







前言:去年备研学习计算机组成原理的一些笔记,因为主要为了应付考试,记得比较仓促,仅供参考。
文章目录
流水线技术与指令级并行
流水线处理
并行处理技术
通常提高指令执行速度的途径有如下三种:
- 提高处理机的工作主频。
- 采用更好的算法和设计更好的功能部件。
- 多条指令并行执行,称为指令级并行技术。
可以从两个方面来开发处理机内部的并行性:
-
空间并行性
即在一个处理机内设置多个独立的操作部件,并让这些操作部件并行工作,这种处理机称为多操作部件处理机或超标量处理机; -
时间并行性
就是采用流水线技术。流水线技术是一种非常经济、对提高处理机的运算速度非常有效的技术。采用流水线技术可以不增加硬件或只需要增加少量硬件就能够把处理机的运算速度提高几倍,它是目前使用非常普遍的一种并行处理方式。
基本思想
并行性的两种含义:
- 同时性:同一时刻
- 并发性:同一时间间隔
并行处理技术的三种形式: - 时间并行:时间重叠,流水
- 空间并行:资源重复
- 时间并行+空间并行:超标量流水
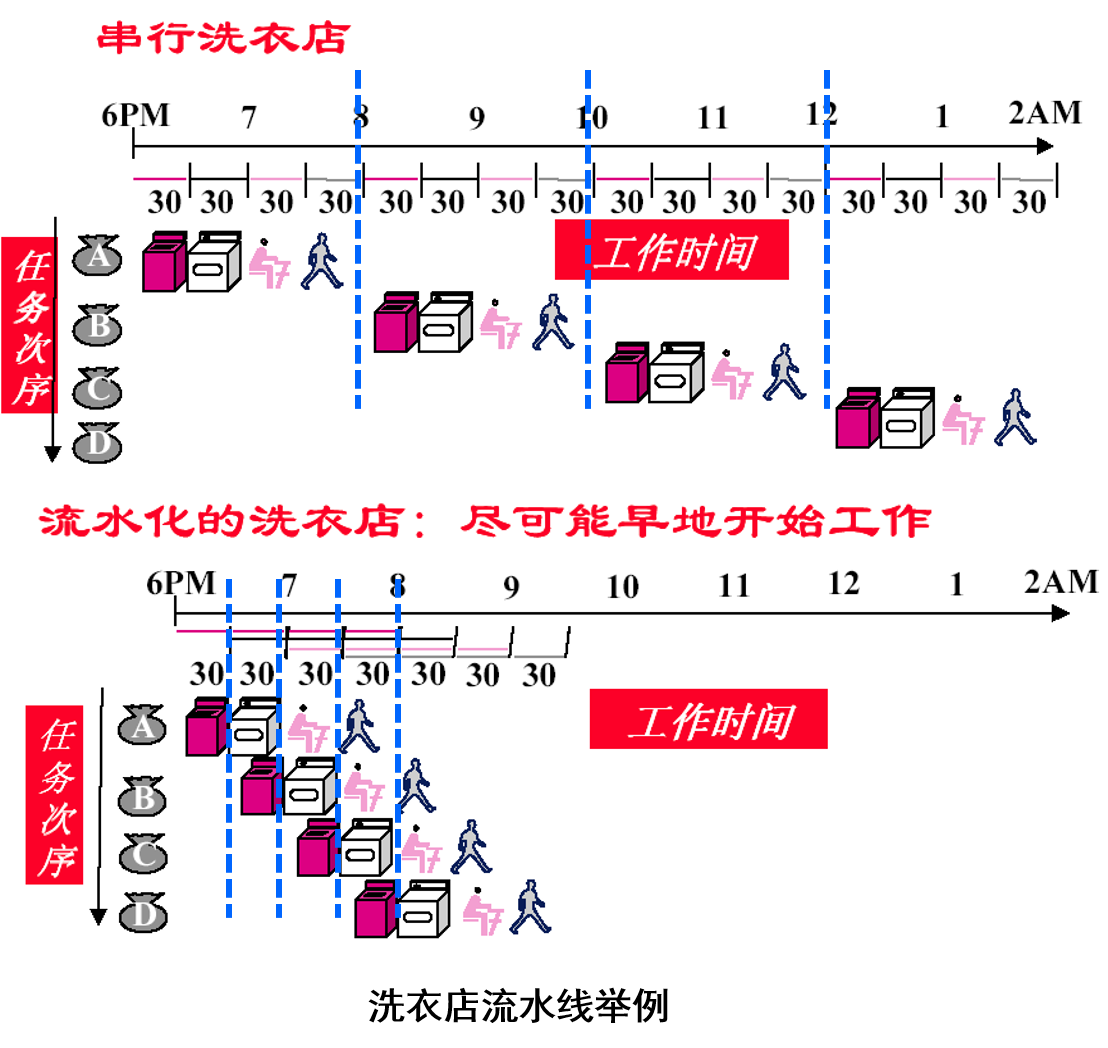
若将一重复的处理过程分解为若干子过程,每个子过程都可在专用设备构成的流水线功能段上实现,并可与其它子过程同时执行,这种技术称为流水技术。
流水线的一般结构
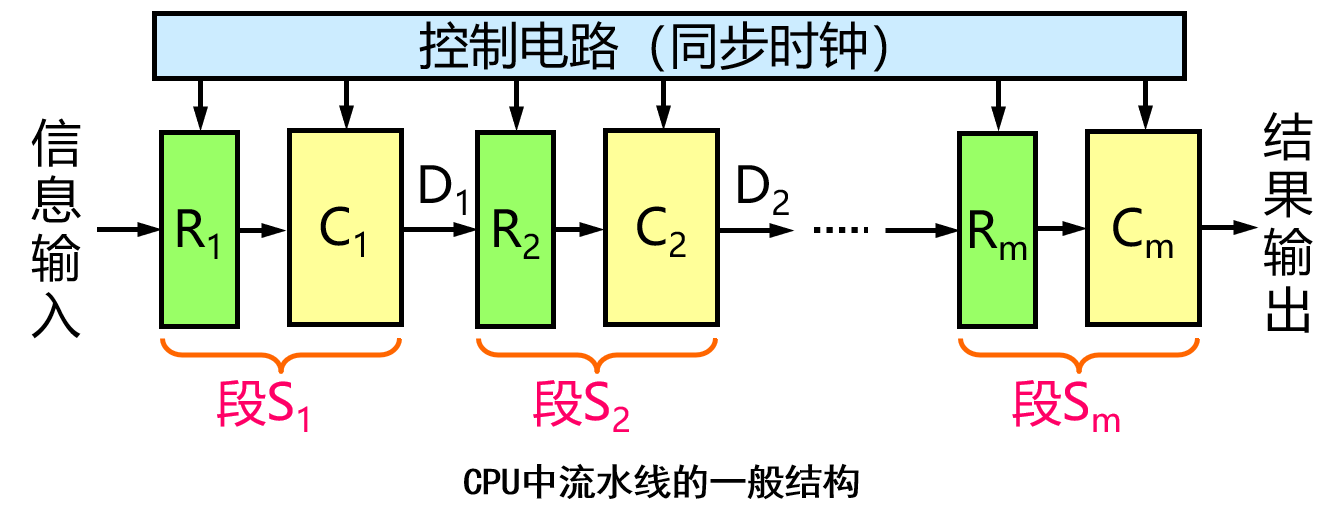
结论
- 流水过程由多个相联系的子过程组成,每个子过程由专用的功能设备实现,每个子过程称为流水线的 “级”或“段”。“级”数称为流水线的“深度”;
- 流水线需要有 “通过时间”,在此之后流水过程才进入稳定工作状态(前面洗衣店例子:每个设备都有人用),每一个时钟周期(拍)流出一个结果;
- 流水线不能缩短单个任务的响应时间,但可以提高吞吐率;
- 流水线速度受限于最慢流水线段的运行速度,所以,各个功能段所需时间应尽量相等;
- 流水技术适合于大量重复的处理过程,只有流水线的输入能连续地提供任务,流水线的效率才能充分发挥。
- 流水线中多个任务是并行处理的。
流水线类型
-
按流水线位于计算机系统的层次划分:
- 系统级流水线/宏流水线:在多(计算)机系统中由多个处理机串行构成的流水线。
- 处理器级流水线
- 部件级流水线
-
按流水线功能的强弱划分:
- 单功能流水线
一个流水线只能实现单一任务 - 多功能流水线
一个流水线可以实现多个任务- 静态流水线
一种任务执行完了,才能执行另一种任务(举例:正在造汽车,现在有造轮船的任务到来,必须等待汽车全部造完,才能开始造轮船) - 动态流水线
- 多种任务可交错进行(举例:正在造汽车,现在有造轮船的任务到来,可立即开始造轮船)
- 静态流水线
- 单功能流水线
-
按流水线是否有反馈回路划分:
- 线性流水线
- 非线性流水线-流水线调度
-
按流水线输出端任务流出顺序与输入端任务流入顺序是否相同划分:
- 顺序流动流水线(入出顺序相同)
- 异步流动流水线(入出顺序不同)无序流水线 / 错序流水线 / 乱序流水线
-
按流水线一次处理对象的数量划分:
- 标量流水线:IBM System360/91、Amdahl 470V/6
- 超标量流水线:MIPS R10000
- 向量流水线:TI ASC、STAR-100、CYBER-205、CRAY-1、YH-1
- 超长指令字流水线:Intel Itanium(EPIC IA-64)
具有多个相同的功能即可用流水线来处理
浮点运算流水线(重点)
浮点数加/减运算需要4个操作步骤:
1. 对阶
加载: E1:= XE,M1:= XM; E2:= YE,M2:= YM;
比较: E:= E1-E2;
尾数对齐:
while (E﹤0){
M1:= right_shift(M1), E:= E+1;
}
while (E﹥0){
M2:= right_shift(M2), E:= E-1;
}
2. 尾数加/减
加/减: R:= M1+M2, E:= max(E1, E2);
3. 结果处理
溢出: if (R_OVERFLOW = 1)
then {
if (E = EMAX) then go to ERROR;
R:= right_shift(R), E:= E+1,go to END;
}
为零: if (R = 0)
then E:= 0, go to END;
规格化: while (R=非规格化数){
if (E>EMIN)
then R:= left_shift(R), E:= E-1;
};
go to END;
4. 舍入处理
截断法、末位恒置“1”法、0舍1入法
指令流水线(重点)
基本的指令流水线
提高计算机系统速度的途径:
- 更快的电路
- 改进CPU组织结构
- 减少用于执行指令的时钟周期数
- 简化组织结构,缩短时钟周期
- 用多寄存器取代单一的累加器
- 在存储系统中引入高速缓冲存储器cache
- 指令流水(instruction pipelining)
将指令处理分解为以下4步:
- 指令获取(IF):从主存或Cache中获取指令并对指令进行译码;
- 操作数加载(OL):从主存或Cache中获取操作数放入寄存器中;
- 执行指令(EX):利用ALU等执行部件,对寄存器中的操作数进行处理,结果存于寄存器中;
- 写操作数(WO):将寄存器中的结果存入主存或Cache中。
在没有指令分支、Cache失效或其他原因引起的延时等条件下,CPU的最大执行速率可达到理想水平,即CPI=1(理想情况)。但是往往有其他损耗,如:
- 间接寻址:在获取操作数之前,通常需要ALU计算操作数在内存中的地址。
- ALU完成复杂的运算(如浮点计算)往往需要多个时钟周期,使得CPI>1。
指令流水线策略
-
增加指令流水线深度
采用深度指令流水线结构:将指令的执行过程进一步细化(因为有缓冲,不能无限的细分),使流水线的级(段)数变多,而每一级的工作更少、更合理。
这样做有两个好处:- 流水线级数变多、处理更趋合理,可使单条指令流水线并行执行指令的能力更强;
- 每一级的处理时间更短,可以进一步提高处理器的工作频率。
深度指令流水线可以使处理器执行指令的速度更快、效率更高。
- 增加流水线的深度可以提高流水线的性能,但:
- 流水线深度受限于流水线的延迟和额外开销;
- 需要用高速锁存器作为流水线的缓冲寄存器。
-
增加指令流水线条数
增加指令流水线的深度的局限:- 指令执行过程的细化是有限度的。
- 随着流水线深度的增加,流水线段之间的缓冲器增多,延迟加大,使流水线的性能提高受到阻碍。
流水线性能度量
时-空图
通过时间 = (流水线级数 - 1) × 时钟周期; (此处不是通用的,只有每个工作段时间长度相同时才可使用,如:洗衣机时间 = 烘干机时间 = 晒衣服时间)
Tips: 流水线经过 “通过时间”,才进入稳定工作状态(前面洗衣店例子:每个设备都有人用),即从此之后每一个时钟周期(拍)流出一个结果;
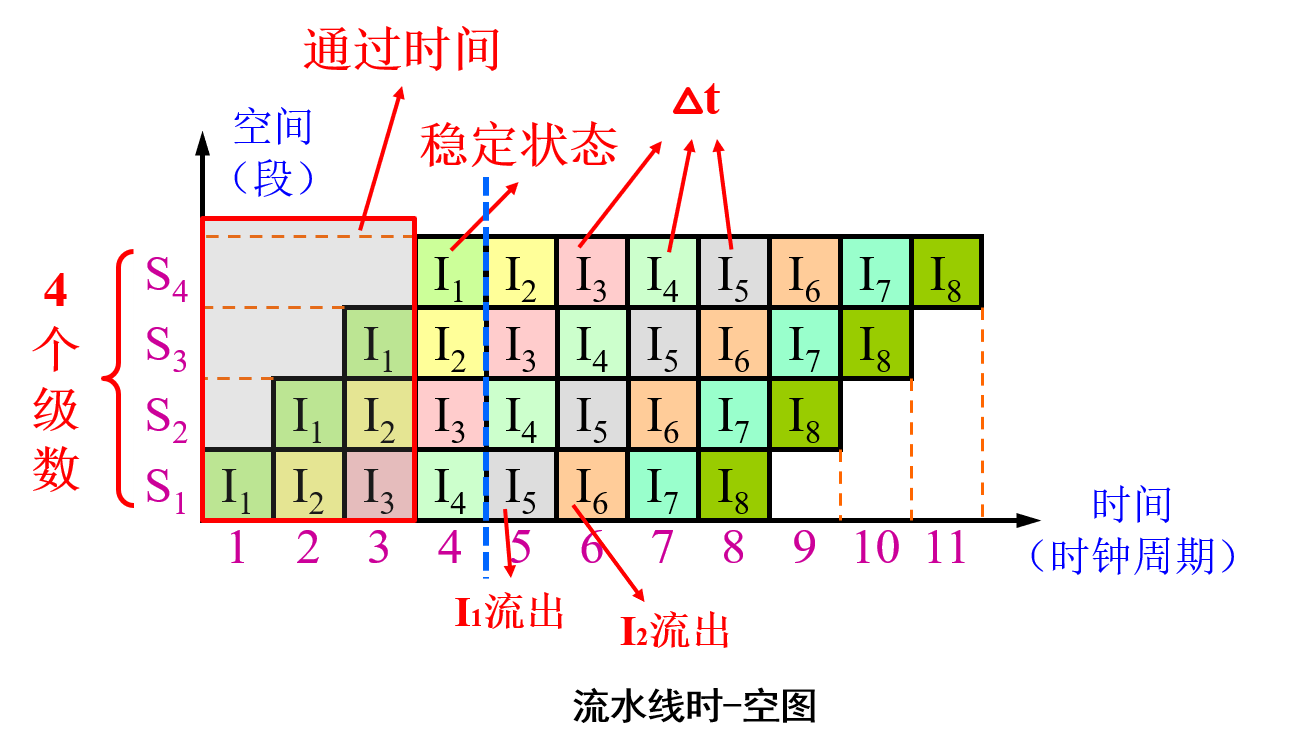
吞吐率
吞吐率:单位时间内流水线所完成的任务数或输出结果的数量。
最大吞吐率TPmax:流水线在达到稳定状态后所得到的吞吐率。
- 假设流水线各段运行时间相等,为1个时钟周期TCLK,则:TPmax = 1/TCLK。
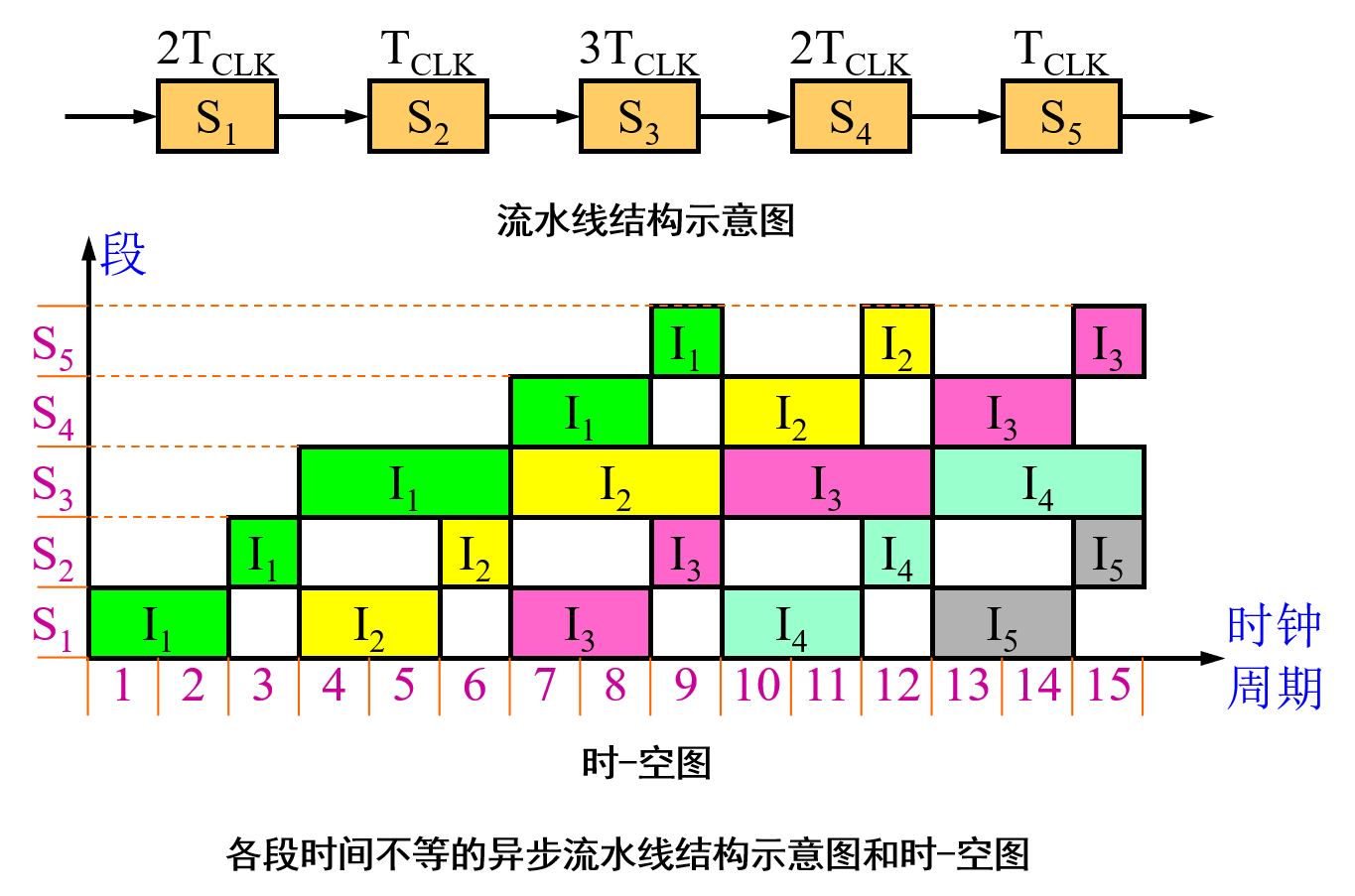
- 假设流水线各段运行时间不等,第i段时间为τi ,则TPmax = 1/max{τi} = 1/τ。
最大吞吐率取决于流水线中最慢一段所需的时间,所以该段成为流水线的瓶颈。消除瓶颈的方法有:
- 细分瓶颈段
- 重复设置瓶颈段
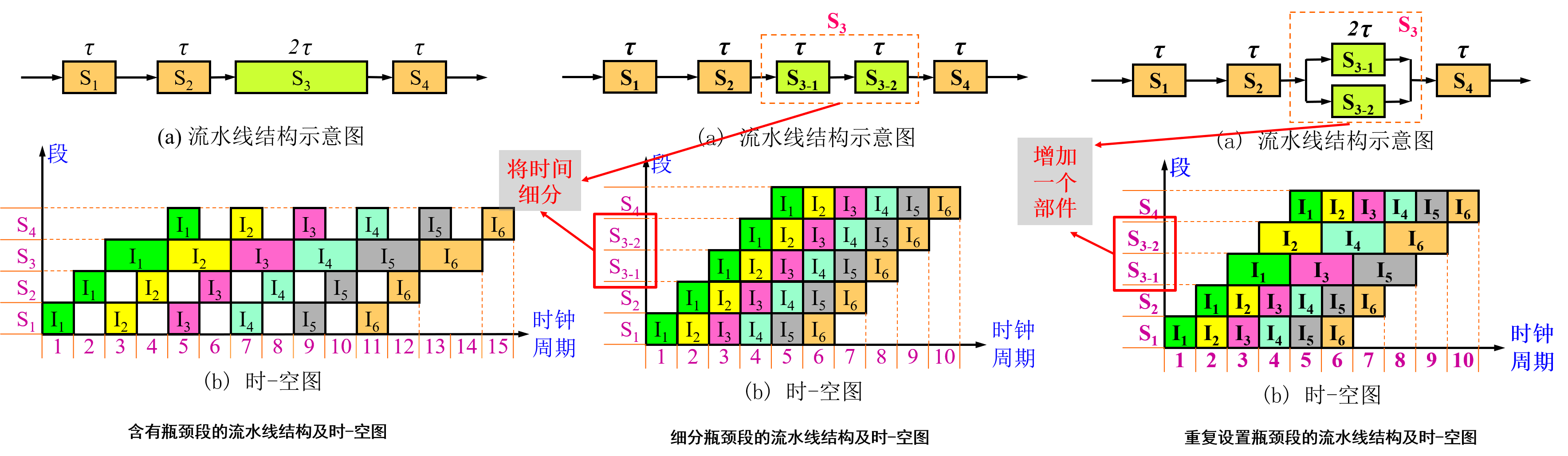
实际吞吐率:若流水线由m段组成,完成n个任务的吞吐率称为实际吞吐率,记作TP。
使TP最大化,或使TP接近于TPmax,是流水线实现中重点要解决的问题。
假设流水线各段运行时间相等,为1个时钟周期TCLK,在不出现流水线断流的情况下,完成n个任务所用时间为 Tn(m) = (m - 1 + n) × τ = (m - 1 + n) × TCLK
实际吞吐率为:
𝑇𝑃 = 𝑛 / (𝑇𝑛 (𝑚)) = 𝑛 / ((𝑚 - 1 + n) × 𝑇𝐶𝐿𝐾) = (𝑇𝑃max) / {1 + [(𝑚−1) / 𝑛]}
假设流水线各段运行时间不等,第i段时间为τi,则完成n个任务所用时间为
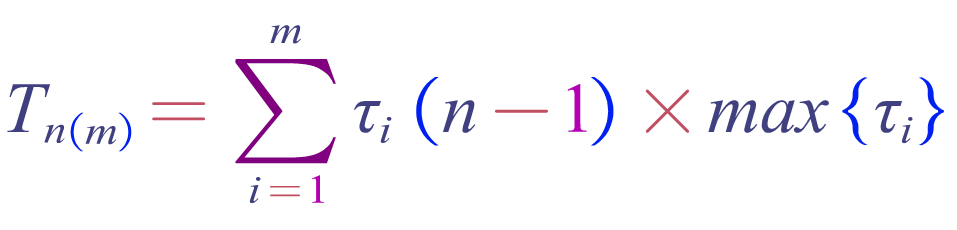
TP = n / Tn(m)
对于指令流水线而言,吞吐率TP就是每秒执行的指令数,所以也可以用MIPS(每秒的百万条指令数字)指标表示吞吐率,即TP = MIPS = fCLK / CPI
单流水线计算机系统
∵ CPI最佳 = 1
∴ TPmax=fCLK
加速比
若流水线为m段,加速比S定义为等功能的非流水线执行时间T(1) 与流水线执行时间T(m)之比,即S = Sn(m) = Tn(1) /Tn(m)
若每段运行时间均为τ,在不流水情况下,完成n个任务所需时间为:Tn(1)= n · mτ
在流水但不出现断流的情况下,完成n个任务所需时间为:Tn(m)= mτ + (n-1)τ ,因此
𝑆𝑛(𝑚) = 𝑚𝑛 / (𝑚+𝑛−1) = 𝑚 / (1+(𝑚−1)/𝑛)
效率
效率:流水线的设备利用率。
由于流水线有通过(填充)时间和排空时间,所以流水线的各段并非一直满负荷工作,效率E<1。
假设流水线各段运行时间相等为τ,各段效率ei~~也相等,即e1= e2 = … = em = nτ / Tn(m)
则整个流水线效率E为:
𝐸 = (∑_(𝑖=1)^𝑚𝑒_𝑖) / 𝑚
当n >> m时,E ≈ 1。
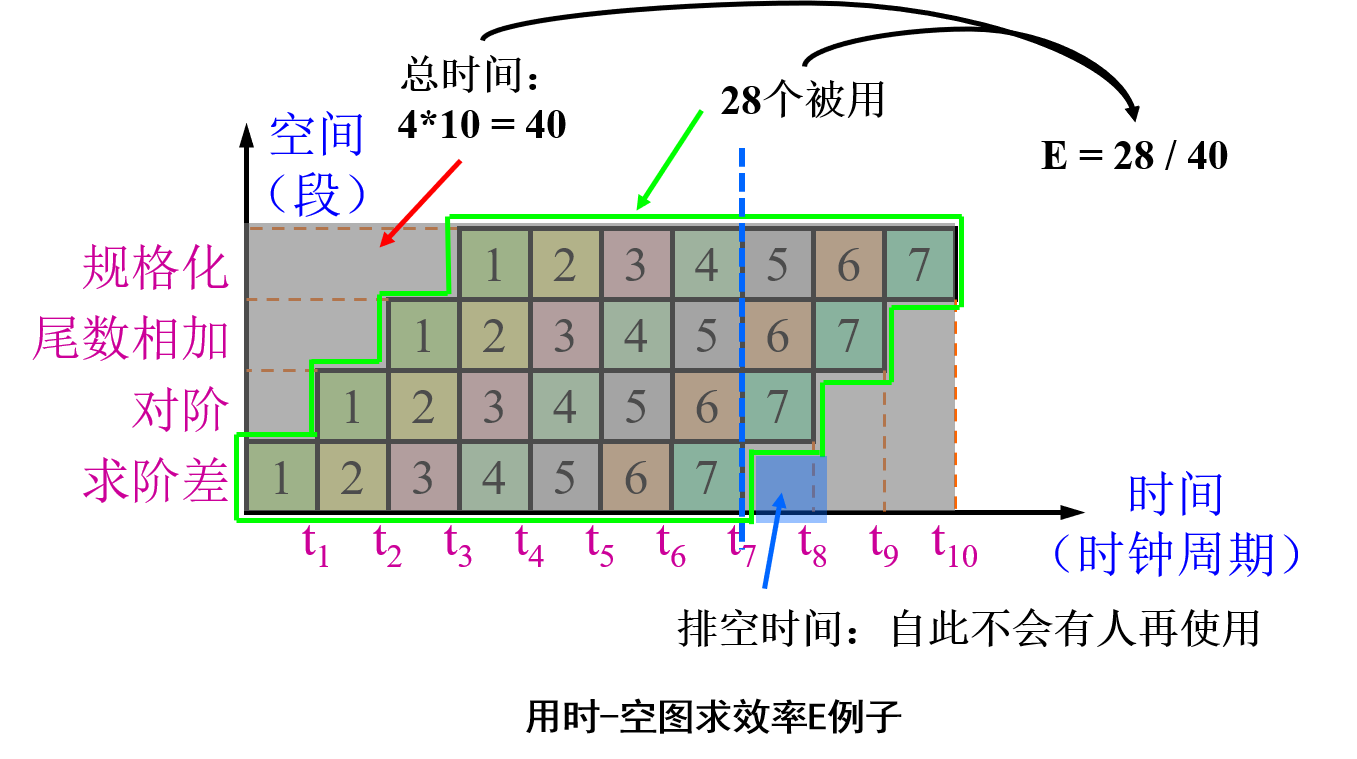
从时-空图上看,效率就是n个任务所占的时空区与m个段总的时空区之比。根据这个定义,可以计算流水线各段时间不等时的流水线效率为:
𝐸 = 𝑛个任务占用的时空区 / 𝑚个段总的时空区
流水线性能分析
【例】
【解】
【例】
【解】
指令流水线的性能提高
流水线的基本性能问题
限制指令流水线性能提高的因素:
- 流水线的深度受限于流水线的延迟、流水线段的时间不均衡和流水线的额外开销。
- 指令执行时可能存在的相关(dependence)或“冒险(hazard)”问题。
相关:相邻或相近的两条指令因存在某种关联,后一条指令不能在原指定的时钟周期开始执行。(例如第一条指令得到的结果会在第二条指令上使用,所以必须等第一条指令全部执行完成后,才能开始执行第二条指令)。
相关或冒险有3类:
- 结构(structural)相关:资源冲突。(局部性相关)
- 数据(data)相关:一条指令需要用到前面某条指令的结果。(局部性相关)
- 控制(control)相关:分支等转移类指令/其他能够改变PC值的指令。(全局性相关)
有停顿的流水线的CPI为:
CPI = 理想流水线CPI(没有相关下的CPI) + (结构相关停顿 + 数据相关停顿 + 控制相关停顿) / 指令数
- 有停顿的流水线的加速比为:
加速比 = 流水线深度 / (1 + 每条指令的流水线停顿周期) - 消除相关、减少停顿是提高已有流水线性能最重要的手段。
结构相关(要大概知道三种相关以及解决方法)
有两种情形会导致结构相关:
- 部分功能单元没有充分流水。
解决办法:将流水线设计的更合理。 - 资源冲突(resource conflicts):当两个以上流水线段需要同时使用同一个硬件资源时,发生冲突。
解决方法:- 增加资源副本:
- 存储器冲突:哈佛结构
- 两个ALU:取指令-地址加法器
- 改变资源以便它们能并发的使用。
- 不相关的数据尽量使用不同的寄存器
- 寄存器重命名
- 通过延迟(或暂停)流水线的冲突段或在冲突段插入流水线气泡(气泡在流水线中只占资源不做实际操作),使各段“轮流”使用资源。
- 增加资源副本:
数据相关
指令在流水线中的重叠执行有可能改变指令读/写操作数的顺序。
当一条指令的结果还未有效生成,该结果就被作为后续指令的操作数时,数据相关出现。
相关类型:
- 先写后读(Read After Write)
- 先读后写(Write After Read)
- 写-写(Write After Write)
解决办法:
- 采用直通(forwarding)技术(相关直接通路)
将运算结果经相关直接通路直接送入所需部件。 - 增加专用硬件(推后法)
增加流水线互锁(pipeline interlock)硬件。互锁硬件先要检测流水线中指令的数据相关性,当互锁硬件发现数据相关时,使流水线工作停顿下来,直到相关消失为止。 - 利用编译器
流水线调度/指令调度:编译器可以对指令重新排序或插入空操作指令,使得加载任何冲突数据的操作被延迟,但对程序逻辑或输出不受影响。
控制相关
使程序执行顺序发生改变的转移指令有两类:
- 无条件转移指令(如无条件跳转、调用、返回指令等)
- 某些CPU(I)如UltraSPARC III):紧跟在无条件转移指令之后的指令必须执行。
- 另一些CPU:采取相对复杂的方法,如提前计算出转移目标地址。
- 条件分支转移指令(为零跳转、循环控制指令等)
- 不仅需要延迟槽,而且一直到流水线的深处,取指单元才能知道到哪里去取下一条指令。
- 条件分支指令对流水线性能的影响远比无条件转移指令要大。
- 分支延迟槽(branch delay slot):程序中位于转移指令后面的存储单元位置。
对条件分支指令的处理方法:
- 冻结流水线
- 预取分支目标
- 多流
- 循环缓冲器
- 分支预测
- 静态分支预测
- 预测分支不会发生
- 预测分支总是发生
- 由编译器预测
- 测试法
- 动态分支预测
- 分支历史表
- 分支历史移位寄存器
- 静态分支预测
- 延迟分支
- 加快和提前生成条件码
指令级并行概念(了解)
提高指令级并行的技术(不是重点)
程序中的相关主要有三种:
数据相关
名称相关
控制相关
乱序执行
寄存器重命名
推测执行
多发射处理器(不是重点)
多发射CPU分为
- 超标量处理器(Superscalar Processor)
- 超长指令字(Very Long Instruction Word, VLIW)
多发射处理器的发射宽度或(并行)度(degree):每时钟周期可以发射的指令数。
超标量处理器
超标量:有多个CPU,CPI可低于1。
超长指令字处理器
一个指令中有若干个操作码(超长指令的度为操作码个数)。














 6039
6039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









