







 本文详细介绍了Hadoop分布式文件系统HDFS的存储机制,包括其适用场景、特点、文件块大小设定依据以及HDFS的Shell操作、客户端API操作、数据流过程。此外,还探讨了NameNode和DataNode的工作机制,如NameNode的元数据管理、CheckPoint触发条件、故障处理和安全模式。最后,文章提到了HDFS的高可用性、多目录配置和DataNode的管理策略。
本文详细介绍了Hadoop分布式文件系统HDFS的存储机制,包括其适用场景、特点、文件块大小设定依据以及HDFS的Shell操作、客户端API操作、数据流过程。此外,还探讨了NameNode和DataNode的工作机制,如NameNode的元数据管理、CheckPoint触发条件、故障处理和安全模式。最后,文章提到了HDFS的高可用性、多目录配置和DataNode的管理策略。
HDFS(存储)
概述
HDFS背景
大数据的背景下,单台服务器的操作系统无法管理所有的海量数据,我们就需要将数据分开放在多台主机的磁盘中,但是这样不便于管理和维护,我们迫切需要一种系统能够同时管理多台机器上的文集,分布式文件管理系统随之诞生,HDFS就是其中之一。
HDFS定义
HDFS(Hadoop Distributed File System),是一个文件系统,比如Windows上使用的NTFS,也是一种文件系统。用于存储文件,通过目录树来定位文件;其次他是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的适用/不适用场景
一次性写入,不支持修改。
HDFS特点:
- 高容错性、可构建在廉价机器上
- 适合批处理
- 适合大数据处理
- 流式文件访问
HDFS局限:
- 不支持低延迟访问
- 不适合小文件存储
- 不支持并发写入
- 不支持修改
HDFS优点
-
高容错性
具体实现:
数据自动保存多个(默认三个)副本,以此提高容错性。
且当某一个副本丢失,他会自动恢复,以保证副本数量
-
适合处理大数据
- 可以处理的GB、TB、PB规模的数据
- 能够处理百万规模以上的文件
-
可以构建在廉价机器上
通过副本提高可靠性
HDFS缺点
- 不适合低延时的数据访问
- 无法高效对大量的小文件进行存储
- 因为不管是存大文件存储小文件,都会占用相同的NameNode大量的内存来存储目录和块信息。相比较下存储大文件空间利用率更高
- 小文件的存储寻址时间会超过读取时间
- 不支持并发写入、文件随机修改
- 不允许多个线程同时写入
- 近支持数据append,不支持修改
HDFS架构
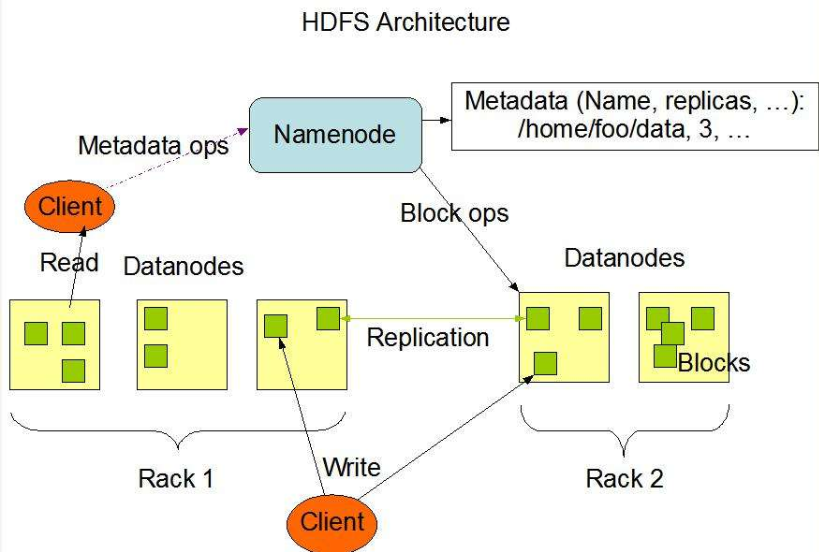
NameNode:Master,一个主管、管理者身份
- 管理HDFS命名空间
- 配置副本策略
- 管理数据块(Blocks)映射信息
- 处理客户端读写请求
DataNode:Slave,一个执行者身份,由NameNode下达命令,DataNoda执行
- 存储实际的数据块
- 执行数据的读/写操作
Client
- 文件切分。文件数据写入的适合,先将文件切分成一个个Block,然后进行上传写入。
- 和NameNode交互,获取文件位置信息
- 和DataNode交互,读取或写入数据
- 提供一些命令管理HDFS,例如NameNode的格式化
- 也可以使用命令来访问HDFS,例如对HDFS的增删改查
Secondary NameNode:并非NameNode的热备份,当NameNode故障,它并不能立即代替NameNode提供服务
- 辅助NameNode,为其分担工作量,例如定期合并Fsimage和Edits,并推送给NameNode
- 在紧急情况下,可以辅助NameNode进行恢复。
HDFS文件块大小
HDFS中的文件在物理空间中是以块(Block)形式存储,默认的块大小是128MB,可以在hdfs-default.xml中查看dfs.blocksize,旧版本(1.x)中是64MB

为什么128MB?由什么决定?
假设对Block的寻址时间是10ms,那么按照寻址时间是传输时间(数据写入时间)是1%为最佳状态,传输的时间就是1s,我们现在的机械硬盘读写速度一般稳定在80~120MB/s的范围内,那么也就说当我们寻找到Block的地址后,传输一秒的数据大小最接近块大小是最合适的,也就100MB左右,当然以上数据都是粗略数据,并没有那么精确。
所以说块的大小,与硬盘的读写速度相关联
为什么块的大小不能太小,也不能太大?
块大小,存储/读取一个文件需要找到多个块,程序就要不断寻址块进行存储/读取。
块太大,磁盘传输数据耗时长。
HDFS的Shell操作
基本命令:hdfs dfs ...或者Hadoop fs
常用命令实操
-
启动集群
start-dfs.sh start-yarn.sh -
命令帮助 -help
hadoop -help command -
基本命令
-ls:显示目录信息-mkdir: 创建目录-moveFromLocal: 从本地剪切粘贴-copyFromLocal: 从本地复制粘贴-appendToFile: 追加一个文件到已存在文件的末尾-cat: 查看文件内容-chgrp-chmod-chown: 修改所有组、所有者、文件权限-copyToLocal: 从HDFS拷贝到本地-cp: HDFS中文件拷贝复制-mv: HDFS中文件移动-get: 等同于copyToLocal-getmerge: 合并下载多个文件-put: 等同于copyFromLocal-tail: 显示一个文件的末尾,-f动态监视一个文件-rm: 删除文件、目录-du: 统计文件大小- -s 仅显示总计,只列出最后加总的值。
- -h 以K,M,G为单位,提高信息的可读性。
-setrep: 设置HDFS中文件的副本数量
HDFS客户端操作
环境准备
windows Hadoop客户端环境搭建
- 将Hadoop解压缩到环境文件夹中
- 添加环境变量HADOOP_HOME,变量值为Hadoop的根目录
- PATH中添加%HADOOP_HOME%\bin
- 重启,使用
hadoop version测试验证
项目搭建
Maven构建项目,并导入依赖,注意Hadoop组件的版本要和环境的版本一致
pom.xml
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>
编写Log4j的配置文件:log4j.properties
log4j.rootLogger = INFO ,stdout
### 输出到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %d %p [%c]- %m%n
### 输出到日志文件 ###
log4j.appender.file = org.apache.log4j.FileAppender
log4j.appender.file.File = target/spring.log
log4j.appender.file.layout = org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern = %d %p [%c]- %m%n
Java代码操作HDFS
public class HDFSClient {
public static void main(String[] args) throws IOException {
// 配置信息
Configuration conf = new Configuration();
// 配置NameNode的地址 host文件中配置了hadoop102的映射地址是192.168.52.202
conf.set("fs.defaultFs", "hdfs://hadoop102:9000");
// 文件系统对象
FileSystem fs = FileSystem.get(conf);
// 创建一个目录
fs.mkdirs(new Path("/test/hello"));
// 关闭资源
fs.close();
System.out.println("over");
}
}
代码解释:
- 第一步是我们要获取一个FileSystem对象(org.apache.hadoop.fs包下的!!)
- 获取这个兑用需要一个Configuration对象(也是Hadoop包下的!),也就是配置信息。
- 使用FileSystem对象进行相应的操作
- 关闭文件系统资源
这样就可以了吗?!NoNoNoNo!
既然是要操作远程的文件系统,就需要指明NameNode的地址,记得我们在
core-site.xml中配置的第一条配置项fs.defaultFS就是指明NameNode的地址的。所以为我们创建的Configuration对象,set这条信息。启动!

此时运行还是会报错:

这个错误可以忽略,因为我们操作的远程Linux上的HDFS,真正要解决的问题是这个:

操作控制异常,由于我们使用Windows去连接使用Linux上的HDFS适合,用户名并不一致,所以在我们要在运行参数中设置一个参数-DHADOOP_USER_NAME=sakura

然后重新运行,再刷新HDFS的网页,就可以看到新创建的目录啦!

这样的做法显得有点麻烦,能不能用代码一步搞定呢?!答案是:可以!
使用FileSystem.get(URI uri, Configuration conf, String user),就可以将NameNode、UserName一步搞定!
public class HDFSClient {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
// 配置信息
Configuration conf = new Configuration();
// 文件系统对象
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), conf, "sakura" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









