







7.1 数据追加df.append()
7.1.1 基本语法
df.append(self, other, ignore_index=False, vertify_integrity=False, sort=False)
# other:调用方要追加的其他DataFrame或者类似序列内容。
可以放入一个由DataFrame组成的列表,将所有DataFrame追加起来。
# ignore_index:如果为True,则重新进行自然索引。
# verify_integrity:如果为True,则遇到重复索引内容时报错。
# sort:排序
7.1.2 相同结构
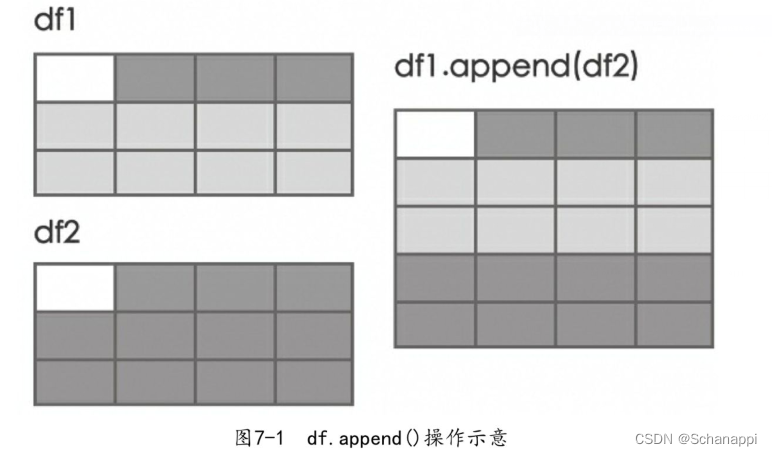
如果数据的字段相同,直接使用第一个DataFrame的append()方法,传入第二个DataFrame。如果需要追加多个DataFrame,可以将它们组成一个列表再传入。
df1.append(df2) 追加一个
df1.append([df2, df2, df2]) # 追加多个
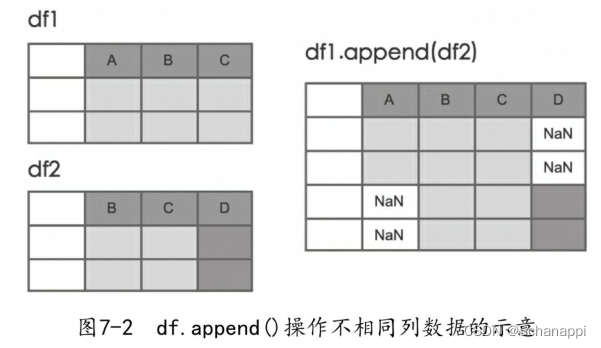
7.1.3 不同结构
对于不同结构的追加,一方有而另一方没有的列会增加,没有内容的位置会用NaN来填充。
7.1.4 忽略索引
追加操作索引默认为原数据的,不会改变,如果需要忽略,可以传入ignore_index=True,此时索引会重新排列。
或者,可以根据自己需要重新设置索引。
7.1.5 重复内容
重复内容默认是可以追加的,如果传入vetify_integrity=True,则会检测追加内容是否重复,如果重复会报错。
7.1.6 追加序列
append除了追加DataFrame外,还可以追加一个Series,经常用于数据添加更新场景。
# eg:追加一名新同学信息
lily = pd.Series(['lily', 'C', 55, 56, 57, 58], index=['name', 'team', 'Q1', 'Q2', 'Q3', 'Q4'])
df = df.append(lily, ignore_index=True) # 并重新排列索引
7.1.7 追加字典
append还可以追加字典。
lily = {'name':lily, 'team':'C', 'Q1':55, 'Q2':56, 'Q3':57, 'Q4':58}
df = df.append(lily, ignore_index=True) # 并重新排列索引
7.2 数据连接pd.concat
7.2.1 基本语法
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, sort=False, verify_integrity=False, copy=True)
# objs:需要连接的数据,可以是多个DataFrame或者Series。它是必传参数。
# axis:连接轴的方法,默认值是0,按列连接,追加在行后面。值为1时追加到列后面。
# join:合并方式。其它轴上的数据是按交集(inner)还是并集(outer)进行合并。
# ignore_index:是否保留原来的索引。
# keys:连接关系,使用传递的键作为最外层级别来构造层次结构索引,就是给每个表指定一个一级索引。
# names:索引名称,包括多层索引。
# verify_integrity:是否检测内容重复。参数为True时,如果合并数据与原数据包含索引相同的行,会报错。
# copy:如果为False,则不要深拷贝。
# pd.concat返回一个合并后的DataFrame
7.2.2 简单连接
pd.concat()的基本操作可以实现df.append()功能:
pd.concat([df1, df2])
df1.append(df2) # 效果同上
7.2.3 按列连接
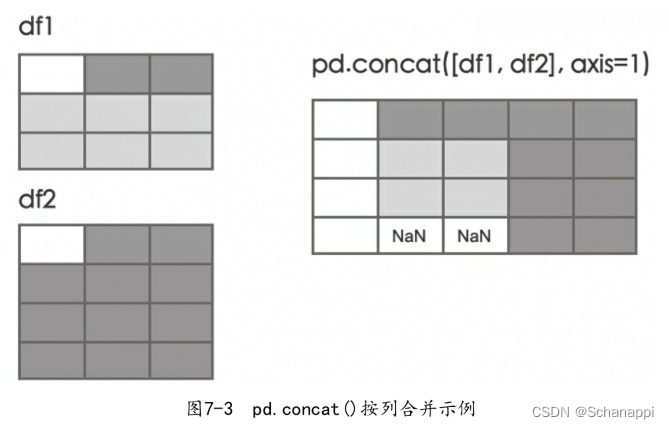
如果要将多个DataFrame按列拼接在一起,可以传入axis=1参数,这会将不同的数据追加到列的后面,索引无法对应的位置上将值填充为NaN。
此操作会得到两个表内容的并集(默认是join=‘outer’)。
# df1 df2
x y x y
0 1 3 0 5 7
1 2 4 1 6 8
2 0 0
pd.concat([df1, df2], axis=1)
# new
x y x y
0 1 3 5 7
1 2 4 6 8
2 NaN NaN 0 0
7.2.4 合并交集
# 按列合并交集,保留共有部分
pd.concat([df1, df2], axis=1, join='inner')
# df1 df2
x y x y
0 1 3 0 5 7
1 2 4 1 6 8
2 0 0
# new
x y x y
0 1 3 5 7
1 2 4 6 8
另外,reindex()方法也可以实现以上取交集功能:
# 两种方法
pd.concat([df1, df2], axis=1).reindex(df1.index)
pd.concat([df1, df2.reindex(df1.reindex)], axis=1)
7.2.5 与序列合并
z = pd.Series([9, 9], name='z')
# 将序列添加到新列
pd.concat([df1, z], axis=1)
但是,还是建议使用df.assign()来指定一个新列,逻辑会更加简单:
df.assign(z=z)
7.2.6 指定索引
可以再给每个表一个一级索引,形成多层索引。
# 指定索引名
pd.concat([df1, df2], keys=['a', 'b'])
x y
a 0 1 3
1 2 4
b 0 5 7
1 6 8
# 以字典形式传入
pieces = {'a': df1, 'b': df2}
pd.concat(pieces) # 效果同上
# 横向合并,指定索引
pd.concat([df1, df2], axis=1, keys=['a', 'b'])
a b
x y x y
0 1 3 5 7
1 2 4 6 8
7.2.7 多文件合并
最简单的方法是先把数据一个一个取出来,然后合并:
# 通过各种方式读取数据
df1 = pd.DataFrame(data1)
df2 = pd.read_excel('tmp.xlsx')
df3 = pd.read_csv('tmp.csv')
# 合并数据
merged_df = pd.concat([df1, df2, df3])
注意,不要一个表格用一次concat,这样性能很差,可以先把所有表格添加到列表里,然后一次性合并:
# process_your_file(f)方法将文件读取为DataFrame
frames = [process_your_file(f) for f in files]
# 合并
result = pd.concat(frames)
7.2.8 目录文件合并
有时会将体量较大的数据分片放到同一个硬盘目录下,在使用时进行合并。可以使用官方库glob来识别目录文件:
import glob
# 取出目录下所有XLSX格式的文件
files = glob.glob("data/*.xlsx")
cols = ['ID', '时间', '名称'] # 只取这些列
# 列表推导出对象
dflist = [pd.read_excel(i, usecols=cols) for i in files]
df = pd.concat(dflist) # 合并
使用Python内置map函数进行操作:
# 使用pd.read_csv逐一读取文件,然后合并
pd.concat(map(pd.read_csv, ['data/d1.csv', 'data/d2.csv', 'data/d3.csv']))
# 使用pd.read_excel逐一读取文件,然后合并
pd.concat(map(pd.read_excel, ['data/d1.xlsx', 'data/d2.xlsx', 'data/d3.xlsx']))
以下是一些其他方法:
# 目录下的所有文件
from os import listdir
filepath = [f for f in listdir("./data") if f.endwith('.csv')]
df = pd.concat(map(pd.read_csv, filepaths))
# 其他方法
import glob
df.concat(map(pd.read_csv, glob.glob('data/*.csv')))
df.concat(map(pd.read_excel, glob.glob('data/*.xlsx')))
在实际使用中。熟练掌握其中一个即可。
7.3 数据合并pd.merge
7.3.1 基本语法
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
# 可以将两个DataFrame或Series合并,最终返回合并后的DataFrame。
# left、right:需要连接的两个DataFrame或Series,一左一右。
# how:数据连接方式,默认为inner,还可以设置为outer、left或right。
# on:作为连接键的字段,左右数据中都必须存在,否则需要用left_on和right_on来指定。
# left_on:左表的连接键字段。
# right_on:右表的连接键字段。
# left_index:为True时将左表的索引作为连接键,默认为False。
# right_index:为True时将右表的索引作为连接键,默认为False。
# suffixes:如果左右数据出现重复列,新数据表头会用此后缀进行区分,默认为_x和_y。
7.3.2 连接键
在数据连接时,如果没有指定根据哪一列(连接键)进行连接,Pandas会自动找到相同列名的列进行连接,并按左边数据的顺序取交集数据。为了代码的可阅读性和严谨性,推荐通过on参数指定连接键。
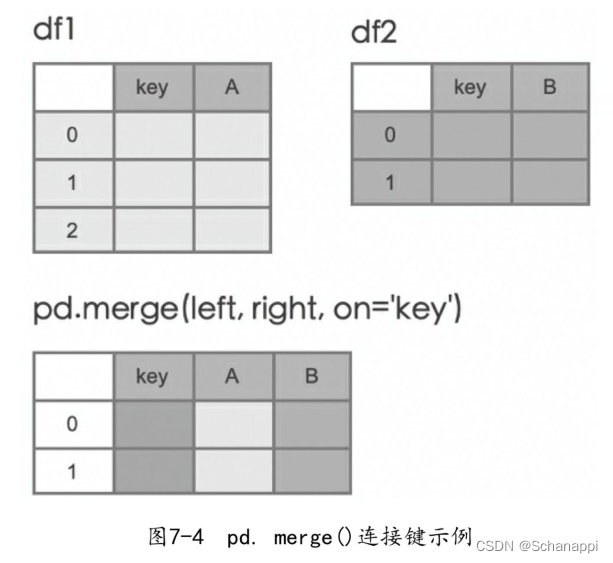
df1 = pd.DataFrame({'a': [1, 2], 'x':[5, 6]})
df2 = pd.DataFrame({'a': [2, 1, 0], 'y':[6, 7 ,8]})
pd.merge(df1, df2, on='a')
# df1 df2
a x a y
0 1 5 0 2 6
1 2 6 1 1 7
2 0 8
# new 注意要按df1的a连接值确定值的位置
a x y
0 1 5 7
1 2 6 6
7.3.3 索引连接
可以直接按索引进行连接,将left_index和right_index设置为True,会以两个表的索引作为连接键。
pd.merge(df1, df2, left_index=True, right_index=True, suffixes=('_1', '_2'))
# new
a_1 x a_2 y
0 1 5 2 6
1 2 6 1 7
本例中,两个表都有同名的a列,用suffixes参数设置了后缀来区分。
7.3.4 多连接键
如果在合并数据时需要用到多个连接键,可以以列表的形式将这些连接键传入on中。
pd.merge(df1, df2, on=['a', 'b']) # a列和b列都作为连接键
7.3.5 连接方法
how参数可以指定数据的合并方法,可以设置为inner、outer、left或right。
默认方式是inner join,取交集,也就是保留左、右表的共同内容;如果是left join,左边表所有内容保留;如果是right join,右边表的所有内容保留;如果是outer join,则左右表所有内容都保留。关联不上的内容为NaN。
# 有重复连接键
left = pd.DataFrame({'A':[1, 2], 'B':[2, 2]})
right = pd.DataFrame({'A':[4, 5, 6], 'B':[2, 2 ,2]})
pd.merge(left, right, on='B', how='outer')
# new
A_x B A_y
0 1 2 4
1 1 2 5
2 1 2 6
3 2 2 4
4 2 2 5
5 2 2 6
7.3.6 连接指示
如果想知道数据连接后是左表内容还是右表内容,可以使用indicator参数显示连接方式。如果将indicator设置为True,则会增加名为_merge的列,显示这列是从何而来。
_merge列有以下三个取值:
- left_only:只在左表中;
- right_only:只在右表中;
- both:两者都有。
# 显示连接指示列
pd.merge(df1, df2, on='a', how='outer', indicator=True)
# new
a x y _merge
0 1 5.0 7 both
1 2 6.0 6 both
2 0 NaN 8 right_only
7.4 按元素合并
在数据合并过程中,需要对对应位置的数值进行计算,比如相加、平均、对空值补齐等,Pandas提供了df.combine_first()和df.combine()等方法。
7.4.1 df.combine_first()
使用相同位置的值更新空元素,只有在df1有空元素时才能替换值。如果数据结构不一致,所得DataFrame的行索引和列索引将是两者的并集。
# eg1:df1的A和B的空值将被df2相同位置的值替换
df1 = pd.DataFrame({'A':[None, 1], 'B':[None, 2]})
df2= pd.DataFrame({'A':[3, 3], 'B':[4, 4]})
df1.combine_first(df2)
df1 df2
A B A B
0 NaN NaN 0 3 4
1 1.0 2.0 1 3 4
# new
A B
0 3.0 4.0
1 1.0 2.0
# eg2:df1的A中的空值由于没有B中相同位置的值来替换,仍然为空
df1 = pd.DataFrame({'A':[None, 1], 'B':[None, 2]})
df2= pd.DataFrame({'A':[3, 3], 'C':[4, 4]}, index=[1, 2])
df1.combine_first(df2)
df1 df2
A B A C
0 NaN NaN 1 3 4
1 1.0 2.0 2 3 4
# new
A B
0 NaN NaN
1 1.0 2.0
2 3.0 4.0
7.4.2 df.combine()
可以与另一个DataFrame进行按列组合。使用函数通过计算将一个DataFrame与其他DataFrame合并,以逐元素方式合并列。所得DataFrame的行索引和列索引将是两者的并集。这个函数中有两个参数,分别是两个df中对应的Series,计算后返回一个Series或标量。
# eg:合并时取对应位置大的值作为合并结果
df1 = pd.DataFrame({'A':[1, 2], 'B':[3, 4]})
df2= pd.DataFrame({'A':[0, 3], 'B':[2, 1]})
df1.combine(df2, lambda s1, s2: np.where(s1>s2, s1, s2)) # 返回大的值
也可以直接使用Numpy的函数:
df1.combine(df2, np.maximum) # 取最大值
df1.combine(df2, np.minimum) # 取最小值
7.4.3 df.update()
可以使用来自另一个DataFrame的非NaN值来修改DataFrame,而原DataFrame被更新。
df1 = pd.DataFrame({'a':[None, 2], 'b':[5, 6]})
df2= pd.DataFrame({'a':[0, 2], 'b':[None, 7]})
df1.update(df2) # df1已经更新,如果不想更新df1,传入参数overwrite=True
df1 df2
a b a b
0 NaN 5 0 0 NaN
1 2.0 6 1 2 7.0
# df1
a b
0 0.0 5.0
1 2.0 7.0
7.5 数据对比df.compare
7.5.1 简单对比
注意,只能对比形状相同的两个数据。
# eg1
df1 = pd.DataFrame({'a':[1, 2], 'b':[5, 6]})
df2 = pd.DataFrame({'a':[0, 2], 'b':[5, 7]})
df1.compare(df2)
"""
a b
self other self other
0 1.0 0.0 NaN NaN
1 NaN NaN 6.0 7.0
"""
# 只关心差异部分,self和other分别显示数值用于对比
# 相同部分用NaN表示
# eg2
df1 = pd.DataFrame({'a':[1, 2], 'b':[5, 6]})
df2 = pd.DataFrame({'a':[1, 2], 'b':[5, 7]})
df1.compare(df2)
"""
b
self other
1 6.0 7.0
"""
# a列数据相同,不显示,仅显示不同的b列第二行
7.5.2 对齐方式
默认情况下,将不同的数据显示在列方向上,还可以传入参数align_axis=0将不同数据显示在行方向上:
df1 = pd.DataFrame({'a':[1, 2], 'b':[5, 6]})
df2 = pd.DataFrame({'a':[0, 2], 'b':[5, 7]})
df1.compare(df2, align_axis=0)
"""
a b
0 self 1.0 NaN
other 0.0 NaN
1 self NaN 6.0
other NaN 7.0
"""
7.5.3 显示相同值
在对比时,传入参数keep_equal=True,可以将相同的值显示出来:
df1 = pd.DataFrame({'a':[1, 2], 'b':[5, 6]})
df2 = pd.DataFrame({'a':[0, 2], 'b':[5, 7]})
df1.compare(df2, keep_equal=True)
"""
a b
self other self other
0 1 0 5 5
1 2 2 6 7
"""
7.5.4 保持形状
为了方便知道不同的数据的位置,可以传入参数keep_shape=True来显示原来数据的形态,不过相同数据会被替换为NaN来占位:
df1 = pd.DataFrame({'a':[1, 2], 'b':[5, 6]})
df2 = pd.DataFrame({'a':[1, 2], 'b':[5, 7]})
df1.compare(df2, keep_shape=True)
"""
a b
self other self other
0 NaN NaN NaN NaN
1 NaN NaN 6.0 7.0
"""
如果想看到原始值,可以同时传入keep_equal=True:
df1.compare(df2, keep_shape=True, keep_equal=True)
"""
a b
self other self other
0 1 1 5 5
1 2 2 6 7
"""
7.6 本章小结
本章介绍了数据的合并和对比操作,对比非常简单,用df.compare操作可以清晰地看到两个数据之间的差异。
合并有df.append()和pd.concat()、pd.merge()三个方法:
- df.append()适合在原数据上做简单的追加,一般用于数据内容的追加;
- pd.concat()\既可以合并多个数据,也可以合并多个数据文件;
- pd.merge()可以做类似SQL语句中的join操作。
以上几个方法可以整理多个数据并合并成一个完整的DataFrame,以便我们对数据进行整体分析。














 8267
8267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









