







概念
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量;
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中;
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
1、什么时候最快
当输入的数据可以均匀的分配到每一个桶中。
2、什么时候最慢
当输入的数据被分配到了同一个桶中。
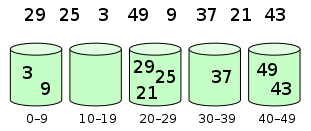
图片演示

代码演示
import java.util.Arrays;
/**
* @ClassName: Test11
* @Description: 桶排序
* @Author: wangjie
* @Date: 2020/1/9 9:31
* @Phone: 132
*/
public class Test11 {
public static void main(String[] args) throws Exception {
int[] arr = {7, 6, 13, 79, 51, 111, 58, 42, 7, 22, 31};
bucketSort(arr,6);
for (Integer i : arr) {
System.out.print(i+",");
}
}
private static int[] bucketSort(int[] arr, int bucketSize) throws Exception {
if (arr.length == 0) {
return arr;
}
int minValue = arr[0];
int maxValue = arr[0];
for (int value : arr) {
if (value < minValue) {
minValue = value;
} else if (value > maxValue) {
maxValue = value;
}
}
int bucketCount = (int) Math.floor((maxValue - minValue) / bucketSize) + 1;
int[][] buckets = new int[bucketCount][0];
// 利用映射函数将数据分配到各个桶中
for (int i = 0; i < arr.length; i++) {
int index = (int) Math.floor((arr[i] - minValue) / bucketSize);
buckets[index] = arrAppend(buckets[index], arr[i]);
}
int arrIndex = 0;
for (int[] bucket : buckets) {
if (bucket.length <= 0) {
continue;
}
// 对每个桶进行排序,这里使用了插入排序
bucket = Test11.insertSort(bucket);
for (int value : bucket) {
arr[arrIndex++] = value;
}
}
return arr;
}
/**
* 自动扩容,并保存数据
*
* @param arr
* @param value
*/
private static int[] arrAppend(int[] arr, int value) {
arr = Arrays.copyOf(arr, arr.length + 1);
arr[arr.length - 1] = value;
return arr;
}
/**
* 插入排序
* @param sourceArray
* @return
*/
private static int[] insertSort(int[] sourceArray){
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
// 从下标为1的元素开始选择合适的位置插入,因为下标为0的只有一个元素,默认是有序的
for (int i = 1; i < arr.length; i++) {
// 记录要插入的数据
int tmp = arr[i];
// 从已经排序的序列最右边的开始比较,找到比其小的数
int j = i;
while (j > 0 && tmp < arr[j - 1]) {
arr[j] = arr[j - 1];
j--;
}
// 存在比其小的数,插入
if (j != i) {
arr[j] = tmp;
}
}
return arr;
}
}
桶排序的时间复杂度
桶排序实际上只需要遍历一遍所有的待排序元素,然后依次放入指定的位置。如果加上输出排序的时间,那么需要遍历所有的桶,时间复杂度就是 O(n+m),其中,n 为待排序的元素的个数,m 为桶的个数。这是相当快速的排序算法,但是对于空间的消耗来说有点太大了。
比如对 1、10、100、1000 这四个元素排序,那么需要长度为 1001 的数组用来排序,如果是对 1、1000、100000 排序呢?我们发现,当元素的跨度范围越大时,空间的浪费就越大,即使只有几个元素,但是这个范围才是空间的大小。所以桶排序的空间复杂度是 O(m),其中 m 为桶的个数,待排序元素分布越均匀,也就是说当元素能够非常均匀地填满所有的桶时,这个空间的利用率是最好的。不过这种情况并不多见,在多数情况下,数据并不会均匀地分布。
通过上面的性能分析,桶排序的特点,速度快、简单,但是也有相应的弱点,那就是空间利用率低,如果数据跨度过大,则空间可能无法承受,或者说这些元素并不适合使用桶排序算法。
桶排序的适用场景
桶排序的适用场景非常明了,那就是在数据分布相对比较均匀或者数据跨度范围并不是很大时,排序的速度还是相当快且简单的。
但是当数据跨度过大时,这个空间消耗就会很大;如果数值的范围特别大,那么对空间消耗的代价肯定也是不切实际的,所以这个算法还有一定的局限性。同样,由于时间复杂度为 O(n+m),如果 m 比 n 大太多,则从时间上来说,性能也并不是很好。
但是实际上在使用桶排序的过程中,我们会使用类似散列表的方式去实现,这时的空间利用率会高很多,同时时间复杂度会有一定的提升,但是效率还不错。
在开发过程中,除了对一些要求特别高并且数据分布较为均匀的情况使用桶排序,还是很少使用桶排序的,所以即使桶排序很简单、很快,我们也很少使用它。
桶排序更多地被用于一些特定的环境,比如数据范围较为局限或者有一些特定的要求,比如需要通过哈希映射快速获取某些值、需要统计每个数的数量。但是这一切都需要确认数据的范围,如果范围太大,就需要巧妙地解决这个问题或者使用其他算法了。















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









