







1. 数据聚合和分组的概念
数据聚合是指将多个数据项合并为一个汇总结果的过程。在数据库中,数据聚合通常是基于某个属性对数据进行分组,并对每个组进行聚合操作,例如计算平均值、求和或计数等。
分组是数据聚合的一种方式,它将数据集按照某个属性的值进行分类,将具有相同属性值的数据项放置在同一个组中。分组可以帮助我们更好地理解数据的分布情况,以及对数据进行更细粒度的分析和处理。
2. ClickHouse中的数据聚合和分组
ClickHouse是一个高性能、列式存储的分布式数据库,它内置了丰富的聚合和分组功能,可以帮助我们高效地进行数据分析和处理。下面将详细介绍ClickHouse中的数据聚合和分组的用法。
2.1 GROUP BY子句
在ClickHouse中,使用GROUP BY子句可以对数据进行分组。GROUP BY子句后面跟着一个或多个属性,表示按照这些属性的值进行分组。例如,我们有一个包含用户信息的表user,包括user_id、name和age等字段,现在我们要按照age对用户进行分组,可以使用如下SQL语句:
SELECT age, COUNT(*)
FROM user
GROUP BY age
上述SQL语句中,我们使用GROUP BY age将用户按照年龄进行分组,并使用COUNT(*)计算每个年龄分组中的用户数量。通过执行上述SQL语句,我们可以得到每个年龄分组的用户数量。
2.2 聚合函数
在ClickHouse中,可以使用各种聚合函数对分组后的数据进行计算。常用的聚合函数包括COUNT、SUM、AVG、MIN和MAX等。以下是一些常用的聚合函数的使用示例:
- COUNT:计算分组中的数据项数量。
SELECT age, COUNT(*)
FROM user
GROUP BY age
- SUM:计算分组中某个字段的总和。
SELECT age, SUM(salary)
FROM user
GROUP BY age
- AVG:计算分组中某个字段的平均值。
SELECT age, AVG(salary)
FROM user
GROUP BY age
- MIN:计算分组中某个字段的最小值。
SELECT age, MIN(salary)
FROM user
GROUP BY age
- MAX:计算分组中某个字段的最大值。
SELECT age, MAX(salary)
FROM user
GROUP BY age
2.3 HAVING子句
在ClickHouse中,可以使用HAVING子句对分组后的数据进行筛选。HAVING子句类似于WHERE子句,但是它是在分组后进行筛选。以下是一个使用HAVING子句的示例:
SELECT age, AVG(salary)
FROM user
GROUP BY age
HAVING AVG(salary) > 5000
上述SQL语句中,我们使用HAVING子句筛选出平均工资大于5000的年龄分组。
2.4 WITH ROLLUP子句
ClickHouse还提供了WITH ROLLUP子句,用于在GROUP BY子句的结果中添加小计和总计。以下是一个使用WITH ROLLUP子句的示例:
SELECT age, gender, COUNT(*)
FROM user
GROUP BY age, gender WITH ROLLUP
上述SQL语句中,我们使用WITH ROLLUP子句在年龄和性别两个属性上进行分组,并计算每个分组的用户数量。同时,还会生成每个分组的小计和总计。
3. ClickHouse数据聚合和分组的性能优化
在处理大规模数据集时,ClickHouse提供了一些性能优化的技巧,以加快数据聚合和分组的速度。下面介绍一些常用的性能优化方法:
3.1 使用合适的数据类型
选择合适的数据类型可以减少存储空间的占用和提高计算速度。在ClickHouse中,有多种数据类型可供选择,例如Int32、Float64和String等。根据实际情况,选择最适合数据的数据类型可以提高性能。
3.2 使用合适的数据分布键
在ClickHouse中,可以使用数据分布键来分布数据到不同的节点上。合理选择数据分布键可以提高查询性能。数据分布键应该尽量选择经常被用于分组和聚合的字段。
3.3 使用合适的分区键
分区是ClickHouse中的一种数据组织方式,可以将数据按照某个属性的值进行分区存储。合理选择分区键可以提高查询性能。分区键应该选择经常用于查询和过滤的字段。
3.4 使用合适的索引
索引可以加快数据的查找和过滤操作。在ClickHouse中,可以创建索引来加速对特定字段的查询。合理创建索引可以提高数据聚合和分组的性能。
4. 完整代码案例
以下是一个完整的ClickHouse数据聚合和分组的代码案例:
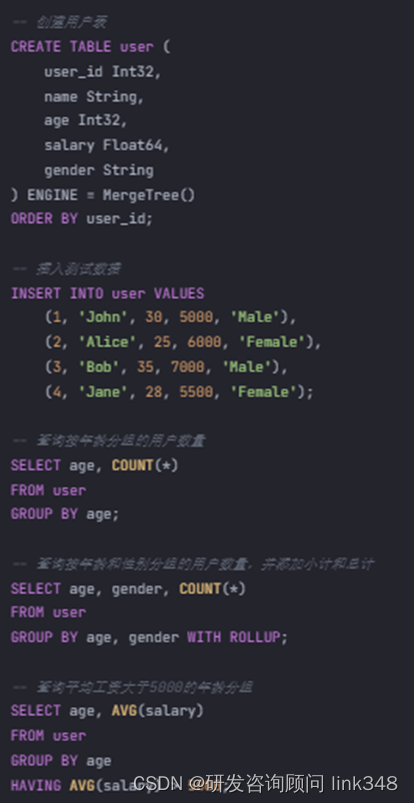
| -- 创建用户表 CREATE TABLE user ( user_id Int32, name String, age Int32, salary Float64, gender String ) ENGINE = MergeTree() ORDER BY user_id; -- 插入测试数据 INSERT INTO user VALUES (1, 'John', 30, 5000, 'Male'), (2, 'Alice', 25, 6000, 'Female'), (3, 'Bob', 35, 7000, 'Male'), (4, 'Jane', 28, 5500, 'Female'); -- 查询按年龄分组的用户数量 SELECT age, COUNT(*) FROM user GROUP BY age; -- 查询按年龄和性别分组的用户数量,并添加小计和总计 SELECT age, gender, COUNT(*) FROM user GROUP BY age, gender WITH ROLLUP; -- 查询平均工资大于5000的年龄分组 SELECT age, AVG(salary) FROM user GROUP BY age HAVING AVG(salary) > 5000; |
















 6506
6506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











