







 文章介绍了在华为Atlas800服务器上使用PyTorch1.11.0和CANN7.0.0.alpha003开发环境中,对CLIP模型进行算子支持分析的过程。通过PyTorchAnalyse工具发现torch.jit相关API不支持,但torch.Tensor.triu_api和multi_head_attention_forward可能有效。还探讨了自动迁移模型到NPU的方法,以及处理torch.jit.load不支持的问题,指出精度差异主要源于CPU和NPU的浮点数计算差异。
文章介绍了在华为Atlas800服务器上使用PyTorch1.11.0和CANN7.0.0.alpha003开发环境中,对CLIP模型进行算子支持分析的过程。通过PyTorchAnalyse工具发现torch.jit相关API不支持,但torch.Tensor.triu_api和multi_head_attention_forward可能有效。还探讨了自动迁移模型到NPU的方法,以及处理torch.jit.load不支持的问题,指出精度差异主要源于CPU和NPU的浮点数计算差异。
(1)开发环境
训练环境:华为 Atlas 800(9000) 服务器,PyTorch 1.11.0
CANN 安装环境:CANN 社区版 7.0.0.alpha003 版本文档
官方代码:https://github.com/openai/CLIP
(2)CLIP 模块使用算子支持度分析
方法:使用 PyTorch Analyse 迁移分析工具,对源码 clip 模块进行使用算子支持度分析
工具使用说明文档:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/700alpha003/ptmoddevg/ptmigr/AImpug_0138.html
# Ascend 安装在 home 用户目录下
cd ~/Ascend/ascend-toolkit/latest/tools/ms_fmk_transplt/
./pytorch_analyse.sh -i ~/workspace/Codes/openai_clip/CLIP/clip -o ~/workspace/Codes/openai_clip/CLIP/ascend_analyse_op -v 1.11.0 -m torch_apis
分析结果:



检查分析结果:
在 CANN 社区版 7.0.0.alpha003 文档,在 模型开发(PyTorch) -> PyTorch网络模型迁移和训练 -> API 列表,查看 PyTorch 原生 API 算子支持情况
- torch.jit 相关 api 均不支持
- 而 torch.Tensor.triu_ api 是支持的
- 确定 unknown_api.csv 相关 api 也是支持的。其中 torch.nn.functional.multi_head_attention_forward 在 nn.MultiheadAttention 算子中被调用,nn.MultiheadAttention 确定是支持的,因此,torch.nn.functional.multi_head_attention_forward 虽然在 API 列表中没找到,但应该是支持的
!!! 注意,检测工具扫描出来的结果不一定正确,最后仍需要通过查看 API 列表和执行迁移代码确定相关算子是否支持。
(3)选用自动迁移方式迁移模型
参考文档:在 CANN 社区版 7.0.0.alpha003 文档,在 模型开发(PyTorch) -> PyTorch网络模型迁移和训练 -> 模型迁移
构建测试代码:复制源码仓库的测试代码,在 CLIP 工程目录下新建 test.py,确保 cpu 设备上能够跑通模型推理
# test.py
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
- 添加导入自动迁移库
import torch_npu
from torch_npu.contrib import transfer_to_npu
!ERROR: 执行代码出现 torch.jit.load 不支持导致的错误

(4)提供一种解决方法
- 因为 torch.load 是支持的,所以可以将模型在使用 cpu 设备时,先加载模型,然后将模型存储为 state_dict 仅有权重的模式,然后再使用 npu 设备时,使用 torch.load 进行模型加载即可
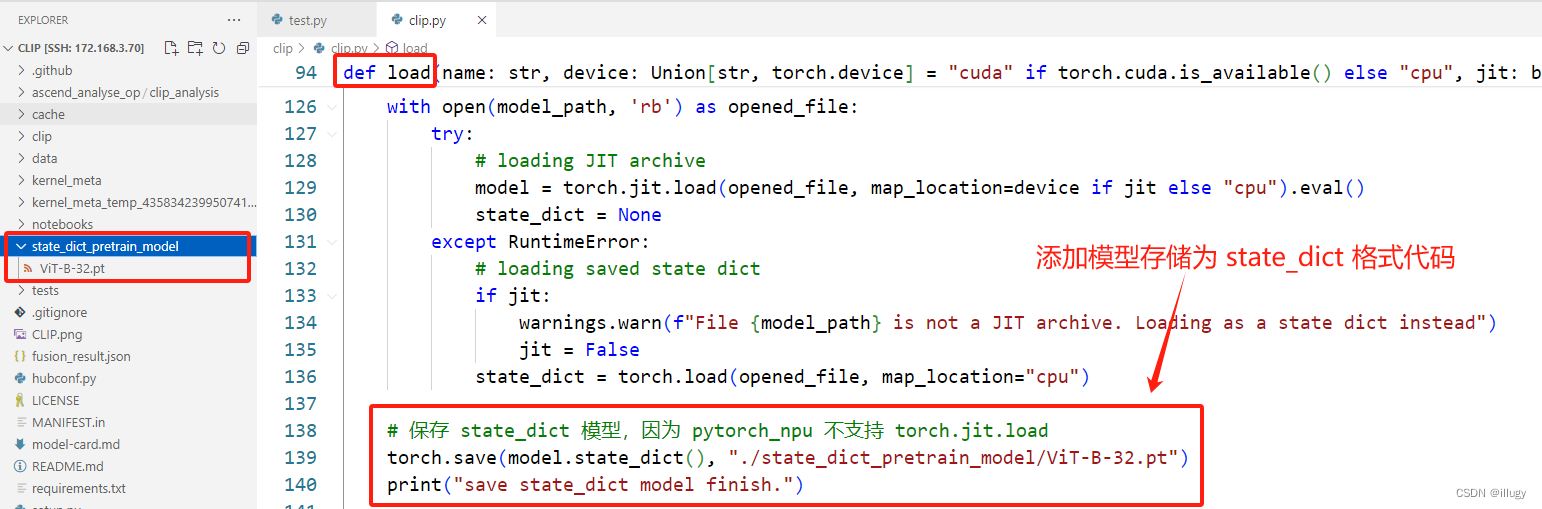
- 修改模型权重加载方式
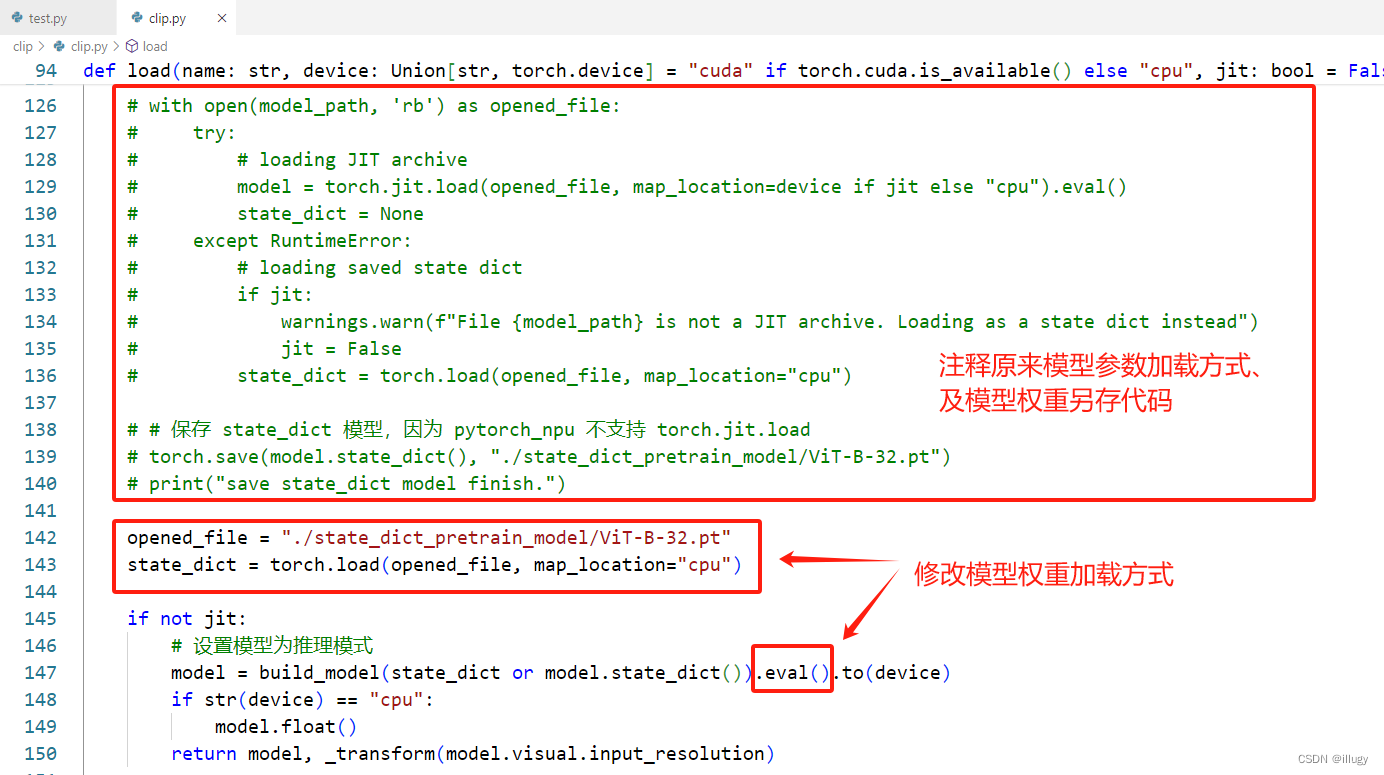
- 到此,再执行自动迁移的测试代码即可完成模型迁移

(5)结果分析
- 推理结果与 CPU 精度对不齐
在 cpu 设备执行推理,PyTorch 默认参数计算数据类型是 float32,而 npu 设备上执行推理时,大部分算子是使用 float16 进行计算。因此,存在一些精度误差也正常。
参考:
https://github.com/openai/CLIP
https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/700alpha003/processormodel/hardwaredesc_0001.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









