
拉链表得意义是什么
方式一: 全量抽取 ods+dwd 按天分去 天天全量
方式二:增量抽取 merge到全量
方式三:拉链表 降低非常多得存储
拉链表可以兼顾某个时刻得某个数据
6.1 拉链表制作
--ods初始化全量表
create table ods_order_d(
pay_day string,
trade_no string,
phone string,
pay_amount decimal(18,2),
pay_status int,
update_time string
)
row format delimited fields terminated by ','
stored as textfile;
load data local inpath '/home/hadoop/data/order_his.txt' into table ods_order_d;
--拉链表
create table dwd_order_ds(
pay_day string,
trade_no string,
phone string,
pay_amount decimal(18,2),
pay_status int,
start_date string,
end_date string
)
row format delimited fields terminated by ','
stored as textfile;
初始化拉链表
日期:2020 06 01
insert overwrite table dwd_order_ds
select
pay_day,
trade_no,
phone,
pay_amount,
pay_status,
'2020-06-01' start_date,
'9999-12-31' end_date
from
ods_order_d;
日期:2020 06 02
第二步:
1. 对于历史已经更新掉得数据, end_date 要从9999-12-31 改为失效得那一天日期
2. 要将新增得记录 or 被更新得记录 insert进去 同时将对一个得start end赋值
insert overwrite table dwd_order_ds
select
t.*
from
(
select
a.pay_day,
a.trade_no,
a.phone,
a.pay_amount,
a.pay_status,
a.start_date,
case when end_date='9999-12-31' and b.trade_no is not null then '2020-06-01'
else a.end_date end as end_date
from dwd_order_ds as a
left join ods_order_di as b
on a.trade_no = b.trade_no
union all
select
c.pay_day,
c.trade_no,
c.phone,
c.pay_amount,
c.pay_status,
'2020-06-02' as start_date,
'9999-12-31' as end_date
from ods_order_di as c
) as t;
dwd_order_ds
2020-06-01 001 111111 1 0 2020-06-01 9999-12-31
2020-06-01 002 222222 2 0 2020-06-01 9999-12-31
2020-06-01 003 333333 3 0 2020-06-01 9999-12-31
2020-06-01 004 444444 4 0 2020-06-01 9999-12-31
ods_order_di
2020-06-01 002 222222 2 1 2020-06-02
2020-06-01 004 444444 4 1 2020-06-02
2020-06-02 005 444444 4 0 2020-06-02
==》
a b
2020-06-01 001 111111 1 0 2020-06-01 9999-12-31
2020-06-01 002 222222 2 0 2020-06-01 9999-12-31 2020-06-01 002 222222 2 1 2020-06-02
2020-06-01 003 333333 3 0 2020-06-01 9999-12-31
2020-06-01 004 444444 4 0 2020-06-01 9999-12-31 2020-06-01 004 444444 4 1 2020-06-02
2020-06-02 005 444444 4 0
拉链表与增量更新的表 一关联 关联上的 也就意味着 数据是被更新了的
==> key
2020-06-01 001 111111 1 0 2020-06-01 9999-12-31 0
2020-06-01 002 222222 2 0 2020-06-01 2020-06-01
2020-06-01 003 333333 3 0 2020-06-01 9999-12-31
2020-06-01 004 444444 4 0 2020-06-01 2020-06-01
2020-06-01 002 222222 2 1 2020-06-02 9999-12-31
2020-06-01 004 444444 4 1 2020-06-02 9999-12-31
2020-06-02 005 444444 4 0 2020-06-02 9999-12-31
6.2 拉链表缺陷
- 加字段会有影响吗
历史状态数据会丢吗?
例如: mysql 端 a字段在2020-06-01加上了 。而且a字段很重要 业务统计要用
hive端 a字段 2020-06-07才知道 所以 1-7号 关于a字段的状态就丢了e
1个月后 业务统计又恰好需要历史状态
-------拉链表该不该轻易加字段?
-------我们在做拉链表要考虑周全 需要什么字段
-------mysql 加 hive也加 , 有用吗?
业务上 要加这个字段 对于历史数据来说 ,是有默认值的
hive端对于拉链表来说, 历史的数据也需要有默认值,这个时候重新初始化吗? 能做吗? 历史状态数据没了鸭!
解决方法:
insert overwrite dwd_order_ds
select
a
b
c
d
e
…
0 as new column
from dwd_order_ds; - 上游出现脏数据了 怎么办?
以订单数据为例 变化周期是固定的 确定业务周期, 这些数据过了这个周期之后是不会再变了,需要做数据结转。
数据结转: dp 过期 历史 活跃 ,
过期: 存放所有生命周期已经无效的数据
历史:不会再做变更的数据
活跃:每天将会更新的数据 还在业务周期内 - 注意点 :关联键 一定要和业务确认好
6.3 拉链表 优化
-
指定分区字段: 查询能做分区裁剪
dp
业务上的时间 pay_day -
存储格式 列式存储 ORC
7. 维度表设计
7.1 微型维度
维度表设计的时候 : 维度的过度增长
之前:主从表的设计理念
数据不怎么会发生变化的字段: 给拆出来作为微型维度 , 单独的放一张维表进行存储
关联的时候 通过微型维度ID 进行关联
在极限存储 : 拉链表 会使用
7.2 类目维度表设计

类目结构参考: 类目维度表设计的图
需求:类目Id为2的类目, 2020-5售卖课程产生多少交易额

8. 事实表的设计
8.1 事实表的特性
- 事实是什么? 度量整个业务过程的
对应的 事实标中的一条记录 所表达的业务的一个细节程度为粒度
比方: 交易下单事实表: 粒度 肯定为订单
存在场景:购物车 多个商品 来源于不同(2个)的商家
== 有统一的订单号, 父定单
子订单
购买一个商品
粒度: 能够去表示: 对应业务的具体含义
事实可以分为3种类型
可加性:可加性事实可以通过与事实表关联的任意维度 进行汇总
半可加性:可加性事实可以通过与事实表关联的特定维度 进行汇总
10个维度== 5个维度
所售卖的商品的库存字段 可以通过地点 or 商品 进行group by ,但是其他一些的字段 没办法 group by
不可加性,一年中某几个月的商品库存进行相加,但是这是没有意义的。
不可加性:对应的字段 完全不可加的。
最典型的例子: 就是 比例类型的字段, 加起来是毫无意义的 只能求平均
事实表与维度表之间的最典型区别
数据量区别
事实表的增长速度远大于维度表的增长
订单表 与 商品维度表
退化维度
维度字段 存储/冗余 到事实表中
如果不冗余 下游使用时 肯定还会设计到多张表的join
如果冗余了 至少设计到的维度表 就不需要join 存在一定的方便性
事实表的类型:
事务事实表: 单/多事务事实表
周期快照事实表: 以一定的时间间隔去记录事实 间隔: 天 月 年?
累计快照事实表 :去表述了业务过程 开始 到结束之间的关键步骤
通常情况下, 会用多个日期字段来记录各个关键的时间点
8.2 事实表的设计原则
- 尽可能要去包含 所有与业务过程相关的
- 只需要选择 与 业务过程相关的事实
- 分解不可加性事实 ,怎么去解决? 例如 好评率 = 好评字段 / 总评论条数
- 事先申明好粒度
- 在同一张事实表当中 不能存在多种不同粒度的事实
子订单ID 父订单ID 支付金额1(子订单粒度) 支付金额2(父订单粒度)
10 1 1 3
11 1 1 3
12 1 1 3
...
==》 很可能造成数据重复计算的现象
- 事实的单位 一定要保存一致
- 对事实的null值 要进行统一的处理
可能存在的情况: null 10 == 》 null + 10 ? 一般来说用0值填充 - 使用退化维度来提高事实表的易用性
8.3 事实表的设计方法:
- 选择业务过程及确定事实表的类型
- 声明粒度
- 确定维度
- 确定事实
- 冗余维度
8.4 事务事实表
单事务事实表
概念:针对每一个业务过程去设计的一个事实表
优点:可以非常方便的针对每一个业务过程来进行独立的数据统计分析
多事务事实表
概念:不同的事实放到了同一个事实表当中 相当于 一张事实表包含了不同的业务过程,相当于表的设计对应的设计方法
设计方法:
1. 创建订单 买家付款 卖家发货 买家收货
现在要将4个业务过程放到同一个事实表中
在实际设计过程当中, 会预留出几个字段 == 来标识各个业务过程
是否创建订单 是否付款 是否发货 是否收货
Y/N
不同业务过程的事实, 使用不同事实字段进行存放
2. 不同业务过程的事实, 使用同一个事实字段进行存放 同时也需要增加业务过程字段 进行标识
商品: 商品收藏功能
商品收藏事务事实表 ----- 里面蕴含了两个过程 收藏商品/删除商品
通过增加一个 收藏事件类型字段来区分 ,是收藏 还是删除
设计方法 各自的优缺点
设计方法1缺点: 打平之后 可能存在大量空值
设计方法2可能存在问题: 同时间周期内可能会存在多条记录, 在下游使用时要注意
单vs多 区别?
从下游使用的却别来看, 单事务事实表 只有一个业务过程 理解和使用起来 比较容易
多事务事实表 包含多个业务过程 具备一定的学习和使用成本
计算存储成本; 整体上看 单和多 存储差不多
拆开来看 1张单事务事实表 vs 1张多事务事实表 , 单事务事实表的记录少
计算成本: 单 高
多 低
8.4 周期快照事实表
产生背景:
业务上在做数据分析的时候 , 可能需要一些状态的度量 = 这条数据不同时刻的一些状态
周期快照;
扩展: 快照和流水 概念
分类型:
单维度的每天快照事实表
混合维度得每天快照事实表
8.5 累计快照事实表
产生背景: 除了统计一些下单 每个月GNV 之外 还有别的业务需求
例如 1. 买家 下单 到 支付 得时长
2. 买家下单 到 卖家 发货 时常 ----- 发货超时率
3. 买家下单到收货 时长
统计事件之间得 时间间隔得需求 用累计快照事实表来进行解决
日期 订单ID· 下单时间 支付时间 确认发货时间 ...其它的事实字段
0614 1 1
0614 1 1 2
0614 1 1 2 3
上面这种不是像上面这样进行存储的















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









