







数据的重塑不是简单的形式变换,而是数据表达的逻辑转换,透视则是常用的数据重塑手段。
9.1 数据透视
数据透视表,可以找出大量复杂无关的数据的内在关系,将数据转化为有意义、有价值的信息,从而看到它所代表的事物的规律和本质。
9.1.1 整理透视
df.pivot()返回给定的索引、列值重新组织整理后的DataFrame,能够实现基本的透视操作。
df.pivot()有三个参数:
# index:作为新DataFrame的索引,取分组去重的值;如果不传入,则取现有索引。
# columns:作为新DataFrame的列,取去重的值,当列和索引的组合含有多个值的时候会报错,
需要使用pd.pivot_table()进行操作。
# values:作为新DataFrame的值,如果指定多个,会形成多层索引;
如果不指定,会默认所有剩余的列。
9.1.2 整理透视操作
# 构造数据
df = pd.DataFrame({
'A': ['a1', 'a1', 'a2', 'a2', 'a3', 'a3'],
'B': ['b1', 'b2', 'b3', 'b1', 'b2', 'b3'],
'C': ['c1', 'c2', 'c3', 'c4', 'c5', 'c6'],
'D': ['d1', 'd2', 'd3', 'd4', 'd5', 'd6']
})
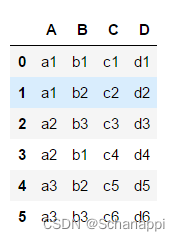
df.pivot(index='A', columns='B', values='C')
上面代码取A列的去重值作为索引,取B列的去重值作为列,取C列的内容作为具体数据值。两个轴的交叉处的取值方法是原表中A与B对应C列的值,如果无值则显示NaN。
如果需要除了索引和列外的值,可以不传入values(默认剩余所有列):
# 不指定值内容
df.pivot(index='A', columns='B')
# 指定多列值
df.pivot(index='A', columns='B', values=['C', 'D']) # 效果同上

9.1.3 聚合透视
pd.pivot_table()在df.pivot()的基础上,还能在数据透视中对值进行计算。
pd.pivot_table()参数如下:
# data:要透视的DataFrame对象。
# index:在数据透视表索引上进行分组的列。
# values:要聚合的一列或多列。
# columns:在数据透视表列上进行分组的列。
# aggfunc:用于聚合的函数,默认是平均数mean。
# fill_value:透视会以空值填充值。
# margins:是否增加汇总行列。
9.1.4 聚合透视操作
# 构造数据
df = pd.DataFrame({
'A': ['a1', 'a1', 'a1', 'a2', 'a2', 'a2'],
'B': ['b2', 'b2', 'b1', 'b1', 'b1', 'b1'],
'C': ['c1', 'c1', 'c2', 'c2', 'c1', 'c1'],
'D': [1, 2, 3, 4, 5, 6]
})

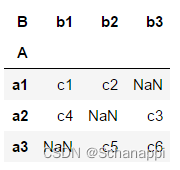
如果对上述数据进行以A为索引、以B为列的整理透视df.pivot()操作,会报错,因为索引和列组合后有重复数据。
需要将这些重复数据按一定算法计算出来,pd.pivot_table()默认算法是取平均值:
pd.pivot_table(df, index='A', columns='B', values='D')
"""
B b1 b2
A
a1 3.0 1.5
a2 5.0 NaN
"""
9.1.5 聚合透视高级操作
# 高级聚合
pd.pivot_table(df, index=['A', 'B'], # 指定多个索引
columns=['C'], # 指定列
values='D', # 指定数据值
aggfunc=np.sum, # 指定聚合方法为求和
fill_value=0, # 将聚合为空的值填充为0
margins=True # 增加行列汇总 即All
)

# 使用多个聚合计算
pd.pivot_table(df, index=['A', 'B'], # 指定多个索引
columns=['C'], # 指定列
values='D', # 指定数据值
aggfunc=[np.mean, np.sum] # 指定多个聚合方法
)
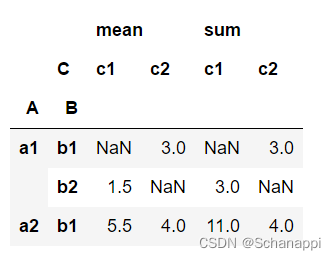
# 如果有多个数据列,可以为每一列指定不同的计算方法
# 构造数据
df = pd.DataFrame({
'A': ['a1', 'a1', 'a1', 'a2', 'a2', 'a2'],
'B': ['b2', 'b2', 'b1', 'b1', 'b1', 'b1'],
'C': ['c1', 'c1', 'c2', 'c2', 'c1', 'c1'],
'D': [1, 2, 3, 4, 5, 6],
'E': [9, 8, 7, 6, 5, 4]
})
pd.pivot_table(df, index=['A', 'B'], # 指定多个索引
columns=['C'], # 指定列
aggfunc={'D': np.mean, 'E': np.sum} # 为每列指定聚合方法
)
9.1.6 小结
本节介绍了Pandas如何进行透视操作。df.pivot()是对数据进行整理,变换显示方式,而pd.pivot_table()会在整理的基础上对重复数据进行相应的计算。
9.2 数据堆叠
9.2.1 理解堆叠
数据堆叠可以理解成多列数据转为一列数据。如果原始数据有多个数据列,堆叠(stack)的过程表示将这些数据列的所有数据表全部旋转在行上;类似地,解堆(unstack)的过程表示将在行上的索引旋转到列上。解堆是堆叠的相反操作。
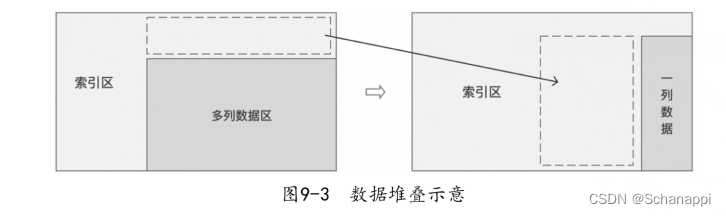
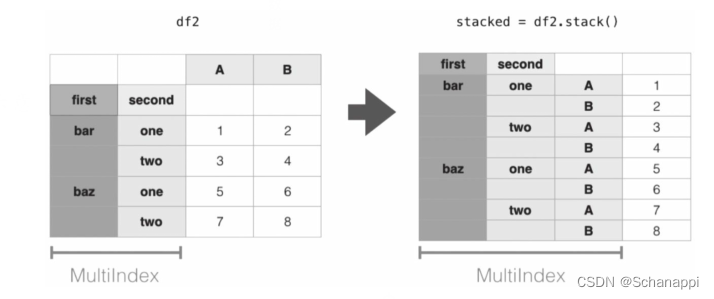
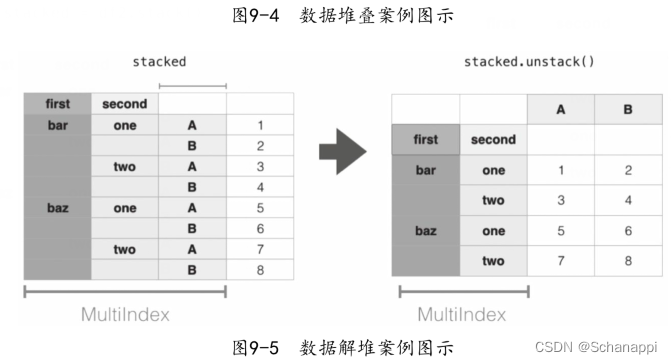
- 堆叠:“透视”某个级别的列标签,返回带有索引的DataFrame,该索引带有一个新的行标签,这个新标签在原有索引的最右边。列->行
- 解堆:将(可能是多层的)行索引的某个级别“透视”到列轴,从而生成具有新的最里面的列标签级别的重构DataFrame。 行->列
9.2.2 堆叠操作df.stack()
# 构造一个A、B两层的多层索引数据
# 构造数据
df = pd.DataFrame({
'A': ['a1', 'a1', 'a2', 'a2'],
'B': ['b1', 'b2', 'b1', 'b2'],
'C': [1, 2, 3, 4],
'D': [5, 6, 7, 8],
'E': [5, 6, 7, 8]
})
# 设置多层索引
df.set_index(['A', 'B'], inplace=True)
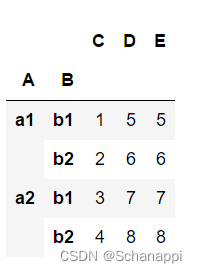
# 堆叠
df.stack()
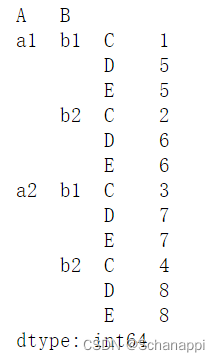
# 查看类型
type(df.stack())
# pandas.core.series.Series
# 生成了一个Series,所有的列都透视在了多层索引的新增列中
9.2.3 解堆操作
# 将原来的数据堆叠并赋值给s
s = df.stack()
# 解堆
s.unstack()
# 生成一个DataFrame
9.3 交叉表
交叉表(cross tabulation)是一个很有用的分析工具,用于统计分组频率的特殊透视表。交叉表能将两列或多列中不重复的元素组成一个新的DataFrame,新数据的行和列的交叉部分的值为其组成在原数据中的数量。
9.3.1 基本语法
pd.crosstab(index, columns, values=None, rownames=None, colnames=None,
aggfunc=None, margins=False, margins_name: str = 'All',
dropna: bool = True, normalize=False)
# index:传入列,作为新数据的索引。
# columns:传入列,作为新数据的列,新数据的列为此列的去重值。
# values:可选,传入列,根据此列的数值进行计算,计算方法取aggfunc参数指定的方法,此时为必传参数。
# aggfunc:函数,values列计算使用的计算方法。
# rownames:新数据和行名,一个序列,默认为None,必须与传递的行数、组数匹配。
# colnames:新数据和列名,一个序列,默认为None;如果传递,必须与传递的列数、 组数匹配。
# margins:布尔值,默认值为False,添加行/列距。
# normalize:布尔值,{'all', 'index', 'columns'}或{0, 1},默认为False。
通过将所有值除以值的总和进行归一化。
9.3.2 生成交叉表
# 原数据
df = pd.DataFrame({
'A': ['a1', 'a1', 'a2', 'a2', 'a1'],
'B': ['b2', 'b1', 'b2', 'b2', 'b1'],
'C': [1, 2, 3, 4, 5]
})
# 生成交叉表
pd.crosstab(df['A'], df['B'])
"""
B b1 b2
A
a1 2 1
a2 0 2
"""
# 交叉位上对应的值为此组合的数量
# 对分类数据做交叉
one = pd.Categorical(['a', 'b'], categories=['a', 'b', 'c'])
two = pd.Categorical(['d', 'e'], categories=['d', 'e', 'f'])
pd.crosstab(one, two)
"""
col_0 d e
row_0
a 1 0
b 0 1
"""
9.3.3 归一化
normalize参数可以实现数据归一化,算法为对应值除以所有值的总和,让数据处于0~1的范围。
# 原交叉表
pd.crosstab(df['A'], df['B'])
"""
B b1 b2
A
a1 2 1
a2 0 2
"""
# 交叉表归一化
pd.crosstab(df['A'], df['B'], normalize=True)
"""
B b1 b2
A
a1 0.4 0.2
a2 0.0 0.4
"""
# 对列归一化
pd.crosstab(df['A'], df['B'], normalize='columns')
"""
B b1 b2
A
a1 1.0 0.333333
a2 0.0 0.666667
"""
9.3.4 指定聚合方法
用aggfunc指定聚合方法对values指定的列进行计算:
# 按C列的和进行求和聚合 pd.pivot_table()也可以实现该效果
pd.crosstab(df['A'], df['B'], values=df['C'], aggfunc=np.sum)
"""
B b1 b2
A
a1 7.0 1.0
a2 NaN 7.0
"""
9.3.5 汇总
margins=True可以增加行和列的汇总,按照行列方法对数据求和,类似margins_name='total’可以定义这个汇总行和列的名称:
# 交叉表,增加汇总
pd.crosstab(df['A'], df['B'], values=df['C'], aggfunc=np.sum,
margins=True, margins_name='total')
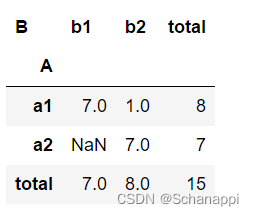
9.3.6 小结
交叉表将原始数据中的两个列铺开,形成这两列所有不重复值的交叉位,在交叉位上填充这个值在原始数据中的组合数。
9.4 数据转置df.T
数据转置是指将数据的行与列进行互换,它会使数据的形状和逻辑发生变化。
9.4.1 理解转置
转置是将数据沿着左上和右下形成的对角线进行翻转。
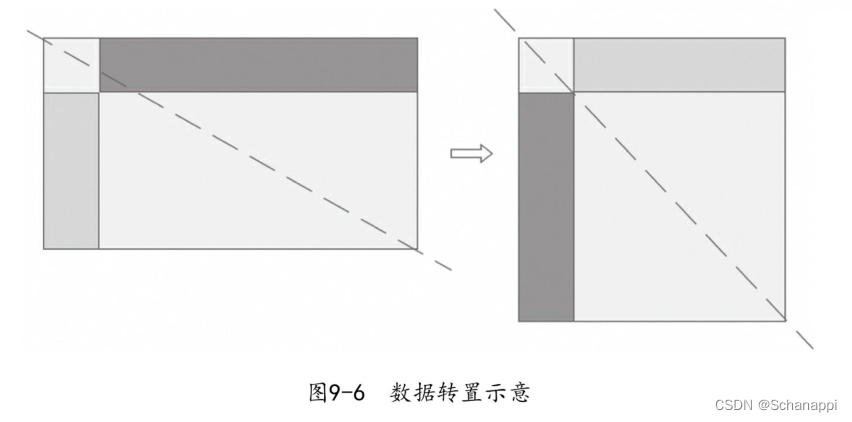
9.4.2 转置操作
df.T属性是df.transpose()方法的简写形式。
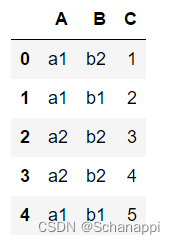
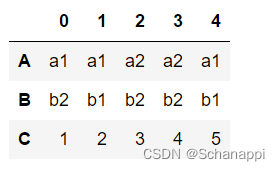
# 原数据
df = pd.DataFrame({
'A': ['a1', 'a1', 'a2', 'a2', 'a1'],
'B': ['b2', 'b1', 'b2', 'b2', 'b1'],
'C': [1, 2, 3, 4, 5]
})
# 转置
df.T
Series也支持转置,不过它返回的是自己,没有变化。
9.4.3 类型变化
一般情况下数据转置后,列的数据类型会发生变化:
# 原始数据类型
df.dtypes
"""
A object
B object
C int64
dtype: object
"""
# 转置后的数据类型
df.T.dtypes
"""
0 object
1 object
2 object
3 object
4 object
dtype: object
"""
9.4.4 轴交换df.swapaxes()
df.swapaxes(axis1, axis=2, copy=True)用来进行轴(行列)交换,如果是进行行列交换,那就相当于df.T。
df.swapaxes("index", "columns") # 行列交换,df.T
df.swapaxes("columns", "index") # 同上
df.swapaxes("index", "columns", copy=True) # 使生效
df.swapaxes("columns", "columns") # 无变化
df.swapaxes("index", "columns") # 无变化
9.5 数据融合
df.melt()是df.pivot()的逆操作函数,将指定的列铺开,放到行上名为variable(可指定)、值为value(可指定)的列。
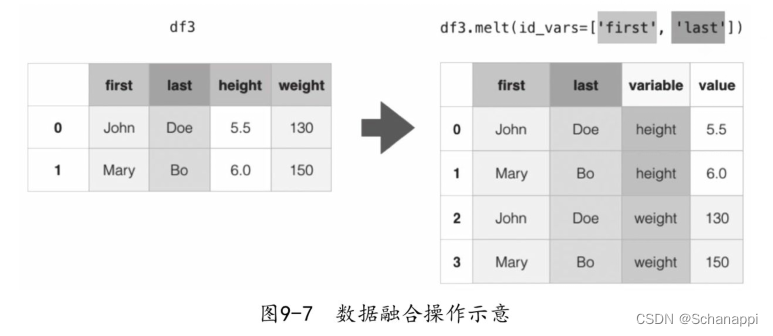
9.5.1 基本语法
df.melt(frame: pandas.core.frame.DataFrame,
id_vars=None, value_vars=None, var_name='variable', value_name='value',
col_level=None)
# id_vars:tuple、list或ndarray,用作标识变量的列。
# value_vars:tuple、list或ndarray,要取消透视的列。如果没有指定,
则使用未设置为id_vars的所有列。
# var_name:scalar,用于“变量”列的名称。如果为None,则使用frame.columns.name或“variable”。
# value_name:scalar,默认为“value”,用于“value”列的名称。
# col_level:int或str,如果列是多层索引,则使用此级别来融合。
9.5.2 融合操作
# 原数据
df = pd.DataFrame({
'A': ['a1', 'a2', 'a3', 'a4', 'a5'],
'B': ['b1', 'b2', 'b3', 'b4', 'b5'],
'C': [1, 2, 3, 4, 5]
})
# 数据融合
pd.melt(df) # 没有指定id_vars,所有列都取消透视
"""
variable value
0 A a1
1 A a2
2 A a3
3 A a4
4 A a5
5 B b1
6 B b2
7 B b3
8 B b4
9 B b5
10 C 1
11 C 2
12 C 3
13 C 4
14 C 5
"""
9.5.3 标识和值
# 指定标识,只对C列展开数据
pd.melt(df, id_vars=['A', 'B'])
"""
A B variable value
0 a1 b1 C 1
1 a2 b2 C 2
2 a3 b3 C 3
3 a4 b4 C 4
4 a5 b5 C 5
"""
# 指定值列,其他列(A)被忽略
pd.melt(df, value_vars=['B', 'C'])
"""
variable value
0 B b1
1 B b2
2 B b3
3 B b4
4 B b5
5 C 1
6 C 2
7 C 3
8 C 4
9 C 5
"""
9.5.4 指定名称
# 指定标识和值列的名称
pd.melt(df, id_vars=['A'], value_vars=['B'], var_name='B_label', value_name='B_value')
"""
A B_label B_value
0 a1 B b1
1 a2 B b2
2 a3 B b3
3 a4 B b4
4 a5 B b5
"""
9.6 虚拟变量
虚拟变量(Dummy Variable)又称虚设变量、名义变量或哑变量,是一个用来反映质的属性的人工变量,是量化了的自变量,通常取值为0或1,常用于one-hot特征提取。
9.6.1 语法结构
pd.get_dummies()能够生成虚拟变量,将一列或多列的去重值作为新表的列,每列的值由0和1组成:如果原来位置的值与列名相同,则在新表中该位置的值为1,否则为0。这样就形成了一个由0和1组成的特征矩阵。
pd.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False,
columns=None, sparse=False, drop_first=False, dtype=None)
# data:被操作的数据,DataFrame或Series。
# prefix:新列的前缀。
# prefix_sep:新列前缀的连接符。
9.6.2 生成虚拟变量
# 原数据
df = pd.DataFrame({'a': list('abcd'),
'b': list('fehg'),
'a1': range(4),
'b1': range(4, 8)})
"""
a b a1 b1
0 a f 0 4
1 b e 1 5
2 c h 2 6
3 d g 3 7
"""
# 生成虚拟变量
pd.get_dummies(df.a)
"""
a b c d
0 1 0 0 0
1 0 1 0 0
2 0 0 1 0
3 0 0 0 1
"""
只关注df.a列:a列一共有a、b、c、d四个值,因此新数据有这四列;索引和列名交叉的位置如果为1,说明此索引位上的值为列名,为0则表示不为列名。
9.6.3 列前缀
有的原数据的部分列的值为纯数字,为了方便使用,需要给生成虚拟变量的列名增加一个前缀,用prefix来定义。
# 生成虚拟变量
pd.get_dummies(df['a1'], prefix='a1')
"""
a1_0 a1_1 a1_2 a1_3
0 1 0 0 0
1 0 1 0 0
2 0 0 1 0
3 0 0 0 1
"""
9.6.4 从DataFrame生成
可以直接对DataFrame生成虚拟变量,会将所有非数字列生成虚拟变量(数字列保持不变):
# 生成虚拟变量
pd.get_dummies(df)
"""
a1 b1 a_a a_b a_c a_d b_e b_f b_g b_h
0 0 4 1 0 0 0 0 1 0 0
1 1 5 0 1 0 0 1 0 0 0
2 2 6 0 0 1 0 0 0 0 1
3 3 7 0 0 0 1 0 0 1 0
"""
# 只指定一列
# 只生成b列的虚拟变量
pd.get_dummies(df, columns=['b'])
"""
a a1 b1 b_e b_f b_g b_h
0 a 0 4 0 1 0 0
1 b 1 5 1 0 0 0
2 c 2 6 0 0 0 1
3 d 3 7 0 0 1 0
"""
9.6.5 小结
虚拟变量生成操作将数据进行变形,形成一个索引与值(变形后为列)的二维矩阵,在对应交叉位上用1表示有此值,0表示无此值。
虚拟变量经常用于与特征提取相关的机器学习场景。
9.7 因子化
因子化将一个存在大量重复值的一位数据解析成枚举值的过程。factorize既可以用作顶层函数pd.factorize(),也可以用作Series.factorize()和Index.factorize()方法。
9.7.1 基本方法
数据因子化后返回一个由两个元素组成的元组:一个是因子化后的编码列表(code),另一个是原数据的去重列表(uniques)。
# codes:数字编码表,将第一个元素编为0,其后依次用1、2等表示,遇到相同元素使用相同编码,
编码表的长度和原始数据长度相等,用编码对原始数据一一映射。
# uniques:去重值,即因子。
# 数据
data = ['b', 'b', 'a', 'c', 'b']
# 因子化
codes, uniques = pd.factorize(data)
# 编码
codes # array([0, 0, 1, 2, 0], dtype=int64)
# 去重值
uniques # array(['b', 'a', 'c'], dtype=object)
# 对Series操作后唯一值将生成一个index对象
cat = pd.Series(['a', 'a', 'c'])
codes, uniques = pd.factorize(cat)
codes # array([0, 0, 1], dtype=int64)
uniques # Index(['a', 'c'], dtype='object')
9.7.2 排序
使用sort=True参数后将对唯一值进行排序,编码列表将继续与原值保持对应关系,但从值的大小上将体现出顺序。
codes, uniques = pd.factorize(['b', 'b', 'a', 'c', 'b'], sort=True)
codes # array([1, 1, 0, 2, 1], dtype=int64)
uniques # array(['a', 'b', 'c'], dtype=object)
9.7.3 缺失值
缺失值不会出现在唯一值列表中,在编码中为-1。
codes, uniques = pd.factorize(['b', None, 'a', 'c', 'b'])
codes # array([ 0, -1, 1, 2, 0], dtype=int64)
uniques # array(['b', 'a', 'c'], dtype=object)
9.7.4 枚举类型
Pandas的枚举类型数据(Categorical)也可以使用此方法:
cat = pd.Categorical(['a', 'a', 'c'], categories=['a', 'b', 'c'])
codes, uniques = pd.factorize(cat)
codes # array([0, 0, 1], dtype=int64)
uniques # ['a', 'c']
# Categories (3, object): ['a', 'b', 'c']
9.8 爆炸列表
爆炸列表指的是将类似列表的每个元素转换为一行,索引值是相同的。
9.8.1 基本功能
# 原始数据
s= pd.Series([[1, 2, 3], 'foo', [], [3, 4]])
"""
0 [1, 2, 3]
1 foo
2 []
3 [3, 4]
dtype: object
"""
# 爆炸列
s.explode()
"""
0 1
0 2
0 3
1 foo
2 NaN
3 3
3 4
dtype: object
"""
9.8.2 DataFrame的爆炸
# 原始数据
df = pd.DataFrame({'A': [[1, 2, 3], 'foo', [], [3, 4]], 'B': range(4)})
"""
A B
0 [1, 2, 3] 0
1 foo 1
2 [] 2
3 [3, 4] 3
"""
# 爆炸指定列
df.explode('A')
"""
A B
0 1 0
0 2 0
0 3 0
1 foo 1
2 NaN 2
3 3 3
3 4 3
"""
9.8.3 非列表格式
# 原数据
df = pd.DataFrame([{'var1': 'a, b, c', 'var2': 1},
{'var1': 'd, e, f', 'var2': 2}])
"""
var1 var2
0 a, b, c 1
1 d, e, f 2
"""
var1列的数据虽然是按逗号隔开的,但它不是列表,这时先将其处理成列表,再实施爆炸:
# 使用指定同名列的方式对列进行修改
df.assign(var1=df.var1.str.split(',')).explode('var1')
"""
var1 var2
0 a 1
0 b 1
0 c 1
1 d 2
1 e 2
1 f 2
"""
9.9 本章小结
本章介绍了Pandas提供的数据变换操作,通过这些数据变换,可以观察数据的另一面,探究数据反映出的深层次的业务意义。另外一些操作(虚拟变量、因子化)可帮助我们提取出数据特征,为下一步数据建模、数据分析、机器学习打下基础。















 2402
2402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









