







1.介绍
MapReduce是一种用于大规模数据处理的编程模型和算法。它通过将数据拆分为多个部分,并将这些部分分发给多台计算机处理,并最后将它们的结果合并在一起,来实现并行处理。MapReduce模型简化了大规模数据处理的复杂性,并提供了高可扩展性和容错性。在本文中,我将探讨一些优化技术,并提供相应的代码案例和理论解释。
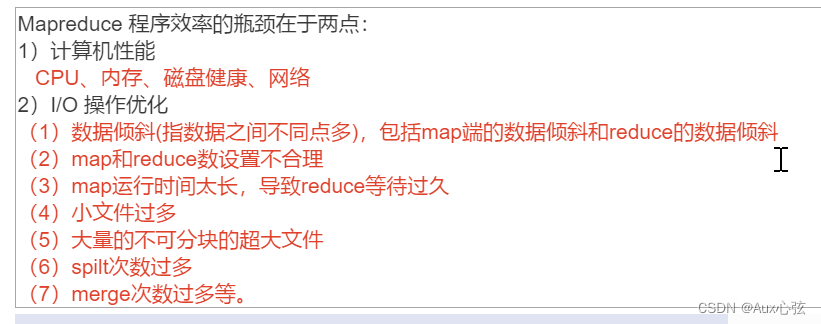
2.操作案例
1)数据本地性优化 在MapReduce中,数据本地性是指将数据分发给最接近数据的计算节点进行处理。通过减少数据的移动,可以大大减少网络通信的开销。以下是一些优化数据本地性的方法:
(1)数据分区:将输入数据划分为多个分区,并确保每个分区能够被最接近它的计算节点处理。这可以通过哈希函数或范围分区来实现。例如,如果输入数据是键值对,可以使用键的哈希值来确定数据的分区。
(2)数据复制:将数据复制到多个节点上,以确保有多个计算节点可以处理相同的数据。这有助于减少单点故障,并提高系统的容错性。但是,需要平衡数据复制的开销和容错的收益。
下面是一个示例代码,展示如何使用数据本地性优化来完成Word Count任务。
| from multiprocessing import Pool def partition_data(data, num_partitions): partitions = [[] for _ in range(num_partitions)] for item in data: partition = hash(item) % num_partitions partitions[partition].append(item) return partitions def map_function(data): word_counts = {} for word in data: if word not in word_counts: word_counts[word] = 1 else: word_counts[word] += 1 return word_counts def reduce_function(word_counts): final_counts = {} for word, counts in word_counts.items(): if word not in final_counts: final_counts[word] = counts else: final_counts[word] += counts return final_counts def word_count(data, num_partitions): partitions = partition_data(data, num_partitions) pool = Pool(processes=num_partitions) word_counts = pool.map(map_function, partitions) pool.close() pool.join() return reduce_function(word_counts) if __name__ == '__main__': data = ['apple', 'banana', 'apple', 'orange', 'banana'] num_partitions = 2 result = word_count(data, num_partitions) print(result) |
在上述代码中,首先通过partition_data函数根据数据的哈希值来将数据划分为两个分区,然后使用map_function函数在每个分区上执行map操作,计算每个单词的出现次数。最后,使用reduce_function函数对所有分区的结果进行合并。
2)压缩优化 在大规模数据处理中,数据的传输通常会占据大量的时间和带宽。为了减少数据的传输开销,可以使用压缩技术来减小数据的大小。以下是一些压缩优化的方法:
(1)压缩输出:在将中间结果传输到下一个阶段之前,对其进行压缩。这可以减少传输开销,并提高整体处理速度。常用的压缩算法包括gzip和Snappy等。
(2)数据结构优化:使用紧凑的数据结构来存储中间结果,以减少数据的大小。例如,可以使用位图或布隆过滤器来表示某些类型的数据。
下面是一个示例代码,展示如何在MapReduce中使用压缩优化来完成排序任务。
| import heapq import zlib def map_function(data): return sorted(data) def reduce_function(data): merged_data = list(heapq.merge(*data)) compressed_data = zlib.compress(''.join(merged_data).encode()) return compressed_data def sort_data(data): pool = Pool() mapped_data = pool.map(map_function, data) pool.close() pool.join() reduced_data = reduce_function(mapped_data) return reduced_data if __name__ == '__main__': data = [['apple', 'banana', 'orange'], ['cat', 'dog', 'elephant'], ['red', 'blue', 'green']] result = sort_data(data) print(result) |
在上述代码中,map_function函数对每个分区的数据进行排序,并返回排序后的结果。然后,reduce_function函数对所有分区的结果进行合并,并使用zlib库对结果进行压缩。
3)并行度优化 并行度是指同时执行的任务的数量。通过增加并行度,可以提高整体处理速度。以下是一些并行度优化的方法:
(1)动态任务调度:根据任务的运行状况,动态调整任务的并行度。例如,可以根据任务的执行时间和系统资源的利用率来动态调整任务的并发数。
(2)任务合并:将多个小的任务合并为一个大的任务,并以批处理的方式来执行。这可以减少任务的启动和停止开销,并提高系统的效率。
下面是一个示例代码,展示如何在MapReduce中使用并行度优化来完成矩阵乘法任务。
| import numpy as np def map_function(data): result = [] for row in data[0]: for col in data[1].T: result.append(np.dot(row, col)) return result def reduce_function(data): return sum(data) def matrix_multiplication(matrix1, matrix2, num_partitions): partitions = np.array_split(matrix1, num_partitions, axis=0) pool = Pool(processes=num_partitions) mapped_data = pool.map(map_function, [(partition, matrix2) for partition in partitions]) pool.close() pool.join() reduced_data = reduce_function(mapped_data) return reduced_data if __name__ == '__main__': matrix1 = np.array([[1, 2], [3, 4]]) matrix2 = np.array([[5, 6], [7, 8]]) num_partitions = 2 result = matrix_multiplication(matrix1, matrix2, num_partitions) print(result) |
在上述代码中,首先将第一个矩阵划分为两个分区,并通过map_function函数将每个分区与第二个矩阵进行乘法运算。然后,使用reduce_function函数对所有分区的结果进行合并。
总结: 本文介绍了几种优化MapReduce性能的方法,包括数据本地性优化、压缩优化和并行度优化。通过将数据划分为多个分区、使用压缩算法减小数据的大小和增加并行度等手段,可以显著提高MapReduce的处理速度和效率。通过示例代码的说明和理论解释,希望读者能够更好地理解和应用这些优化技术。



















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











