






省份提取
1、LogMapper.java
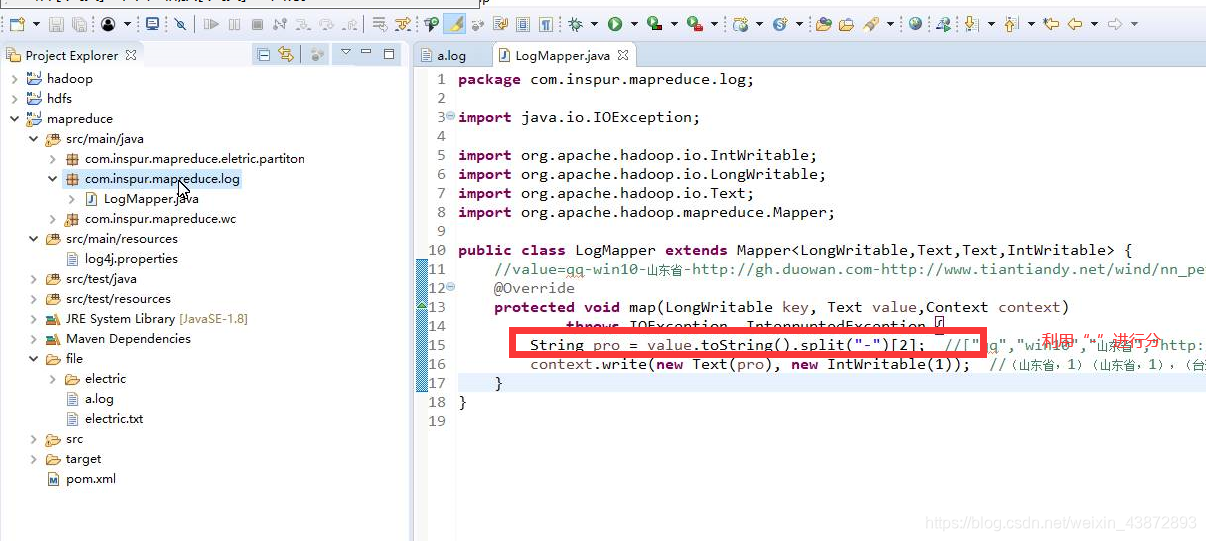
2、LogReducer.java
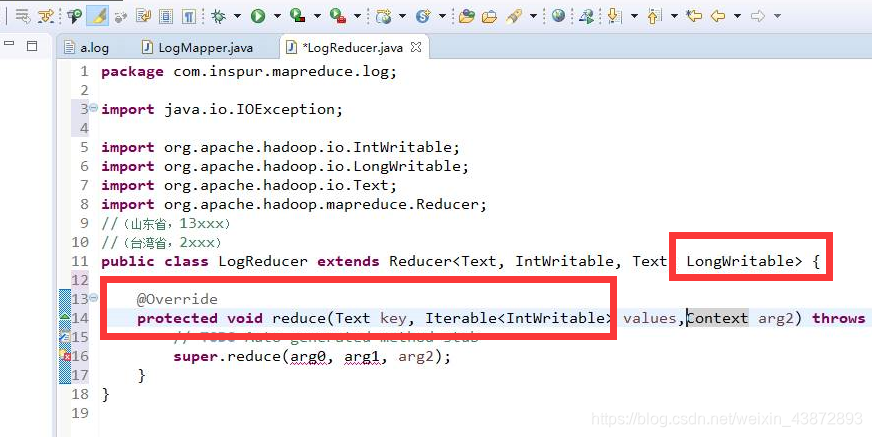
重写reduce方法,
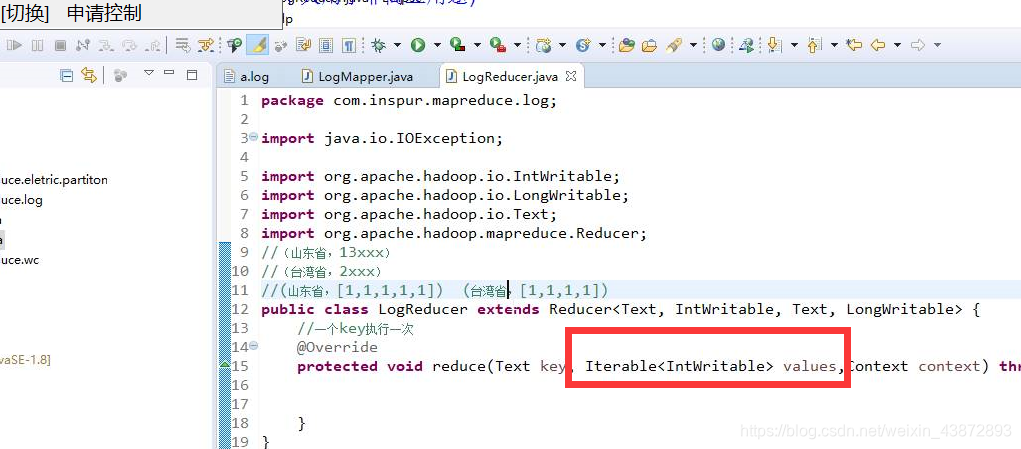
进入到reduce的数据是(山东省,【1,1,1,1,】,(台湾省,【1,1,1,1】))
其中values就是数组
将取到的值放到sum上
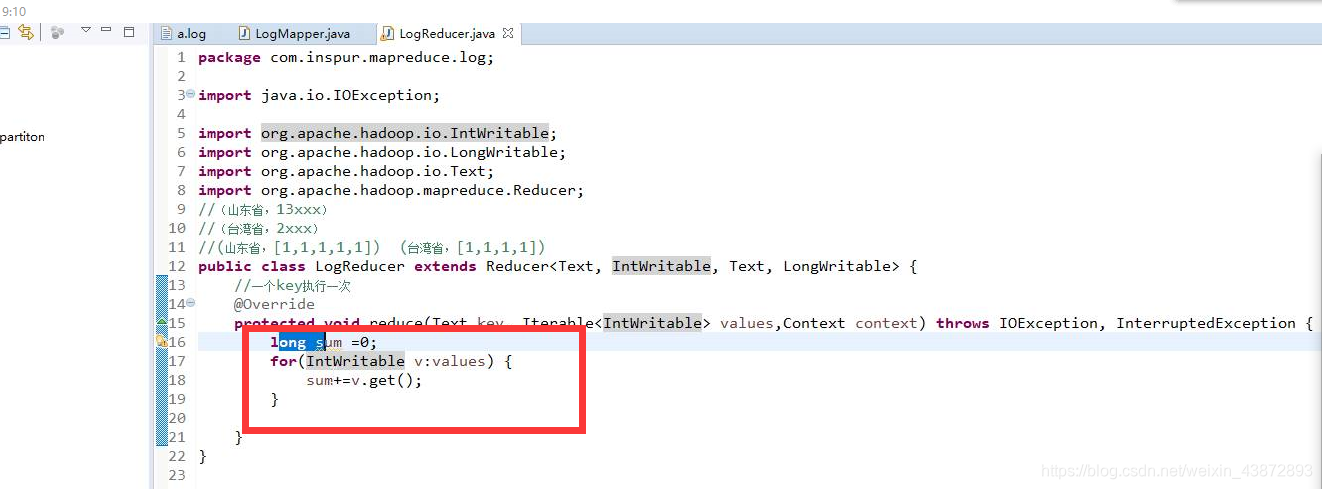
通过intWritable改成int类型
3、每一个key_value对进行一次
4、开发LogApp.java
main方法

5、当然也可以放到数据库中,以扇形图等的形式进行展示

省份提取
1、LogMapper.java
2、LogReducer.java
重写reduce方法,
进入到reduce的数据是(山东省,【1,1,1,1,】,(台湾省,【1,1,1,1】))
其中values就是数组
将取到的值放到sum上
通过intWritable改成int类型
3、每一个key_value对进行一次
4、开发LogApp.java
main方法
5、当然也可以放到数据库中,以扇形图等的形式进行展示
 1235
1235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























