







 本文详细介绍了计算机组成原理中的CPU结构,包括数据通路和控制单元,以及CPU如何执行指令。讲解了指令周期的概念,分为取指、执行和中断子周期,并阐述了微操作和微命令的原理。此外,还对比了硬布线控制器和微程序控制器的设计方法,讨论了CPU性能的测量与提高策略,如MIPS和FLOPS等指标。
本文详细介绍了计算机组成原理中的CPU结构,包括数据通路和控制单元,以及CPU如何执行指令。讲解了指令周期的概念,分为取指、执行和中断子周期,并阐述了微操作和微命令的原理。此外,还对比了硬布线控制器和微程序控制器的设计方法,讨论了CPU性能的测量与提高策略,如MIPS和FLOPS等指标。
前言:去年备研学习计算机组成原理的一些笔记,因为主要为了应付考试,记得比较仓促,仅供参考。
文章目录
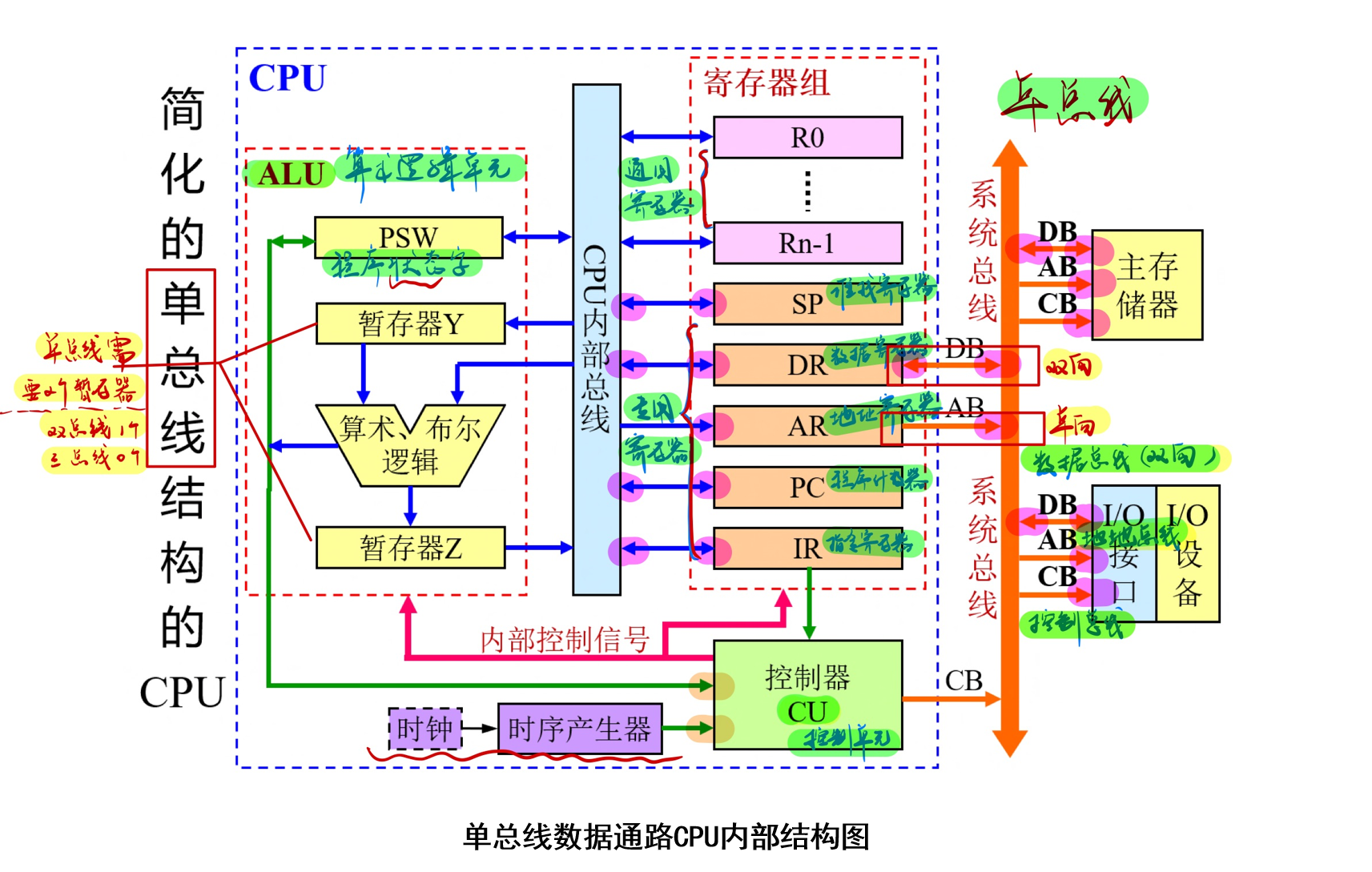
中央处理器(CPU)
CPU结构和微操作
CPU的功能与结构
CPU的功能需求:
- 操作(操作码)
- 寻址方式
- 寄存器
- I/O模块接口
- 存储器模块接口
- 中断处理机构
CPU的组成:
- 数据通路DP(datapath)存储单元/寄存器组ALU
- 控制单元CU(control unit,即控制器):负责进行顺序操作,并确保适当的数据在适当的时刻出现在需要它的地方。
CPU的任务:
- 取指令、译码指令、完成指定顺序的操作。
- 确定指令的执行顺序。
单总线数据通路CPU内部结构图
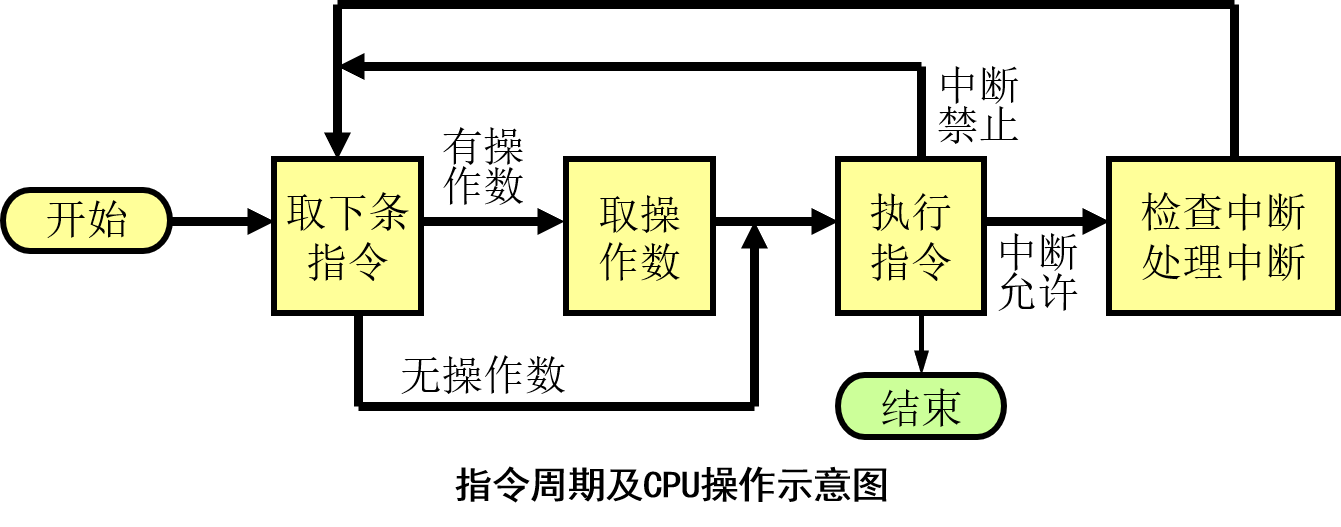
指令周期
在处理一条指令的过程中,由CPU完成的操作序列构成一个指令周期(instruction cycle)。
- 取指令子周期(fetch cycle)
- 执行指令子周期(execute cycle)
- 中断子周期(interrupt cycle)
CPU周期或机器周期:
- 取指子周期
- 取数子周期
- 执行子周期
- 中断子周期
微操作
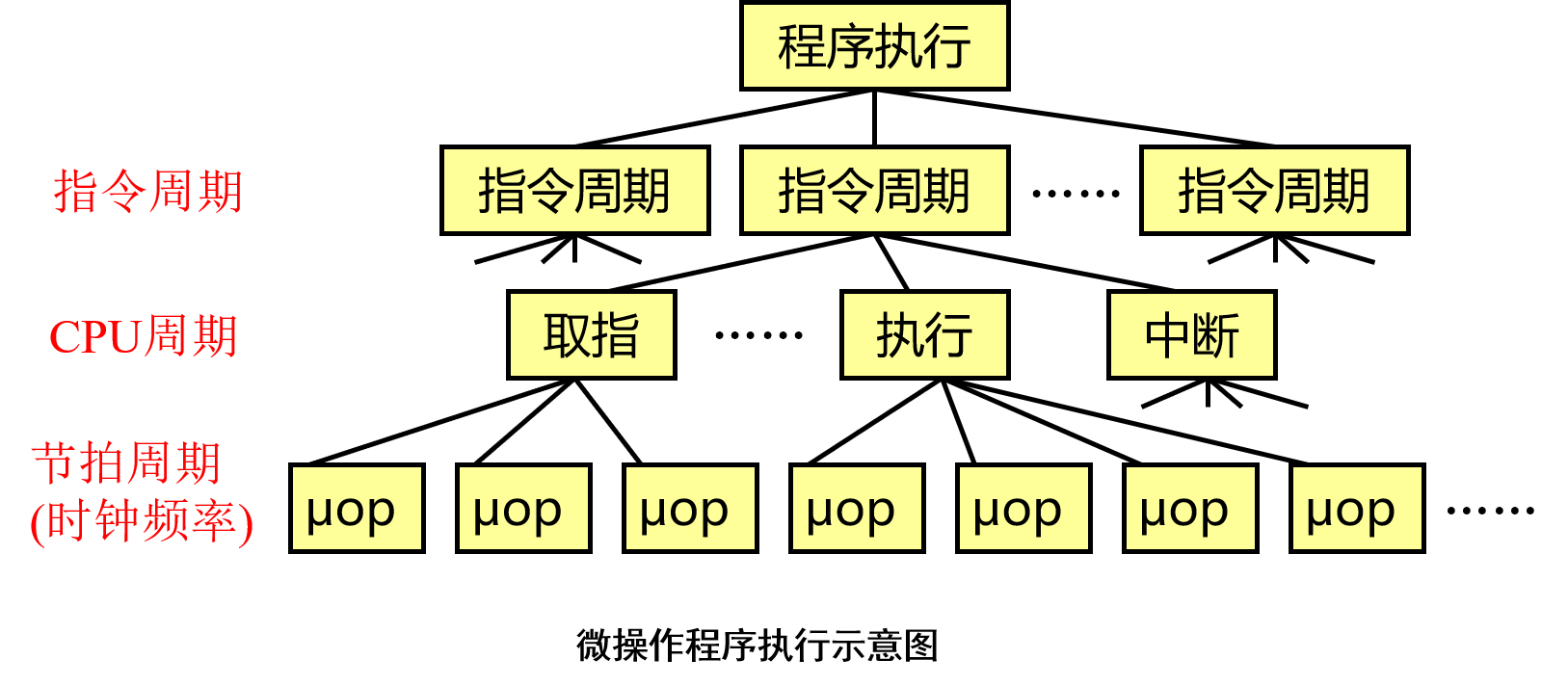
微操作与微命令
微操作:处理器(CPU)的基本或原子操作。
- CPU可以实现的、不可分解的操作动作。
- 以含有一个寄存器传递(移进、移出)操作为标志。
每一个微操作是通过控制器将控制信号发送到相关部件上引起部件动作而完成的。
- 这些控制微操作完成的控制信号称为微命令。
- 微命令是由控制器产生的。
微操作:AR←PC;
微命令:PCout,ARin
微操作流程
-
时序信号的产生
CPU执行指令需要三种时序信号:- 指令周期:执行一条指令所用的时间。
- CPU周期:完成一个子周期所用的时间。
- 节拍周期:完成一个微操作所用的时间。
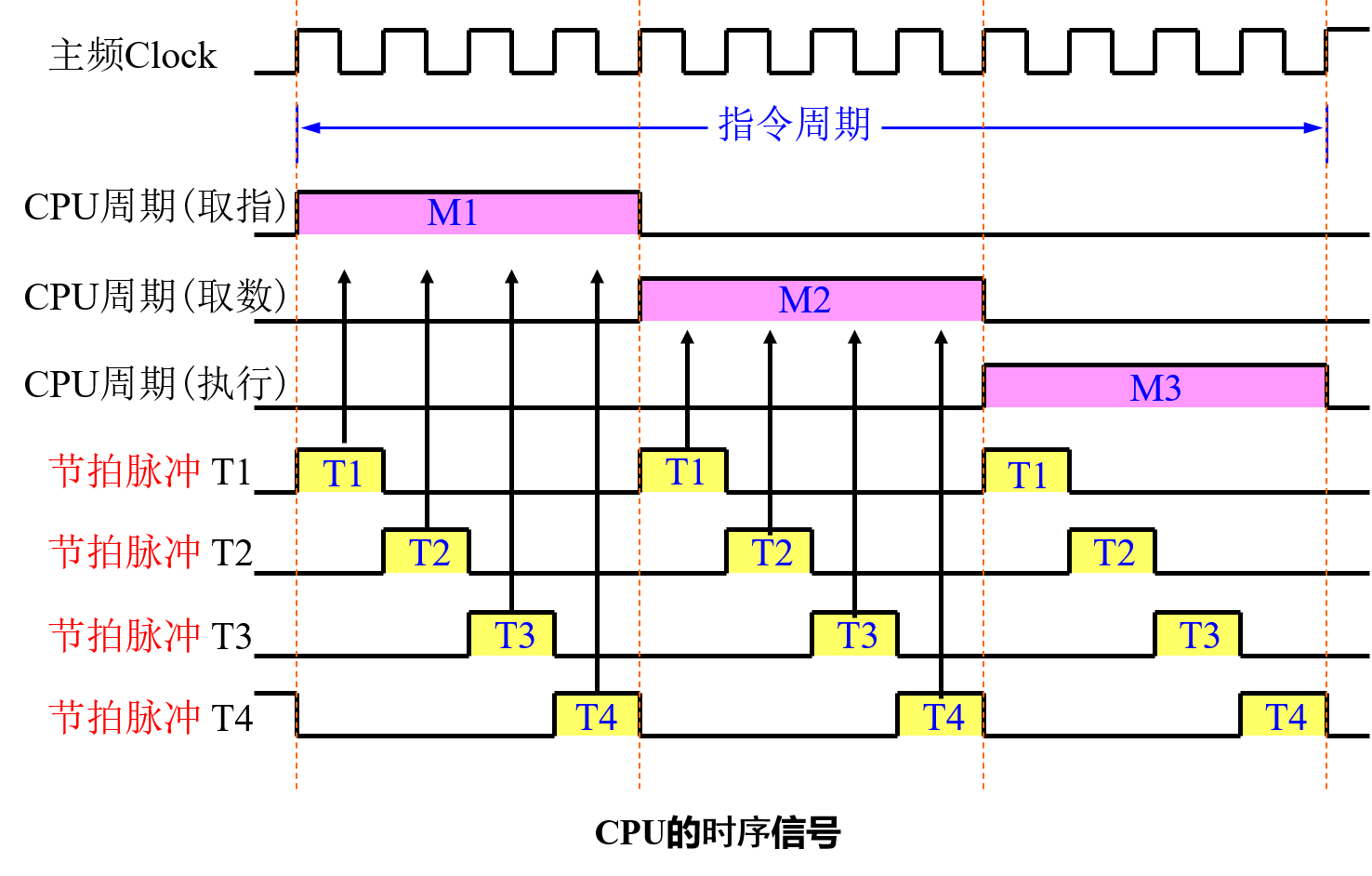
- 节拍周期的产生
- 节拍周期T:完成各种CPU微操作所需时间的最大者,常作为定义CPU时钟周期Tclock或时钟频率fclock的依据。
fclock = 1 / Tclock = (1 ~ n) / T - CPU执行程序有严格的时间顺序性,通常利用时序电路为控制器提供所需的时序信号。最基本的时序信号为节拍,它可由顺序脉冲发生器也称脉冲分配器或节拍脉冲发生器产生。
- 节拍脉冲发生器分计数型和移位型两类。
- 节拍周期T:完成各种CPU微操作所需时间的最大者,常作为定义CPU时钟周期Tclock或时钟频率fclock的依据。
- CPU周期(机器周期)的产生
- 若干个节拍组成一个CPU周期
- CPU周期可以设计为定长与不定长两种。
- 定长CPU周期:CPU周期中的节拍数固定→实现简单
- 将CPU周期中的节拍数规定为所有指令子周期所需时间节拍数的最大者
- 对于操作比较简单的指令,会出现空闲节拍,造成指令执行时间增长,CPU速度降低
- 不定长CPU周期:根据指令的不同子周期动态地确定CPU周期的节拍数
- 节拍脉冲发生器中的计数器按最长CPU周期设计
- 利用CPU周期结束信号END动态地调整实际的CPU周期长度(节拍数)
- 定长CPU周期:CPU周期中的节拍数固定→实现简单
- 指令周期的结束
- 若干个CPU周期组成一个指令周期。
- 指令周期也可以设计为定长与不定长两种。
- 定长:指令周期的结束以CPU周期计数器计数到最大值为标志。
- 不定长:在一个指令周期结束的那一刻,控制单元必须发出控制信号使计数器回归到计数的初始状态下。
-
取指周期
取指周期也被称作公操作(执行任何一条指令时第一步都是取指令)。
一个简单的取指周期可由3个步骤、4个微操作组成:T1: AR←PC ///< PC的内容传送到AR T2: DR←Memory[AR], Mread ///< 由AR规定的存储单元的内容(当前指令)传送到DR PC←PC+I ///< PC内容加I形成下条指令地址,I为指令长度 T3: IR←DR ///< DR的内容传送到IR- 在同一个周期中,总线只能存一个数据流,所以不能同时对同一寄存器进行操作,( 例如PC←PC+I不能放在T1中)
- 不存在相关的操作叫做相容的,不能同时进行的操作叫做互斥的
组合微操作:
T1: AR←PC T2: DR←Memory[AR], Mread T3: PC←PC+I IR←DR MOV R1, 80H -
中断子周期
- 在执行周期结束时有一个检测,用来确定被允许的中断是否已出现,若是,中断周期产生。
- 中断周期微操作序列举例:
T1: DR←PC ///< PC的内容传送到DR加以保护,以便实现从中断返回 T2: AR←Save_Address ///< 中断断点信息保护区的存储单元地址传送到AR T3: PC←Routine_Address ///< 中断服务程序首地址送入PC T3: Memory[AR]←DR, Mwrite ///< 将老PC的内容保存于内存(如堆栈)中 -
执行周期
- MOV R1, R0
- 实现将寄存器R0的内容传送至寄存器R1中。
- 执行周期的微操作序列为:
T1: R1←R0 ///< 中将R0中的数据传送到R1- MOV R0, X(内存单元)
- 实现将存储单元X中的内容传送至寄存器R0中。
- 执行周期的微操作序列为:
T1: AR←IR(地址字段) ///< 将指令中的存储器地址X传送到AR,IR(地址字段)=X T2: DR←Memory[AR], Mread ///< 从存储单元X中读出的数据传送到DR T3: R0←DR ///< DR的内容传送到R0- MOV (R1), R0
- 将寄存器R0的内容传送至由寄存器R1间接寻址的存储单元中。
- 执行周期的微操作序列:
T1: AR←R1 ///< 将R1中的存储单元地址传送到AR T2: DR←R0 ///< R0中的数据传送到DR T3: Memory[AR]←DR, Mwrite ///< 将DR的内容写入指定的存储单元中- ADD R1, R0
- 将寄存器R0的内容与寄存器R1的内容相加并将结果存入R1。
- 执行周期的微操作序列:
T1: Y←R0 ///< 将R0中的数据传送到暂存器Y中 T2: Z←R1+Y ///< R1中数据与Y中数据加载至ALU做加法,结果暂存于Z中 T3: R1←Z ///< 将暂存器Z的内容传送到R1中- SUB R0, (X)
- 实现寄存器R0中的被减数减去存储器地址X间接寻址的存储单元中的减数、将差值传送至寄存器R0中。
- 执行周期的微操作序列:
T1: AR←IR(地址字段) ///< 将指令中的存储器地址X传送到AR,IR(地址字段)=X T2: DR←Memory[AR],Mread ///< 减数所在存储单元的地址传送到DR T3: AR←DR ///< DR的内容传送到AR T4: DR←Memory[AR],Mread ///< 再次访问存储单元,读出的减数传送到DR T5: Y←R0 ///< 将R0中的被减数传送到暂存器Y,假设ALU规定被减数在Y中 T6: Z←Y-DR ///< Y中被减数和DR中减数加载至ALU做减法,结果暂存于Z T7: R0←Z ///< 将暂存器Z的内容传送到R0中- IN R0,P
- 从I/O地址为P的I/O设备(接口)中输入数据并存入寄存器R0中。
- 执行周期的微操作序列:
T1: AR←IR(地址字段) ///< 将指令中的I/O地址P传送到AR,IR(地址字段)=P T2: DR←IO[AR], IOread ///< 从I/O设备(接口)中输入的数据传送到DR T3: R0←DR ///< DR的内容传送到R0- OUT P,R0
- 将寄存器R0中的数据输出到I/O地址为P的I/O设备(接口)中。
- 执行周期的微操作序列:
T1: AR←IR(地址字段) ///< 将指令中的I/O地址P传送到AR,IR(地址字段)=P T2: DR←R0 ///< R0的内容传送到DR T3: IO[AR]←DR, IOwrite ///< 将DR的内容输出至指定的I/O设备(接口)中- JUMP X
- 无条件跳转指令,实现将程序执行地址从当前跳转指令所在位置转移到存储器地址为X处。
- 执行周期的微操作序列:
T1: PC←IR(地址字段) ///< 将指令中的存储器地址X传送到PC,IR(地址字段)=X- JZ offs
- 采用相对寻址的条件跳转指令。当条件为真(即零标志ZF=1)时,程序发生跳转;条件为假(即零标志ZF=0)时,程序顺序执行下条指令。跳转地址=PC+offs,offs为带符号的地址偏移量。
- 与该指令相应的执行周期的微操作序列为:
If (ZF=1) then { T1: Y←IR(地址字段) ///< 将指令中偏移地址offs送入暂存器Y,IR(地址字段)=offs T2: Z←PC+Y ///< PC中当前地址与Y中偏移地址加载至ALU, 相加, 结果暂存于Z T3: PC←Z ///< 将暂存器Z中的跳转地址传送到PC中 }- PUSH R0
- 实现将寄存器R0中的数据压入到堆栈中。
- 执行周期的微操作序列:
T1: SP←SP-n ///< 将SP指向新栈顶,n为一次压栈的字节数 DR←R0 T2: AR←SP T3: emory [AR]←DR, Mwrite ///< 将R0的内容写入堆栈新栈顶处- POP R0
- 实现将堆栈栈顶的数据弹出至寄存器R0中。
- 执行周期的微操作序列:
T1: AR←SP T2: DR←Memory[AR], Mread T3: R0←DR ///< 堆栈栈顶处的内容传送到R0 SP←SP+n ///< 将SP指向新栈顶,n为一次弹出的字节数- CALL (X)
- 子程序调用指令。将程序执行地址从当前调用指令所在位置转移到以存储器地址X间接寻址的存储单元处,并保存返回地址。
- 执行周期的微操作序列:
T1: SP←SP-n ///< 将SP指向新栈顶,n为PC的字节数 R←PC T2: AR←SP T3: Memory [AR]←DR, Mwrite ///< 将PC中的返回地址保存在堆栈新栈顶处 T4: AR←IR(地址字段) ///< 将指令中的存储器地址X传送到AR,IR(地址字段)=X T5: DR←Memory[AR], Mread T6: PC←DR ///< 从存储单元X中读出的子程序首地址传送到PC- RET
- 子程序返回指令,实现从堆栈栈顶处获得子程序调用时保存的返回主程序的地址。
- 与该指令相应的执行周期的微操作序列为:
T1: AR←SP T2: DR←Memory[AR], Mread T3: PC←DR ///< 堆栈栈顶处的返回地址送入PC SP←SP+n ///< 将SP指向新栈顶,n为PC的字节数
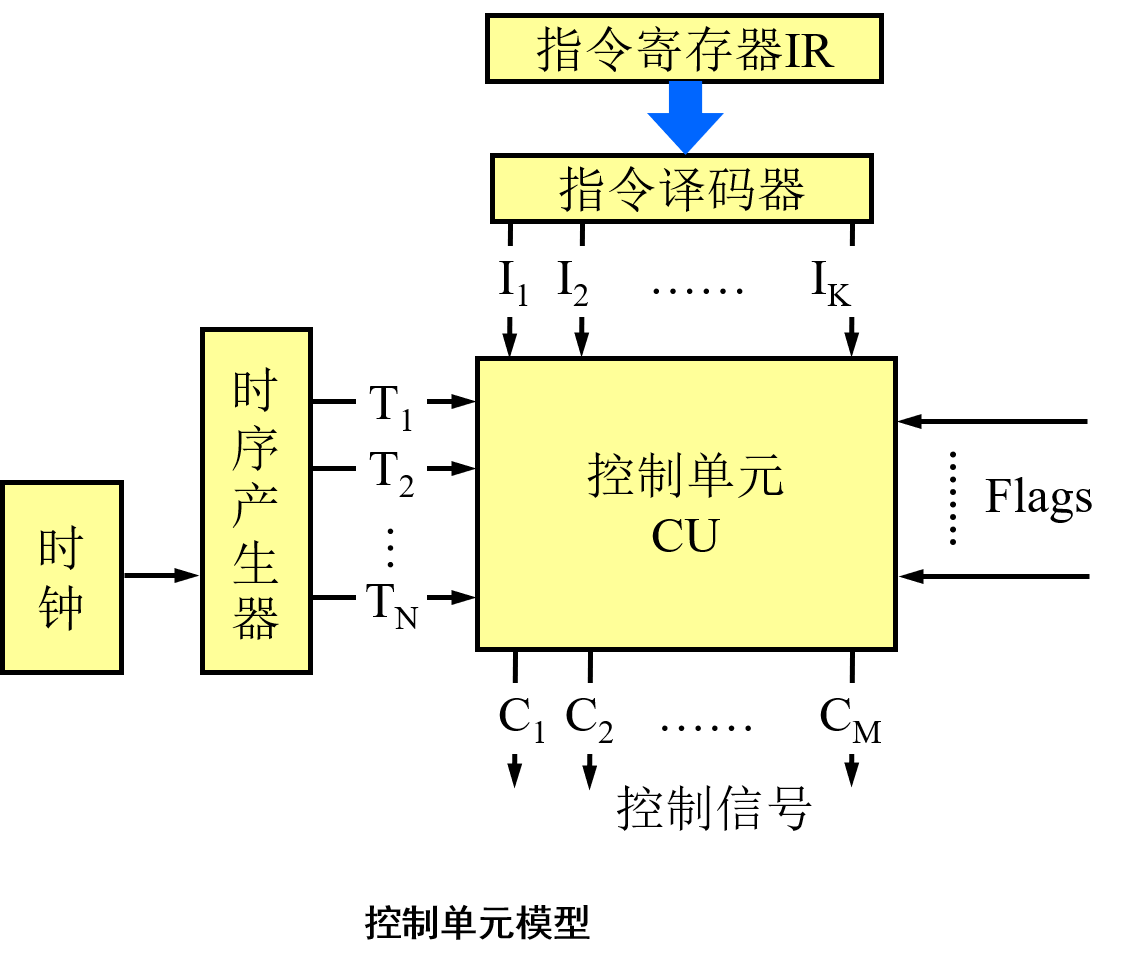
控制器的组成
控制器应完成的任务:
- 产生微命令(即控制信号)。
- 按节拍产生微命令。
两种设计控制器的通用方法:
- 硬布线控制(hardwired control)设计法
- 微程序控制(microprogrammed control)或微码控制(microcoded control)设计法
硬布线控制器设计
将控制单元看作一个顺序逻辑电路(sequential logic circuit)或有限状态机(finite-state machine),它可以产生规定顺序的控制信号,这些信号与提供给控制单元的指令相对应。
设计目标:最少的元器件,最快的操作速度
两种设计方法:
- 采用** 一级时序,即只产生节拍信号**
- 采用两级时序,即产生节拍和CPU周期两种时间信号
- 方法1:一级时序
- 实现指令SUB R0, (X)功能的微操作序列:
T1: AR←PC ///< 取指令阶段 T2: DR←Memory[AR],Mread PC←PC+I T3: IR←DR T4: AR←IR(地址字段) ///< 执行指令阶段 T5: DR←Memory[AR], Mread T6: AR←DR T7: DR←Memory[AR], Mread T8: Y←R0 T9: Z←Y-DR T10:R0←Z - 方法2:两级时序
- 实现指令SUB R0, (X)功能的微操作序列(采用两个CPU周期):
M1: ///< 取指CPU周期 T1: AR←PC T2: DR←Memory[AR], Mread PC←PC+I T3: IR←DR M2: ///< 执行CPU周期 T1: AR←IR(地址字段) T2: DR←Memory[AR], Mread T3: AR←DR T4: DR←Memory[AR], Mread T5: Y←R0 T6: Z←Y﹣DR T7: R0←Z
控制信号(微命令)
DRIin为双端口数据寄存器面向CPU内部总线的锁存输入控制信号;
DRIout为双端口数据寄存器面向CPU内部总线的输出允许控制信号;
DRSin为双端口数据寄存器面向系统总线的锁存输入控制信号;
DRSout为双端口数据寄存器面向系统总线的输出允许控制信号;
Mread为从主存储器读出信息的读控制信号;
Mwrite为将信息写入到主存储器的写控制信号;;
公操作取指周期以及其他指令
| 节拍 | 微操作序列 | 微命令序列 |
|---|---|---|
| T1 | ------------ | ------------ |
| T2 | ------------ | ------------ |
| T3 | ------------ | ------------ |
| 节拍 | 微操作序列 | 微命令序列 |
|---|---|---|
| T1 | ------------ | ------------ |
| T2 | ------------ | ------------ |
| T3 | ------------ | ------------ |
| 节拍 | 微操作序列 | 微命令序列 |
|---|---|---|
| T1 | ------------ | ------------ |
| T2 | ------------ | ------------ |
| T3 | ------------ | ------------ |
| 节拍 | 微操作序列 | 微命令序列 |
|---|---|---|
| T1 | ------------ | ------------ |
| T2 | ------------ | ------------ |
| T3 | ------------ | ------------ |
| 节拍 | 微操作序列 | 微命令序列 |
|---|---|---|
| T1 | ------------ | ------------ |
| T2 | ------------ | ------------ |
| T3 | ------------ | ------------ |
CPU的时序信号
-
PCout信号
- PCout出现在:
- 取指周期(定义为第1个CPU周期M1)的T1节拍,
- 指令JZ offs执行周期(假设为第2个CPU周期M2)的T2节拍(当ZF=1时)
- 指令CALL (X)执行周期的T1节拍
- ……
- 生成PCout的逻辑表达式为:
- 两级时序:PCout = M1·T1 + M2·T2·JZ(相对寻址)·(ZF=1) + M2·T1·CALL(间接寻址) + ······
- 一级时序:PCout = T1 + T5·JZ(相对寻址)·(ZF=1) + T4·CALL(间接寻址) + ······
- PCout出现在:
-
ARin信号
- ARin出现在:
- 取指周期的T1节拍
- 指令 MOV R0,X 和指令 MOV (R1),R0 执行周期的T1节拍
- 指令 SUB R0,(X) 执行周期的T1和T3节拍
- 指令 IN R0,P 和指令 OUT P,R0 执行周期的T1节拍
- 指令 PUSH R0 执行周期的T2节拍
- 指令 POP R0 执行周期的T1节拍
- 指令 CALL (X) 执行周期的T2和T4节拍
- 指令 RET 执行周期的T1节拍
- ……
- 生成ARin的逻辑表达式为:
- 两级时序:ARin = M1·T1 + M2·T1·MOV(源操作数直接寻址 + 目的操作数寄存器间接寻址) + M2·(T1+T3)·SUB(源操作数间接寻址) + M2·T1·(IN(直接寻址) + OUT(直接寻址)) + M2·T2·PUSH +M2·T1·POP + M2·(T2+T4)·CALL(间接寻址) + M2·T1·RET + ······
- 一级时序:ARin = T1 + T4·MOV(源操作数直接寻址 + 目的操作数寄存器间接寻址) + (T4+T6) ·SUB(源操作数间接寻址) + T4·(IN(直接寻址) + OUT(直接寻址)) + T5·PUSH + T4·POP + (T5+T7)·CALL(间接寻址) + T4·RET + ······
- ARin出现在:
硬布线控制器设计小结
- 每个控制信号的逻辑表达式就是一个与或逻辑方程式。
- 用一个与或逻辑电路就可以实现该控制信号的生成。
- 将所有控制信号的与或逻辑电路组合在一起就构成了硬布线控制单元。
- 时间信息、指令信息、状态信息是硬布线控制单元的输入,控制信号是硬布线控制单元的输出。
- 采用硬布线法设计控制器的特点:
- 一旦完成了控制器的设计,改变控制器行为的唯一方法就是重新设计控制单元 → 修改不灵活。
- 在现代复杂的处理器中,需要定义庞大的控制信号逻辑方程组 → 与或组合电路实现困难。
微程序控制器设计
微程序控制原理
微程序控制器设计基本思想
- 指导思想:用软件方法组织和控制数据处理系统的信息传送,并最终用硬件实现。
- 基本思想:依据微程序顺序产生一条指令执行时所需的全部控制信号。
- 相当于把控制信号存储起来,因此又称存储控制逻辑方法。
微指令
- 对在一个时间单位(节拍)内出现的一组微操作进行描述的语句称作微指令(microinstruction)。
- 一个微指令序列称作微程序(microprogram)或固件(firmware)。
- 通过一组微指令产生的控制信号,使一条指令中的所有微操作得以实现,从而实现一条指令的功能。

-
一条(机器)指令对应一个微程序,该微程序包含从取指令到执行指令一个完整微操作序列对应的全部微指令,它被存入一个称为控制存储器(control memory)的ROM中。
-
在控制存储器中存放着指令系统中定义的所有指令的微程序。
-
微指令周期:一条微指令执行的时间(包括从控制存储器中取得微指令和执行微指令所用时间)
-
微指令的一般格式
地址域 控制域 生成下条微指令的地址 产生控制信号
微程序控制器的一般结构和工作原理
微程序控制器在一个时钟周期内完成如下工作:
- 时序逻辑电路给控制存储器发出read命令;
- 从微地址寄存器uAR指定的控存单元读出微指令,送入微指令寄存器uIR;
- 根据微指令寄存器的内容,产生控制信号,给时序逻辑提供下条微地址信息;
- 时序逻辑根据来自微指令寄存器的下条微地址信息和CPU内外状态,给微地址寄存器加载一个新的微地址。
微指令设计
微指令的一般格式:
- 地址域:决定如何取得微指令
- 控制域:微指令的执行
设计微指令需要从两方面考虑:
- 微指令的长度 → 减少控制器占CPU集成芯片的面积。
- 微指令的执行时间 → 提高CPU的工作速度。
微指令地址的生产
下一条微指令的地址有三种可能:
- 由指令寄存器确定的微程序首地址:每一个指令周期仅出现一次,且仅出现在刚刚获取一条指令之后。
- 下一条顺序地址下一条微指令地址=当前微指令地址 + 1。
- 分支跳转地址
- 无条件和条件跳转
- 两分支和多分支跳转
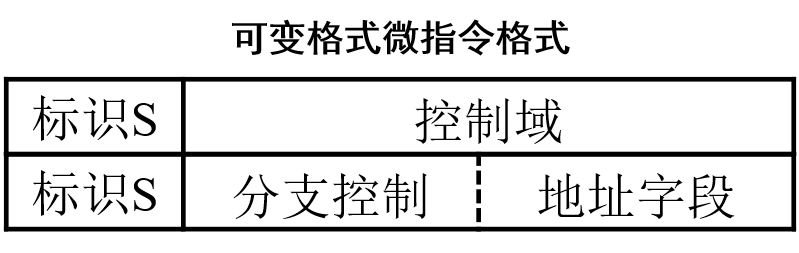
可变格式
- 使任何微指令执行时不存在无用信息:让微指令在顺序执行时只提供控制信号的产生,需要分支时再提供跳转地址。→ 可变格式微指令
- 两种微指令格式
- 控制微指令S=0
- 转移微指令S=1
- 控制存储器存储单元的位数L应设计为:
-
L= max{Lc,Lj}
-
Lc =控制微指令长度,Lj=转移微指令长度
-
微指令控制域编码
-
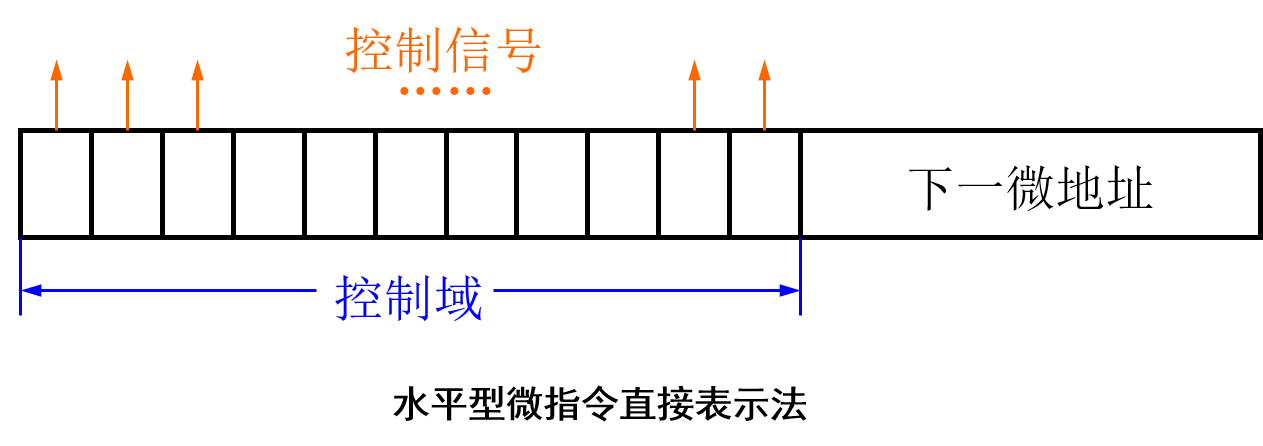
水平型微指令(horizontal microinstruction)多个控制信号同时有效 → 多个微操作同时发生。
- 直接表示法(水平编码)
-
可以在同一个时间有效的控制信号称为相容信号,具有相容性;
-
不能在同一个时间有效的控制信号称为互斥信号,具有互斥性。
-
- 译码法(垂直编码)
- 采用编码的方法表示控制信号。
- 可以极大地缩短微指令控制域的长度。
- 各控制信号需要通过不同的微指令在不同时间来产生,所以各控制信号是相斥的,这也被称为垂直编码。
- 不能实现一个节拍提供多个控制信号的任务,从而使指令周期的节拍数增多,微程序中包含的微指令数量增多,(机器)指令执行时间增长。
- 字段译码法(字段编码)
- 将控制域分为若干字段,字段内垂直编码,字段间水平编码。
- 互斥的信号放在同一字段
- 相容的信号放在不同字段
- 若各字段的编码相互独立,则通过各字段独立译码就可以获得计算机系统的全部控制信号,这被称作直接译码方式。
- 若某些字段的编码相互关联,则关联字段要通过两级译码才能获得相关的控制信号,这被称作间接译码方式。
- 直接表示法(水平编码)
-
垂直型微指令(vertical microinstruction)类似于机器指令,利用微操作码的不同编码来表示不同的微操作功能。(串行(顺序))发生)
-
水平型与垂直型微指令的比较
- 水平型微指令特性:
- 需要较长的微指令控制域;
- 可以表示高度并行的控制信号;
- 对控制域提供的控制信息只需较少的译码电路,甚至不需要译码。
- 垂直型微指令特性:
- 需要较短的微指令控制域;
- 并行微操作的表示能力有限;
- 对控制信息必须译码。
- 水平型微指令特性:
微程序控制器设计
微程序控制器设计的基本步骤:
- 指令分析:得到指令微操作(微命令)序列
- 微命令分析:归类,相容性/互斥性检查
- 微指令及控制器结构设计
- 确定微指令地址域格式:两地址/单地址/可变格式
- 确定微指令控制域格式:水平/垂直/字段编码
- 微程序与控制存储器设计
控制存储器容量 = 微指令长度 × (平均微程序长度(微指令数) / 一条指令) × 指令数- 选择微指令和微程序结构:结构1、结构2
- 确定微程序入口地址(首地址)的生成方法
- 微程序控制器实现
- 设计硬件逻辑电路并实现
- 编写微程序并存储到控制存储器中
微程序控制器(RISC)与硬布线控制器(CISC)的比较
微程序控制器
- 比硬布线控制器速度慢
- 设计简单化、规范化
- 功能可修改、可扩充
- 实现****成本低,出错概率小**
- 常用于CISC处理器控制器的实现
硬布线控制器
- 速度快
- 当计算机系统复杂时,设计困难
- 一旦实现,**不可修改和扩充
- 常用于RISC处理器控制器的实现
CPU性能的测量与提高
计算机系统性能测量
- 执行时间(execution time)也称响应时间,定义为一个任务从开始到完成所用的时间或计算机完成一个任务所用的总时间。
- 吞吐量(throughput)定义为在给定时间内(并行)完成的总任务数。
- 更快的CPU、多处理机系统: 性能P = 1 / 执行时间T; 性能比: PX / PY = TY / TX = n
CPU 性能测量
CPU 时间
- 运行一个程序所花费的时间。
- 响应时间:CPU时间与等待时间(包括用于磁盘访问、存储器访问、I/O操作、操作系统开销等时间)的总和。
假设计算机的时钟周期为TCLK,执行某程序时,CPU需要使用N个时钟周期,那么,CPU执行该程序所用时间为: - CPU执行一段程序所用的时间与该程序所包含的指令数成正比 → 编译器、指令集
CPU时间TCPU = CPU时钟周期数N x 时钟周期时间TCLK = CPU时钟周期数N / 时钟频率fCLK
【例】计算机A执行某程序用时20s,时钟为1.5GHz,设计者现要构建计算机B,使它以10s的执行时间运行该程序。设计者已确定增加时钟频率是可行的,但会影响CPU设计的其余部分,使得计算机B需要1.2倍于计算机A的时钟数来运行该程序,那么,设计者为B应选择多大的时钟频率?
解 3.6GHz
CPI
CPI(Clock cycles per Instruction):每条指令执行所用的时钟数。
IPC :每时钟周期执行的指令数。
N(CPU执行一段程序所需时钟周期数) = 该程序中的指令数I x 平均的每条指令所用时钟周期数CPI = ∑(𝐶𝑃𝐼𝑖 × 𝐼𝑖)
CPI = (1 / I) x N = (1 / I) x ∑(𝐶𝑃𝐼𝑖 × 𝐼𝑖) = ∑(𝐶𝑃𝐼𝑖 × (𝐼𝑖 / I))
有三方面的因素使得程序的CPI可能不同于CPU执行的CPI:
- Cache行为发生变化
- 指令混合发生变化
- 分支预测发生变化
- 对于某基准程序,用CPI表示的CPU性能为:
影响CPU性能的三个关键因素:
- CPI :流水线性能、cache性能
- 随程序、随体系结构实现不同而变化
- 时钟频率:受CPU硬件工艺及结构影响
- 指令数:指令集的体系结构、编译技术
【例】假设同一指令集结构有两种实现。计算机A的时钟周期为200ps,执行某程序时CPI =2.0;而计算机B的时钟周期为360ps,执行同一程序时CPI =1.2。执行该程序时,哪个计算机更快?
解 3.6GHz
MIPS
CPU每秒钟执行的百万指令数。
𝑀𝐼𝑃𝑆 = 指令数𝐼 / (执行时间𝑇×10^6) = 𝑓𝐶𝐿𝐾 / (𝐶𝑃𝐼 × 106 )
MIPS参数的局限:
- 不能对指令集不同的计算机使用MIPS进行比较:MIPS只说明了指令执行速率,而没有考虑指令的能力。
- 计算机对所有程序没有单一的MIPS值:对于同一个计算机上的不同程序,MIPS是变化的。
- MIPS会与性能反向变化。
【例】
FLOPS
CPU每秒完成的浮点运算次数。
𝐹𝐿𝑂𝑃𝑆 = (浮点运算次数 𝑀) / 执行时间𝑇
提高CPU速度的策略
衡量CPU性能的指标:
- 处理能力:指令系统
- 处理速度
提高CPU速度的技术:
- 具体实现的改进
- 体系结构的改进
CPU中的新技术
- 与直接提升处理器频率相比,对于适当类型的应用程序,多核处理器提供了更高的性能,而其功耗仅有少量增加。
- 并不是所有应用程序都能平等地利用多核处理器。要实现这些性能上的提升,需要开发者做出大量的工作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









