






什么是垃圾
垃圾是内存中没有任何引用指向它,并且没有引用的对象无法使用,所以就可以认为这个对象是垃圾,需要被回收释放其占用的内存空间。
垃圾定位
- 1、引用计数法(RefrenceCount)
堆中每个对象实例都有一个引用计数,每当有一个引用指向它,计数器加1,引用失效,计数器减1,当计数器为0时,这个对象就是垃圾。简单高效。
缺点是:无法解决对象之间相互循环引用的问题。 - 2、根搜索(Root Seaching)
GC Roots 的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的。此算法解决了循环引用的问题。
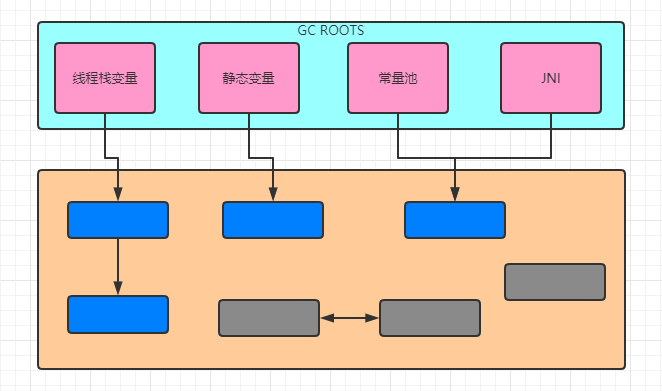
- 虚拟机栈(栈桢中的本地变量表)中的引用的对象
- 方法区中的类静态属性引用的对象
- 方法区中的常量引用的对象
- 本地方法栈中JNI(Native方法)的引用的对象
常用的垃圾回收算法
-
1、标记清除(Mark Sweep)

标记清除从根集合进行两次扫描,首先对存活的对象进行标记,在标记完成后统一回收所有未被标记的对象。
存活对象比较多的情况下使用,多用于老年代。需要扫描两次,效率比较低,容易产生碎片。 -
2、拷贝(Copying)
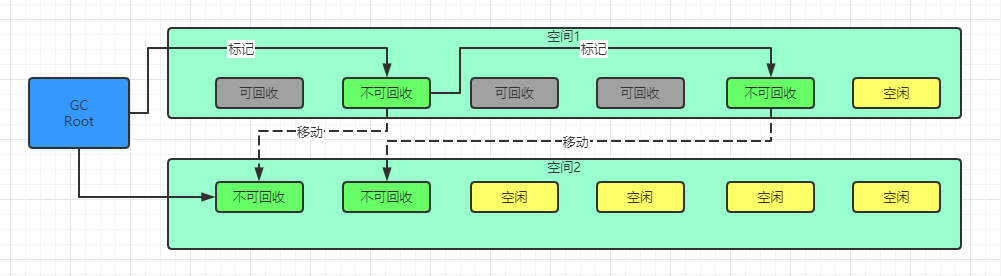
拷贝算法将可用内存按容量划分为大小相等的两块,从根集合进行一次扫描,对存活的对象进行标记,然后移动到复制另外一块内存空间中,然后再把已使用过的内存空间清理掉。
存活对象比较少的情况下使用,只扫描一次,没有内存碎片,多用于年轻代。造成空间浪费,需要调整对象的引用。 -
3、标记整理(Mark-Compact)
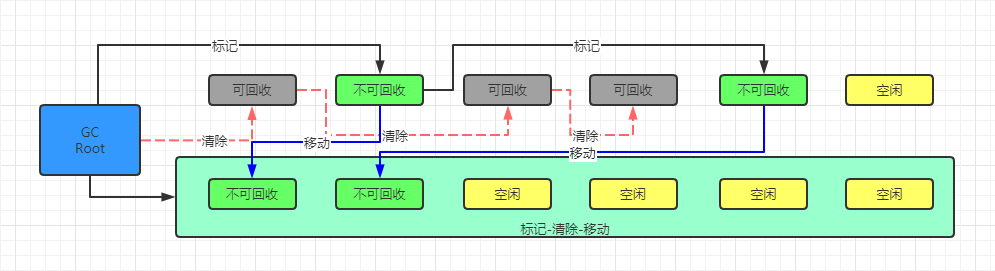
标记整理,标记过程仍然与“标记-清除”算法一样,首先对存活的对象进行标记,其次不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
不会产生内存碎片,不会造成空间浪费,多用于老年代。需要扫描两次,需要调整对象的引用,效率比较低。
Heap内存逻辑分区
堆大小 = 新生代 + 老年代。其中,堆的大小可以通过参数 –Xms、-Xmx 指定。
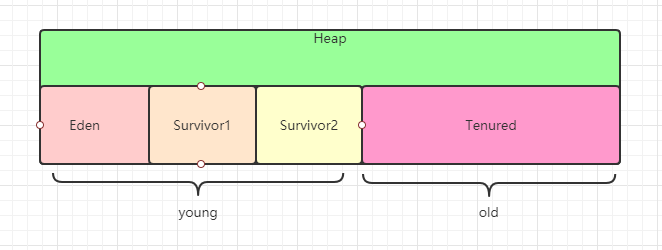
- 1、新生代
Eden + Survivor- eden:对象最初创建的区域
- survivor:eden幸存下来的对象所在的区域。
- 2、老年代
主要存放程序中年龄较大和需要占用大量内存空间的对象
MinorGC/Young GC
当Eden区内存不足的时候,虚拟机将进行一次MinorGC。Survivor区内存不足不会触发MinorGC。MinorGC采用复制算法。首先,把Eden和Survivor1区域中存活的对象复制到Survivor2区域,同时把这些对象的年龄+1(默认情况下15岁就直接送到老年代了,晋升老年代的阈值可以通过 -XX:MaxTenuringThreshold 设置);然后,清空Eden和Survivor1中的对象;
MajorGC/FullGC
Major GC 是清理永久代。Full GC 是清理整个堆空间—包括年轻代和永久代。
- 每次晋升到老年代的对象平均大小>老年代剩余空间;
- MinorGC后存活的对象超过了老年代剩余空间
- 堆内存分配很大的对象
- CMS GC异常:
promotion failed:MinorGC时,survivor空间放不下,对象只能放入老年代,而老年代也放不下造成;
concurrent mode failure:GC时,同时有对象要放入老年代,而老年代空间不足造成
JVM常用的垃圾回收器
- Serial收集器(复制算法): 新生代单线程收集器(stw),标记和清理都是单线程,优点是简单高效;
- ParNew收集器 (复制算法): 新生代收并行集器(stw),实际上是Serial收集器的多线程 版本,在多核CPU环境下有着比Serial更好的表现;
- Parallel Scavenge收集器 (复制算法): 新生代并行收集器(stw),追求高吞吐量,高效 利用 CPU。吞吐量 = 用户线程时间/(用户线程时间+GC线程时间),高吞吐量可以高 效率的利用CPU时间,尽快完成程序的运算任务,适合后台应用等对交互相应要求不 高的场景;
- Serial Old收集器 (标记-整理算法): 老年代单线程收集器(stw),Serial收集器的老年 代版本;
- Parallel Old收集器 (标记-整理算法): 老年代并行收集器(stw),吞吐量优先, Parallel Scavenge收集器的老年代版本;
- CMS(Concurrent Mark Sweep)收集器(标记-清除算法): 老年代并发收集器,以获取最短回收停顿时间为目标的收集器。(初始标记,并发标记,重新标记,并发清除)














 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









