









leetcode 3081
题目

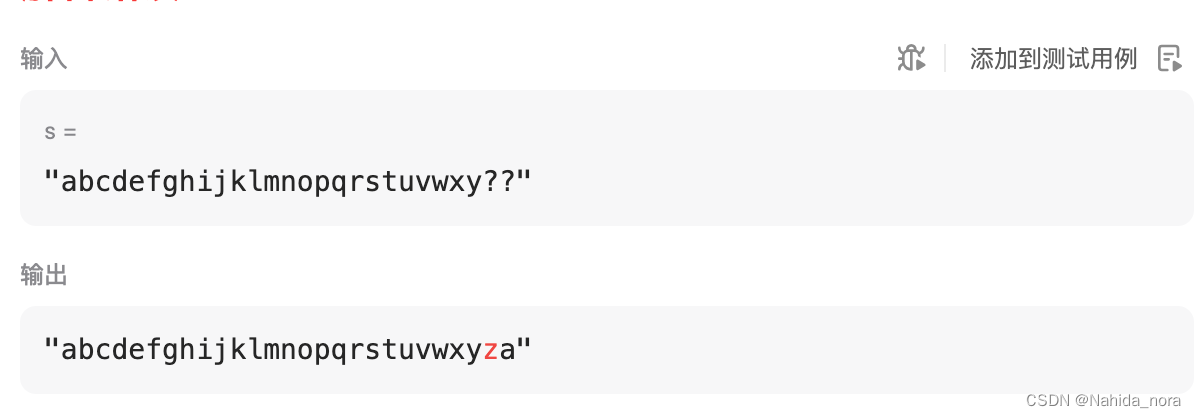
例子

思路
使用minheap 记录字符出现频次
代码
class Solution {
public:
string minimizeStringValue(string s) {
int freq[26]{};
for(char c: s){
if(c != '?'){
freq[c-'a']++;
}
}
//std::greater<> 比较器比较 pair 对象时,默认比较规则是先比较第一个元素
priority_queue<pair<int, char>, vector<pair<int, char>>, greater<>> minheap;
for(int i=0; i<26; i++){
minheap.push({freq[i], 'a'+i});
}
int q = ranges::count(s, '?');
string tmp(q,0);
for(int i =0; i<q; i++){
auto [f,c] = minheap.top();
minheap.pop();
tmp[i] = c;
// c代替了'?', 更新minheap
minheap.push({f+1,c});
}
for(int i=0, j=0; i<s.size(); i++){
if(s[i] == '?'){
s[i] = tmp[j];
j++;
}
}
return s;
}
};
分析

priority_queue
要使用 pair 类型的 priority_queue 声明最小堆,可以通过指定自定义的比较器来实现。在比较器中,我们需要定义如何比较两个 pair 对象,以确保最小的元素在队首。
以下是一个示例代码,演示如何声明一个 pair 类型的 priority_queue,并使用自定义比较器来实现最小堆:
#include <iostream>
#include <queue>
#include <utility>
// 自定义比较器,用于实现最小堆
struct ComparePairs {
bool operator() (const std::pair<int, int>& p1, const std::pair<int, int>& p2) {
return p1.first > p2.first; // 按照 pair 的第一个元素升序排序
}
};
int main() {
std::priority_queue<std::pair<int, int>, std::vector<std::pair<int, int>>, ComparePairs> minHeap;
minHeap.push({3, 1});
minHeap.push({1, 2});
minHeap.push({5, 3});
minHeap.push({2, 4});
std::cout << "Min Heap elements: ";
while (!minHeap.empty()) {
std::pair<int, int> topPair = minHeap.top();
std::cout << "(" << topPair.first << ", " << topPair.second << ") ";
minHeap.pop();
}
return 0;
}
在上面的代码中,我们首先定义了一个自定义的比较器 ComparePairs,用于比较两个 pair 对象。在比较器中,我们按照 pair 的第一个元素来进行升序排序,以实现最小堆。
然后,我们声明了一个 pair<int, int> 类型的 priority_queue,并指定了底层容器为 vector<pair<int, int>> 和比较器为 ComparePairs,从而创建了一个最小堆。
接着,我们向最小堆中插入一些 pair 对象,并通过 top 和 pop 方法访问和删除堆顶元素,最终打印出堆中的元素。
在上面的示例代码中,定义了一个自定义的比较器 ComparePairs,其中重载了函数调用运算符 operator()。在使用 priority_queue 时,当需要比较两个元素的大小以确定它们在堆中的顺序时,会调用这个比较器中重载的 operator() 函数。
在这个例子中,ComparePairs 结构体中的 operator() 函数定义了如何比较两个 pair<int, int> 对象。具体来说,我们在函数中比较了两个 pair 对象的第一个元素,以确保最小的元素在队首。这个比较逻辑决定了在 priority_queue 中元素的排序顺序。
当创建 priority_queue 对象时,通过指定自定义的比较器 ComparePairs,priority_queue 在需要比较两个元素时会调用该比较器中的 operator() 函数。这样就确保了在插入、弹出或访问元素时,元素会按照我们定义的比较逻辑进行排序。
greater
std::greater<> 是一个函数对象,用于实现严格的降序排序。它定义在 <functional> 头文件中,并可以用作比较器,用于比较两个元素并确定它们的顺序。
当使用 std::greater<> 作为比较器时,它会按照严格的降序排列元素,即较大的元素会排在前面。这在实现最小堆的 priority_queue 中非常有用,因为最小堆要求堆顶元素是最小的。
std::greater<> 是一个模板类,可以根据需要指定元素的类型。例如,std::greater<int> 用于比较整数类型的元素,std::greater<double> 用于比较双精度浮点数类型的元素。
在使用 std::greater<> 时,通常会将其作为模板参数传递给容器或算法,以指定降序排序的方式。除了在 priority_queue 中使用外,std::greater<> 还可以在 std::sort 等算法中用作比较器来实现降序排序。
std::greater<> 是一个非常方便的函数对象,用于实现降序排序。通过使用它,我们可以轻松地按照降序排列元素,而无需自定义比较器。
除了 greater 之外,C++ 标准库中还提供了其他一些类似的函数对象,用于比较元素大小或实现自定义的比较逻辑。一些常用的函数对象包括:
less:用于升序排序,类似于std::less<T>,在priority_queue中可以用于实现最小堆。greater_equal:用于大于等于比较,类似于std::greater_equal<T>,可以用于实现最大堆。less_equal:用于小于等于比较,类似于std::less_equal<T>,可以用于实现最小堆。not_equal_to:用于不等于比较,类似于std::not_equal_to<T>,可以用于实现特定的排序逻辑。
这些函数对象都定义在 <functional> 头文件中,并且可以在 priority_queue 的声明中作为比较器来使用,以实现不同的排序方式。
除了标准库提供的函数对象外,您也可以自定义比较器,通过重载函数调用运算符 operator() 来实现特定的比较逻辑,从而创建最大堆、最小堆或其他自定义的排序方式。
希望这个回答能够帮助您了解除了 greater 外还有哪些类似的函数对象。如果您有任何其他问题或需要进一步解释,请随时告诉我。我随时准备帮助您。
最小堆和最大堆
最大堆(Max Heap)和最小堆(Min Heap)是堆(Heap)数据结构的两种常见形式,它们都是完全二叉树,并且具有一些特定的性质:
-
最大堆(Max Heap):
- 在最大堆中,对于任意节点
i,其父节点的值大于等于节点i的值。 - 最大堆中的根节点(堆顶元素)始终是整个堆中的最大元素。
- 最大堆通常用于实现优先队列,以便在常数时间内获取和删除最大元素。
- 在最大堆中,对于任意节点
-
最小堆(Min Heap):
- 在最小堆中,对于任意节点
i,其父节点的值小于等于节点i的值。 - 最小堆中的根节点(堆顶元素)始终是整个堆中的最小元素。
- 最小堆通常用于实现优先队列,以便在常数时间内获取和删除最小元素。
- 在最小堆中,对于任意节点
堆的插入和删除操作会保持堆的性质不变,即插入元素时会保持堆的有序性,删除元素时会重新调整堆以满足堆的性质。
在 C++ 中,可以使用 std::priority_queue 来实现堆,通过指定合适的比较器(如 std::less 或 std::greater)可以实现最小堆或最大堆。堆的操作时间复杂度为 O(log n),其中 n 是堆中元素的数量。
总结来说,最大堆和最小堆都是一种特殊的二叉树结构,用于高效地维护一组元素中的最大值或最小值。它们在算法和数据结构中有着广泛的应用,例如在排序算法、图算法和优先队列等领域。希望这个简要介绍对您有帮助。如果您有任何进一步的问题,请随时告诉我。我很乐意帮助您。














 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









