







首先来看一张图:
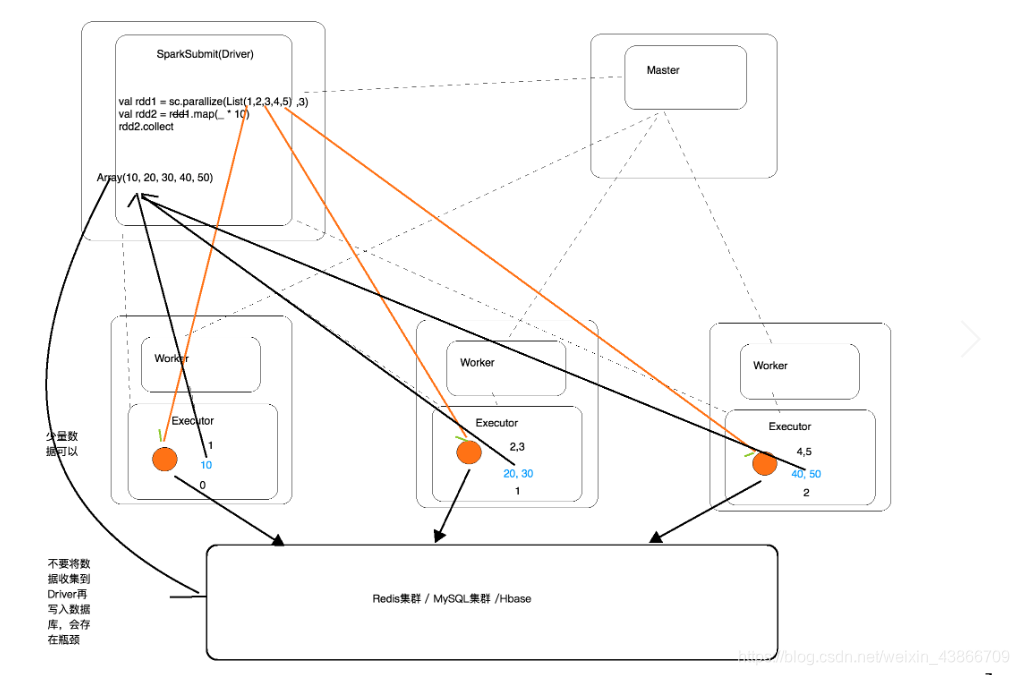
spark集群中有master节点和Worker节点,master节点负责任务调度,worker节点负责计算。
当集群启动时,worker节点会向master注册,并且定期向master发送心跳。
当我们向集群提交任务时,会启动一个进程spark-submit,这个进程也叫做driver。这个进程先要连接master,然后master会通过注册信息找到合适的worker节点去计算这个任务。这里所谓合适的worker节点,就是内存满足条件的,如果集群中没有内存满足条件的worker,那么这个任务就提交不上去了。
当找到合适的worker节点后,worker节点就会启动executor(进程),然后executor会通过master,worker节点知道driver的位置,然后和driver进行通信。
driver端会根据我们写的业务逻辑,切片,生成task,然后将这些task(是一个实例对象)分发给executor去执行,task中记录着计算逻辑,分区中记录着将来要从哪里读取数据。
executor要通过网络把数据读过去进行计算,(如果数据量很大,他会边读边计算),在executor中,task会将数据进行计算,计算的结果在worker上。
当执行collect时,driver端会将worker上的计算结果通过网络收集回去,放到Array中。(在存放到Array中的时候,会根据分区编号的顺序进行存放)
注意
在我们平时应用过程中,我们通常要把计算好的数据存放到HDFS,数据库中,如果我们都要先将数据汇总到driver端再存到数据库,那么当数据量很大的时候,driver端就会存放不下。所以我们应该直接把executor上计算好的数据保存进数据库。
在开发过程中,我们要尽可能使用foreach和foreachPartition方法,详细讲解请看博客:
https://blog.csdn.net/weixin_43866709/article/details/88667288














 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









