







目录
1 概念
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据.
2 数据模型
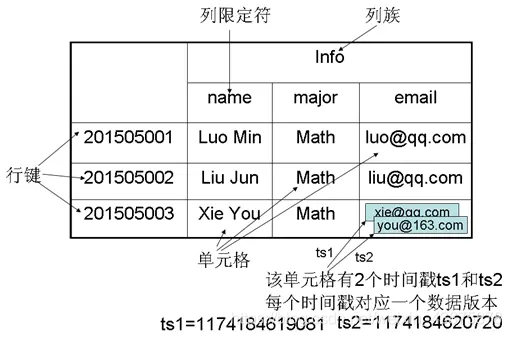
①表:HBase采用表来组织数据,表由行和列组成,列划分为若干列族.
②行:每个HBase表都由若干行组成,每个行由行键(row key)来标识.
③列族:一个HBase表被分组成许多"列族"(Column Family)的集合,它是基本的访问控制单元.
④列限定符:列族里的数据通过限定符(或列)来定位.
⑤单元格:在HBase表中,通过行、列族和列限定符确定一个"单元格"(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[].
⑥时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引.
3 使用
3.1 访问
访问:hbase shell.
退出:quit.
帮助:help.
查看HBase服务器状态:status.
查看HBase版本:version.
日志:/var/log/hbase/hbase-hbase-master-node02.out
进程:HMaster,HMaster
页面:${ip}:16010/master-status














 2364
2364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









