







ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS!
1、背景
本篇论文基于Transformer模型提出了一个基于注意力层的模型,并采用REINFORCE方法训练模型,来求解以下几种组合优化问题:
旅行商问题(Travelling Salesman Problem, TSP)
车辆路径问题(Vehicle Routing Problem, VRP)
定向问题(Orienteering Problem, OP)
奖金收集旅行商问题(Prize Collecting TSP, PCTSP)
2、基于注意力层的模型
整个文章的大致思路是:把所有点依次输入编码器,然后解码器输出解序列。这里根据TSP问题定义,对于其他问题模型是相同的,但需要相应的修改输入、mask和Decoder的context
模型定义为随机策略p ( π ∣ s )在给定实例s下选择一个解π 。参数化为θ:
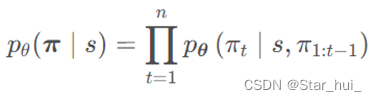
#3、编码器
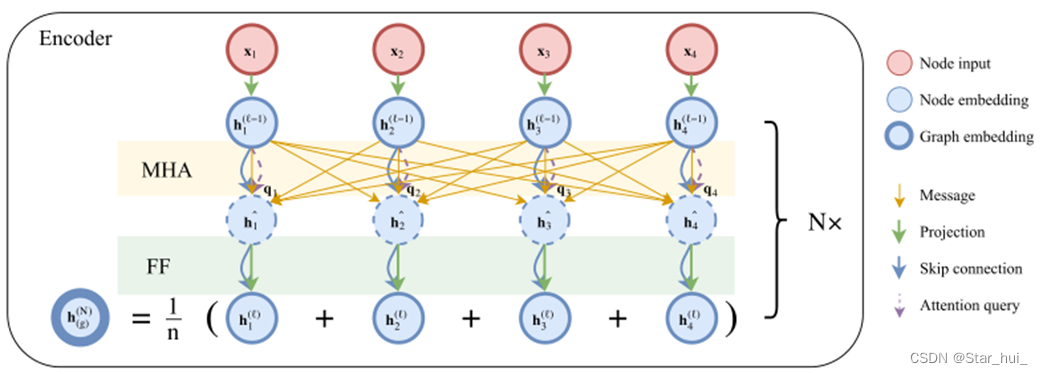
编码器首先通过线性映射,然后使用N层注意力层更新嵌入。每一层由两个子层组成,分别是多头注意力层(MHA)和全连接前馈层(FF),对于每个子层,还添加跳跃链接(skip-connection)和批量归一化层(BN)。最后计算图嵌入。
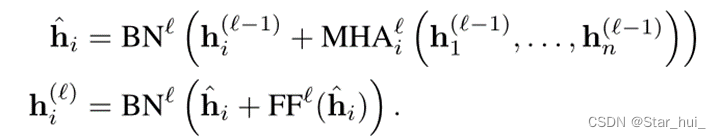
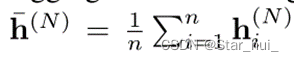
4、解码器
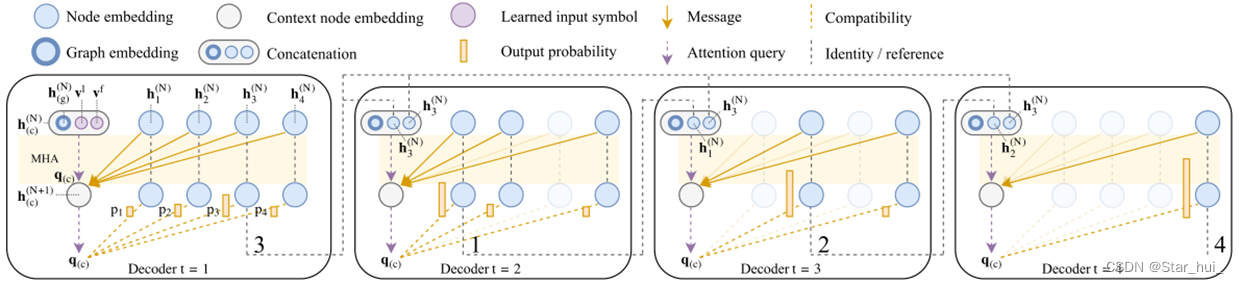 上下文节点c:解码器在t时刻的上下文有两个源头,一是编码器,二是直到t时刻的输出。每一个TSP问题,由三个部分组成:图嵌入, 初始点、终点(t=1,使用可学习占位符)。
上下文节点c:解码器在t时刻的上下文有两个源头,一是编码器,二是直到t时刻的输出。每一个TSP问题,由三个部分组成:图嵌入, 初始点、终点(t=1,使用可学习占位符)。















 906
906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









