







Deep Reinforcement Learning for Solving the Heterogeneous Capacitated Vehicle Routing Problem
1、背景
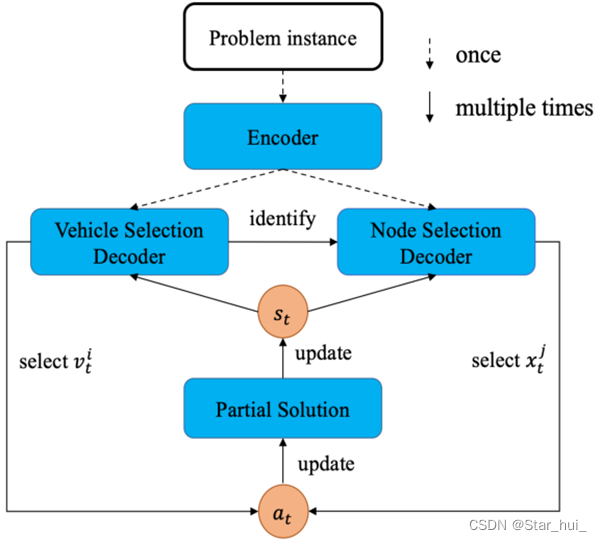
本文提出了一种基于注意机制的DRL方法,来解决具有多个异构车辆的CVRP问题。其中车辆选择解码器负责异构车队约束,节点选择解码器负责路线构建,它通过在每个步骤中自动选择车辆和该车辆的节点来学习构造解决方案。
2、基于注意力机制的DRL模型
编码器处理问题特征。
策略网络首先根据所有车辆和部分路线的状态使用车辆选择解码器从车队中选择车辆,然后在每个解码步骤使用节点选择解码器为该车辆选择一个节点。
选定的车辆和节点都构成该步骤中的动作at,其中部分解和状态会相应更新。
对于单个实例,编码器执行一次,而车辆和节点选择解码器执行多次以构造解决方案。
3、策略网络架构
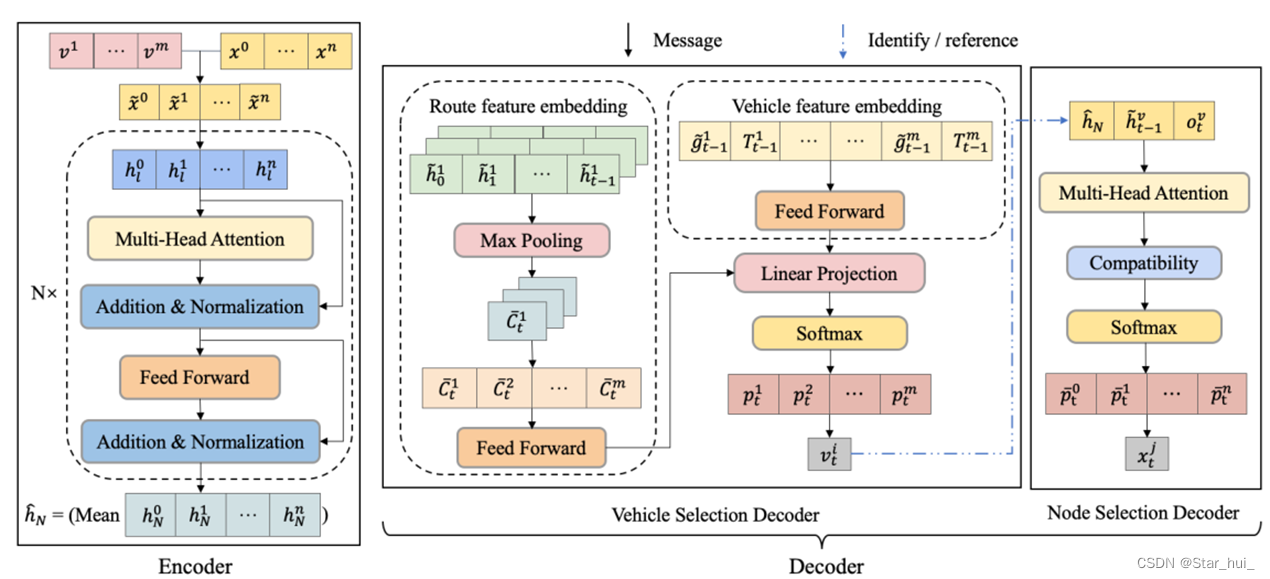
4、编码器
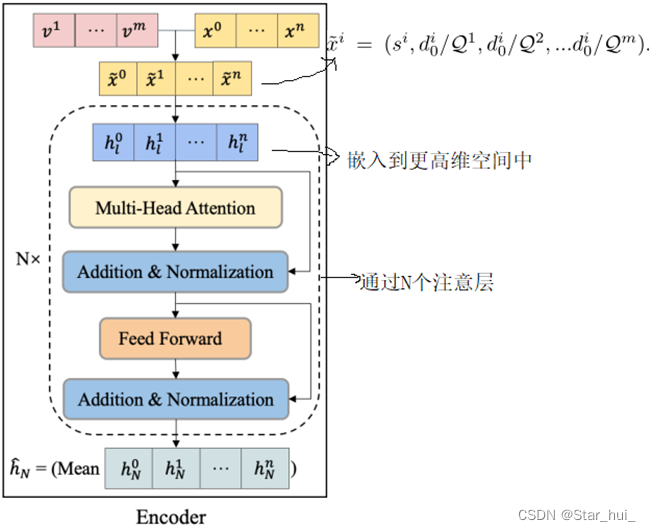
将问题实例的原始特征(即客户位置、客户需求和车辆容量)嵌入到更高维空间中,然后通过注意力层对其进行处理
计算每个头部y的注意力值Zl,然后将所有这些头连接起来,将MHA子层的输出送到第FF子层,MHA和FF子层都使用跳跃连接和BN层,最终,求节点嵌入的平均值,作为问题实例的图形嵌入,将在解码器中多次重复使用

5、解码器
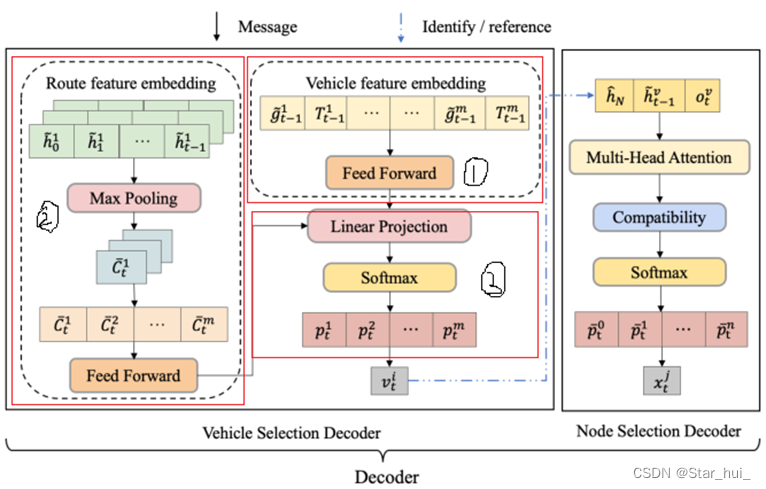

解码器由两部分组成,即车辆选择解码器线和节点选择解码器。
车辆选择解码器输出选择特定车辆的概率分布,主要利用两种嵌入,即车辆特征嵌入(最后一个节点位置和累计行程时间)和路线特征嵌入(m辆车的最大路线集合)。















 4294
4294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









