






一、实验目的
掌握卷积神经网络的设计原理,掌握卷积神经网络的使用方法,能够使用 Python 语言实现 VGG19网络模型对给定的输入图像进行分类。具体包括:
1) 加深对深度卷积神经网络中卷积层、最大池化层等基本单元的理解。
2) 利用 Python 语言实现 VGG19 的前向传播计算,加深对 VGG19 网络结构的理解。
3) 将三层MLP神经网络扩展为 VGG19 网络,加深对神经网络工程实现中基本模块演变的理解,为后续建立更复杂的综合实验(如风格迁移)奠定基础。
二、实验任务
1)本实验利用 VGG19 网络进行图像分类。首先建立VGG19 的网络结构,然后利用 VGG19
的官方模型参数对给定图像进行分类。 VGG19 网络的模型参数是在 ImageNet数据集上
训练获得,其输出结果对应 ImageNet 数据集中的 1000 个类别概率。
2)在工程实现中,依然按照模块划分方法。由于本实验只涉及 VGG19 网络的推断过程,因此本实验仅包括数据加载模块、基本单元模块、网络结构模块、网络推断模块,不包括网络训练模块。
三、实验内容
1)给出VGG19的网络结构,描述其工作原理;
2)对实验程序中的设计的类进行解释说明;
3)程序代码、包括注释(注释作为评分依据之一);
4)单元测试过程(输入和输出的验证);
5)功能测试结果,
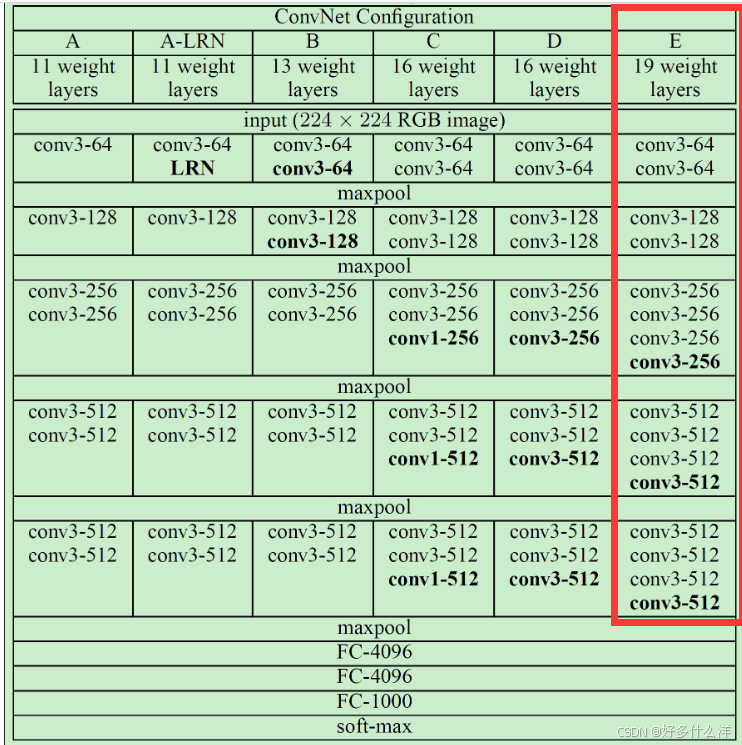
(1)VGG19网络介绍
①网络结构图
a.卷积层: VGG19包含多个卷积层,每个卷积层由3x3的卷积核和适当的填充(padding)组成。这些卷积层分为5个阶段(Stage),每个阶段由多个卷积层组成,卷积层之间是ReLU激活层。
b.池化层: 在每个阶段的末尾,除了最后一个阶段,都有一个2x2的最大池化层(MaxPoolingLayer),步长为2。这有助于减少特征图的空间尺寸,从而减少参数数量和计算量。
c.展平层: 在所有卷积和池化层之后,有一个展平层(FlattenLayer),它将多维的特征图展平为一维向量,以便输入到全连接层。
d.全连接层: VGG19包含3个全连接层(FullyConnectedLayer),第一个和第二个全连接层后面跟着ReLU激活层。
e.Softmax层: 最后一个全连接层的输出被送入Softmax层(SoftmaxLossLayer),用于计算每个类别的概率。
②工作原理
- 输入: 网络接受一个224x224像素的彩色图像作为输入。
- 卷积和ReLU: 输入图像首先通过第一个卷积层,然后通过ReLU激活层进行非线性转换。这个过程在每个阶段重复,逐渐提取更高级的特征。
- 池化: 每个阶段的末尾进行最大池化,减少特征图的尺寸,同时增加特征的不变性。
- 展平: 经过所有卷积和池化层后,得到的二维特征图被展平为一维向量。
- 全连接: 展平后的一维向量作为全连接层的输入,全连接层对特征进行进一步的整合和分类。
- 分类: 最后,Softmax层输出每个类别的概率,概率最高的类别被认为是图像的预测类别。
(2)对实验程序中的设计的类进行解释说明
1. FullyConnectedLayer (全连接层)
- 作用: 进行全连接操作,即矩阵乘法,通常用于卷积神经网络的末端,将卷积层提取的二维特征图展平后转换为一维特征向量。
- 方法:
- init_param: 初始化权重和偏置。
- forward: 执行前向传播。
- backward: 执行反向传播,计算梯度。
- get_gradient: 获取权重和偏置的梯度。
- update_param: 使用梯度更新权重和偏置。
- load_param 和 save_param: 加载和保存权重和偏置的值。
2. ReLULayer (ReLU激活层)
- 作用: 应用ReLU激活函数,引入非线性,帮助网络学习复杂的特征。
- 方法:
- forward: 执行前向传播,对输入的所有元素进行ReLU操作。
- backward: 执行反向传播,计算ReLU层的梯度。
3. SoftmaxLossLayer (Softmax损失层)
- 作用: 用于多分类问题的输出层,计算分类的损失值,并提供分类概率。
- 方法:
- forward: 执行前向传播,计算概率分布。
- get_loss: 根据真实标签计算损失值。
- backward: 执行反向传播,计算损失层的梯度。
4. ConvolutionalLayer (卷积层)
- 作用: 应用卷积操作以提取输入特征图中的局部特征。
- 方法:
- init_param: 初始化卷积核的权重和偏置。
- forward: 执行前向传播,计算卷积操作。
- load_param: 加载预训练的权重和偏置。
5. MaxPoolingLayer (最大池化层)
- 作用: 降低特征图的空间尺寸,从而减少参数数量和计算量,同时使特征检测更加鲁棒。
- 方法:forward: 执行前向传播,选择每个池化窗口内的最大值。
6. FlattenLayer (展平层)
- 作用: 将多维的特征图展平为一维向量,为全连接层做准备。
- 方法:forward: 执行前向传播,将输入的特征图展平。
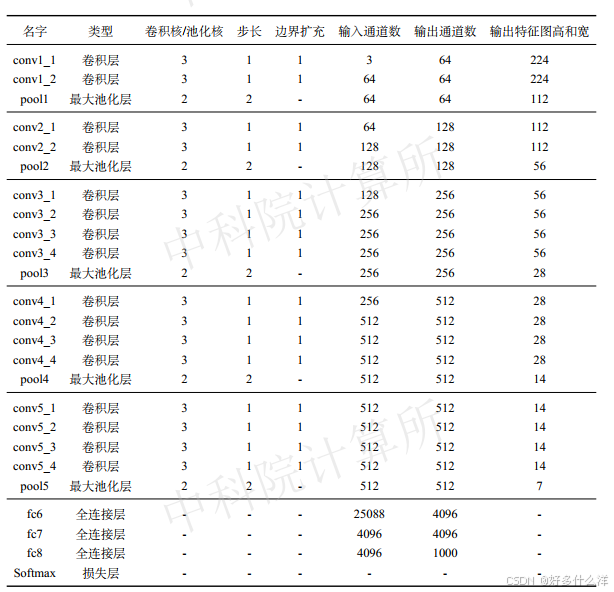
7. VGG19 (VGG-19网络模型)
- 作用: 构建整个VGG-19网络模型。
- 方法:
- build_model: 构建网络中的所有层。
- init_model: 初始化模型中的参数。
- load_model: 加载预训练的模型参数。
- load_image: 加载和预处理图像。
- forward: 执行整个网络的前向传播。
- evaluate: 对输入图像进行分类并输出结果。
③实验环境
- 软件环境: Python 编译环境及相关的扩展库,包括 Python 2.7.12, Pillow 6.0.0, Scipy
0.19.0, NumPy 1.16.0 - 数据集:官方训练 VGG19 使用的数据集为 ImageNet[5]。该数据集包括约 128 万训练
图像和 5 万张测试图像,共有 1000 个不同的类别。本实验使用了官方训练好的模型参数,并不需要直接使用 ImageNet 数据集进行 VGG19 模型的训练。
(3)程序代码分析
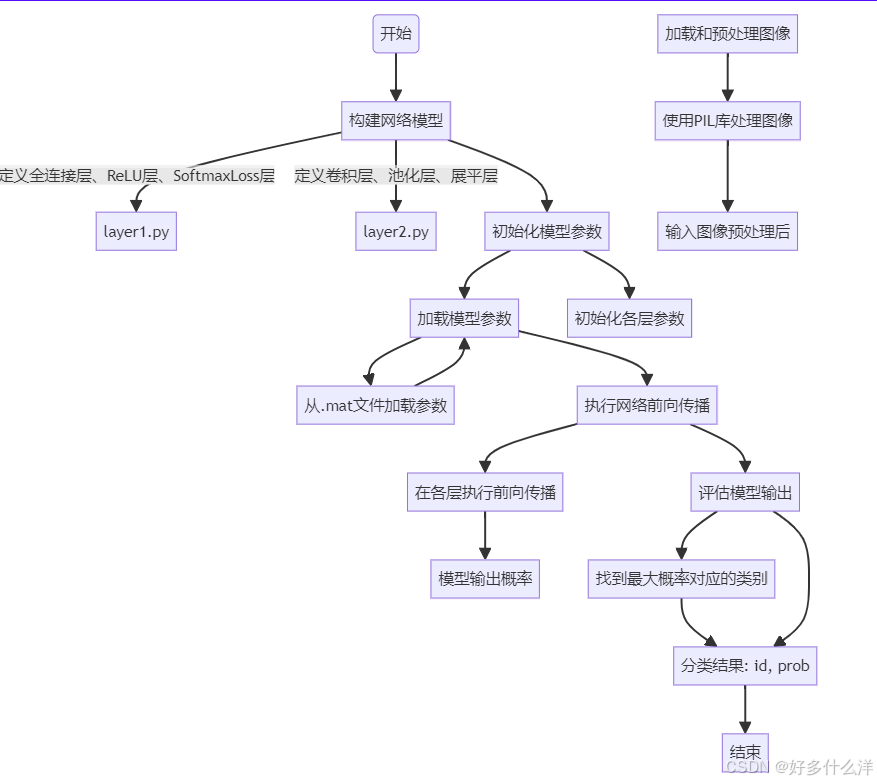
代码实现了一个VGG-19模型的搭建、配置、预训练权重加载、图像预处理及分类预测的全流程。程序首先定义了所需的各类层(如卷积层、池化层、全连接层等),然后依据VGG-19网络结构搭建模型并初始化参数。通过加载预训练的.mat文件参数,使模型具备了高级视觉特征的提取能力。接着,代码提供了图像加载及预处理功能,确保输入数据符合模型要求。最后,模型对输入图像执行前向传播计算得到预测概率,并输出最可能的分类结果,完成了从模型构建到实际应用的演示。
layer1代码:
import numpy as np
import struct
import os
import time
def show_matrix(mat, name):
#print(name + str(mat.shape) + ' mean %f, std %f' % (mat.mean(), mat.std()))
pass
def show_time(time, name):
#print(name + str(time))
pass
class FullyConnectedLayer(object):
def __init__(self, num_input, num_output):
self.num_input = num_input
self.num_output = num_output
print('\tFully connected layer with input %d, output %d.' % (self.num_input, self.num_output))
def init_param(self, std=0.01):
self.weight = np.random.normal(loc=0.0, scale=std, size=(self.num_input, self.num_output))
self.bias = np.zeros([1, self.num_output])
show_matrix(self.weight, 'fc weight ')
show_matrix(self.bias, 'fc bias ')
def forward(self, input):
start_time = time.time()
self.input = input
self.output = np.dot(self.input, self.weight) + self.bias
show_matrix(self.output, 'fc out ')
show_time(time.time() - start_time, 'fc forward time: ')
return self.output
def backward(self, top_diff):
self.d_weight = np.dot(self.input.T, top_diff)
self.d_bias = np.dot(np.ones([1, self.input.shape[0]]), top_diff)
show_matrix(top_diff, 'top_diff--------')
show_matrix(self.weight.T, 'w--------')
bottom_diff = np.dot(top_diff, self.weight.T)
show_matrix(self.d_weight, 'fc d_w ')
show_matrix(self.d_bias, 'fc d_b ')
show_matrix(bottom_diff, 'fc d_h ')
return bottom_diff
def get_gradient(self):
return self.d_weight, self.d_bias
def update_param(self, lr):
self.weight += - lr * self.d_weight
self.bias += - lr * self.d_bias
show_matrix(self.weight, 'fc update weight ')
show_matrix(self.bias, 'fc update bias ')
def load_param(self, weight, bias):
assert self.weight.shape == weight.shape
assert self.bias.shape == bias.shape
self.weight = weight
self.bias = bias
show_matrix(self.weight, 'fc weight ')
show_matrix(self.bias, 'fc bias ')
def save_param(self):
show_matrix(self.weight, 'fc weight ')
show_matrix(self.bias, 'fc bias ')
return self.weight, self.bias
class ReLULayer(object):
def __init__(self):
print('\tReLU layer.')
def forward(self, input):
start_time = time.time()
self.input = input
output = np.maximum(0, self.input)
show_matrix(output, 'relu out')
show_time(time.time() - start_time, 'relu forward time: ')
return output
def backward(self, top_diff):
bottom_diff = top_diff.copy()
bottom_diff[self.input < 0] = 0
show_matrix(bottom_diff, 'relu d_h ')
return bottom_diff
class SoftmaxLossLayer(object):
def __init__(self):
print('\tSoftmax loss layer.')
def forward(self, input):
input_max = np.max(input, axis=1, keepdims=True)
input_exp = np.exp(input - input_max)
exp_sum = np.sum(input_exp, axis=1, keepdims=True)
self.prob = input_exp / exp_sum
return self.prob
def get_loss(self, label):
self.batch_size = self.prob.shape[0]
self.label_onehot = np.zeros_like(self.prob)
self.label_onehot[np.arange(self.batch_size), label] = 1.0
loss = -np.sum(np.log(self.prob) * self.label_onehot) / self.batch_size
return loss
def backward(self):
bottom_diff = (self.prob - self.label_onehot) / self.batch_size
return bottom_diff
layer2代码
# coding=utf-8
import numpy as np
import os
import time
def show_matrix(mat, name):
#print(name + str(mat.shape) + ' mean %f, std %f' % (mat.mean(), mat.std()))
pass
def show_time(time, name):
#print(name + str(time))
pass
#
#
# class ConvolutionalLayer(object):
#
# def __init__(self, kernel_size, channel_in, channel_out, padding, stride):
#
# # 卷积层的初始化
#
# self.kernel_size = kernel_size
#
# self.channel_in = channel_in
#
# self.channel_out = channel_out
#
# self.padding = padding
#
# self.stride = stride
#
# print('\tConvolutional layer with kernel size %d, input channel %d, output channel %d.' % (self.kernel_size, self.channel_in, self.channel_out))
#
# def init_param(self, std=0.01): # 参数初始化
#
# self.weight = np.random.normal(loc=0.0, scale=std, size=(self.channel_in, self.kernel_size, self.kernel_size, self.channel_out))
#
# self.bias = np.zeros([self.channel_out])
#
# def forward(self, input): # 前向传播的计算
#
# start_time = time.time()
#
# self.input = input # [N, C, H, W]
#
# height = self.input.shape[2] + self.padding * 2
#
# width = self.input.shape[3] + self.padding * 2
#
# self.input_pad = np.zeros([self.input.shape[0], self.input.shape[1], height, width])
#
# self.input_pad[:, :, self.padding:self.padding+self.input.shape[2], self.padding:self.padding+self.input.shape[3]] = self.input
#
# # height_out = (height - self.kernel_size) / self.stride + 1
# #
# # width_out = (width - self.kernel_size) / self.stride + 1
# # 在 ConvolutionalLayer 类中
# height_out = int(np.floor((height - self.kernel_size) / self.stride + 1))
# width_out = int(np.floor((width - self.kernel_size) / self.stride + 1))
# # height_out = int((height - self.kernel_size + 2 * self.padding) / self.stride + 1)
# # width_out = int((width - self.kernel_size + 2 * self.padding) / self.stride + 1)
#
# self.output = np.zeros([self.input.shape[0], self.channel_out, height_out, width_out])
# self.padding = int(self.padding)
#
# for idxn in range(self.input.shape[0]):
# for idxc in range(self.channel_out):
# for idxh in range(height_out):
# for idxw in range(width_out):
# # 计算卷积层的前向传播,特征图与卷积核的内积再加偏置
# self.output[idxn, idxc, idxh, idxw] = np.sum(
# self.input_pad[idxn, :, idxh * self.stride:idxh * self.stride + self.kernel_size,
# idxw * self.stride:idxw * self.stride + self.kernel_size] * self.weight[:, :, :, idxc]) + \
# self.bias[idxc]
#
# return self.output
#
# def load_param(self, weight, bias): # 参数加载
#
# assert self.weight.shape == weight.shape
#
# assert self.bias.shape == bias.shape
#
# self.weight = weight
#
# self.bias = bias
#
class ConvolutionalLayer(object):
def __init__(self, kernel_size, channel_in, channel_out, padding, stride):
self.kernel_size = kernel_size
self.channel_in = channel_in
self.channel_out = channel_out
self.padding = padding
self.stride = stride
print('\tConvolutional layer with kernel size %d, input channel %d, output channel %d.' % (self.kernel_size, self.channel_in, self.channel_out))
def init_param(self, std=0.01): # 参数初始化
self.weight = np.random.normal(loc=0.0, scale=std, size=(self.channel_in, self.kernel_size, self.kernel_size, self.channel_out))
self.bias = np.zeros([self.channel_out])
def forward(self, input): # 前向传播的计算
start_time = time.time()
self.input = input # [N, C, H, W]
# 计算输入尺寸,考虑填充和步长
height = self.input.shape[2] + self.padding * 2
width = self.input.shape[3] + self.padding * 2
height_out = int((height - self.kernel_size) / self.stride + 1)
width_out = int((width - self.kernel_size) / self.stride + 1)
self.input_pad = np.pad(self.input, ((0, 0), (0, 0), (self.padding, self.padding), (self.padding, self.padding)), 'constant')
self.output = np.zeros([self.input.shape[0], self.channel_out, height_out, width_out])
for idxn in range(self.input.shape[0]):
for idxc in range(self.channel_out):
for idxh in range(height_out):
for idxw in range(width_out):
# 计算卷积层的前向传播,特征图与卷积核的内积再加偏置
self.output[idxn, idxc, idxh, idxw] = np.sum(
self.input_pad[idxn, :, idxh * self.stride:idxh * self.stride + self.kernel_size,
idxw * self.stride:idxw * self.stride + self.kernel_size] * self.weight[:, :, :, idxc]) + \
self.bias[idxc]
return self.output
def load_param(self, weight, bias): # 参数加载
assert self.weight.shape == weight.shape
assert self.bias.shape == bias.shape
self.weight = weight
self.bias = bias
class MaxPoolingLayer(object):
def __init__(self, kernel_size, stride):
self.kernel_size = kernel_size
self.stride = stride
def forward(self, input):
# 假设 input 是一个 4D 特征图,形状为 [N, C, H, W]
# 计算输出形状
N, C, H, W = input.shape
output_height = int((H - self.kernel_size) / self.stride + 1)
output_width = int((W - self.kernel_size) / self.stride + 1)
# 初始化输出张量
output = np.zeros([N, C, output_height, output_width])
# 进行最大池化操作
for i in range(output_height):
for j in range(output_width):
# 计算池化窗口的起始位置
start_h = i * self.stride
start_w = j * self.stride
end_h = start_h + self.kernel_size
end_w = start_w + self.kernel_size
# 提取池化窗口内的特征图
pooling_window = input[:, :, start_h:end_h, start_w:end_w]
# 计算池化窗口内的最大值
max_value = np.max(pooling_window, axis=(2, 3))
# 将最大值复制到输出张量中
output[:, :, i, j] = max_value
return output
#
# class MaxPoolingLayer(object):
#
# def __init__(self, kernel_size, stride): # 最大池化层的初始化
#
# self.kernel_size = kernel_size
#
# self.stride = stride
#
# print('\tMax pooling layer with kernel size %d, stride %d.' % (self.kernel_size, self.stride))
#
# def forward_raw(self, input): # 前向传播的计算
#
# start_time = time.time()
#
# self.input = input # [N, C, H, W]
#
# self.max_index = np.zeros(self.input.shape)
#
# height_out = (self.input.shape[2] - self.kernel_size) / self.stride + 1
#
# width_out = (self.input.shape[3] - self.kernel_size) / self.stride + 1
#
# self.output = np.zeros([self.input.shape[0], self.input.shape[1], height_out, width_out])
#
# for idxn in range(self.input.shape[0]):
# for idxc in range(self.input.shape[1]):
# for idxh in range(height_out):
# for idxw in range(width_out):
# # 计算最大池化层的前向传播,取池化窗口内的最大值
# self.output[idxn, idxc, idxh, idxw] = np.max(
# self.input[idxn, idxc, idxh * self.stride:idxh * self.stride + self.kernel_size,
# idxw * self.stride:idxw * self.stride + self.kernel_size])
#
# return self.output
class FlattenLayer(object):
def __init__(self, input_shape, output_shape): # 扁平化层的初始化
self.input_shape = input_shape
self.output_shape = output_shape
assert np.prod(self.input_shape) == np.prod(self.output_shape)
print('\tFlatten layer with input shape %s, output shape %s.' % (str(self.input_shape), str(self.output_shape)))
def forward(self, input): # 前向传播的计算
assert list(input.shape[1:]) == list(self.input_shape)
# matconvnet feature map dim: [N, height, width, channel]
# ours feature map dim: [N, channel, height, width]
self.input = np.transpose(input, [0, 2, 3, 1])
self.output = self.input.reshape([self.input.shape[0]] + list(self.output_shape))
show_matrix(self.output, 'flatten out ')
return self.output
vgg代码
# coding:utf-8
import imageio
import numpy as np
# import imageio.v2 as imageio
import os
import scipy.io
import time
from PIL import Image
# 导入自定义层,这些层的实现代码在其他文件中 (layer1.py 和 layer2.py)
from layer1 import FullyConnectedLayer, ReLULayer, SoftmaxLossLayer
from layer2 import ConvolutionalLayer, MaxPoolingLayer, FlattenLayer
def show_matrix(mat, name):
# print(name + str(mat.shape) + ' mean %f, std %f' % (mat.mean(), mat.std()))
# 打印矩阵的名称、形状、均值和标准差
pass
class VGG19(object):
def __init__(self, param_path='imagenet-vgg-verydeep-19.mat'):
self.param_path = param_path
self.param_layer_name = ( # 网络层的名称组成的元组
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4', 'pool5',
'flatten', 'fc6', 'relu6', 'fc7', 'relu7', 'fc8', 'softmax'
)
self.image_mean = None # 初始化图像均值参数,用于图像预处理 添加默认初始化为None
def build_model(self): # 构建网络模型
print('Building vgg-19 model...')
self.layers = {}
#按照VGG19网络结构初始化各层,包括卷积层、激活层、池化层和全连接层
# Stage 1
self.layers['conv1_1'] = ConvolutionalLayer(3, 3, 64, 1, 1)
self.layers['relu1_1'] = ReLULayer()
self.layers['conv1_2'] = ConvolutionalLayer(3, 64, 64, 1, 1)
self.layers['relu1_2'] = ReLULayer()
self.layers['pool1'] = MaxPoolingLayer(2, 2)
# Stage 2
self.layers['conv2_1'] = ConvolutionalLayer(3, 64, 128, 1, 1)
self.layers['relu2_1'] = ReLULayer()
self.layers['conv2_2'] = ConvolutionalLayer(3, 128, 128, 1, 1)
self.layers['relu2_2'] = ReLULayer()
self.layers['pool2'] = MaxPoolingLayer(2, 2)
# Stage 3
self.layers['conv3_1'] = ConvolutionalLayer(3, 128, 256, 1, 1)
self.layers['relu3_1'] = ReLULayer()
self.layers['conv3_2'] = ConvolutionalLayer(3, 256, 256, 1, 1)
self.layers['relu3_2'] = ReLULayer()
self.layers['conv3_3'] = ConvolutionalLayer(3, 256, 256, 1, 1)
self.layers['relu3_3'] = ReLULayer()
self.layers['conv3_4'] = ConvolutionalLayer(3, 256, 256, 1, 1)
self.layers['relu3_4'] = ReLULayer()
self.layers['pool3'] = MaxPoolingLayer(2, 2)
# Stage 4
self.layers['conv4_1'] = ConvolutionalLayer(3, 256, 512, 1, 1)
self.layers['relu4_1'] = ReLULayer()
self.layers['conv4_2'] = ConvolutionalLayer(3, 512, 512, 1, 1)
self.layers['relu4_2'] = ReLULayer()
self.layers['conv4_3'] = ConvolutionalLayer(3, 512, 512, 1, 1)
self.layers['relu4_3'] = ReLULayer()
self.layers['conv4_4'] = ConvolutionalLayer(3, 512, 512, 1, 1)
self.layers['relu4_4'] = ReLULayer()
self.layers['pool4'] = MaxPoolingLayer(2, 2)
# Stage 5
self.layers['conv5_1'] = ConvolutionalLayer(3, 512, 512, 1, 1)
self.layers['relu5_1'] = ReLULayer()
self.layers['conv5_2'] = ConvolutionalLayer(3, 512, 512, 1, 1)
self.layers['relu5_2'] = ReLULayer()
self.layers['conv5_3'] = ConvolutionalLayer(3, 512, 512, 1, 1)
self.layers['relu5_3'] = ReLULayer()
self.layers['conv5_4'] = ConvolutionalLayer(3, 512, 512, 1, 1)
self.layers['relu5_4'] = ReLULayer()
self.layers['pool5'] = MaxPoolingLayer(2, 2)
# Fully Connected Layers
self.layers['flatten'] = FlattenLayer([512, 7, 7], [512 * 7 * 7])
self.layers['fc6'] = FullyConnectedLayer(512 * 7 * 7, 4096)
self.layers['relu6'] = ReLULayer()
self.layers['fc7'] = FullyConnectedLayer(4096, 4096)
self.layers['relu7'] = ReLULayer()
self.layers['fc8'] = FullyConnectedLayer(4096, 1000)
self.layers['softmax'] = SoftmaxLossLayer()
# 更新那些需要跟踪参数更新的层。
self.update_layer_list = [name for name, layer in self.layers.items() if
isinstance(layer, (ConvolutionalLayer, FullyConnectedLayer))]
for layer_name in self.layers.keys():
if 'conv' in layer_name or 'fc' in layer_name:
self.update_layer_list.append(layer_name)
def init_model(self):
# 初始化模型参数
print('Initializing parameters of each layer in vgg-19...')
for layer_name in self.update_layer_list:
self.layers[layer_name].init_param()
def load_model(self):
print('Loading parameters from file ' + self.param_path)
params = scipy.io.loadmat(self.param_path)
self.image_mean = params['normalization'][0][0][0]
self.image_mean = np.mean(self.image_mean, axis=(0, 1))
print('Get image mean: ' + str(self.image_mean))
for idx in range(43):
if 'conv' in self.param_layer_name[idx]:
weight, bias = params['layers'][0][idx][0][0][0][0]
# matconvnet: weights dim [height, width, in_channel, out_channel]
# ours: weights dim [in_channel, height, width, out_channel]
weight = np.transpose(weight, [2, 0, 1, 3])
bias = bias.reshape(-1)
self.layers[self.param_layer_name[idx]].load_param(weight, bias)
if idx >= 37 and 'fc' in self.param_layer_name[idx]:
weight, bias = params['layers'][0][idx - 1][0][0][0][0]
weight = weight.reshape([weight.shape[0] * weight.shape[1] * weight.shape[2], weight.shape[3]])
self.layers[self.param_layer_name[idx]].load_param(weight, bias)
def load_image(self, image_dir): # 加载和预处理图像
print('Loading and preprocessing image from ' + image_dir)
self.input_image = Image.open(image_dir)
self.input_image = self.input_image.resize((224, 224), Image.LANCZOS)
self.input_image = np.array(self.input_image).astype(np.float32)
# 检查image_mean是否有效,避免NoneTypeError
if self.image_mean is not None and isinstance(self.image_mean, np.ndarray):
self.input_image -= self.image_mean
else:
print("Warning: Image mean is not available, proceeding without normalization.")
self.input_image = np.reshape(self.input_image, [1] + list(self.input_image.shape))
self.input_image = np.transpose(self.input_image, [0, 3, 1, 2])
def forward(self):# 执行网络的前向传播
print('Inferencing...')
start_time = time.time()
current = self.input_image
for idx in range(len(self.param_layer_name)):# 循环遍历所有层,执行前向传播
print('Inferencing layer: ' + self.param_layer_name[idx])
current = self.layers[self.param_layer_name[idx]].forward(current)
print('Inference time: %f' % (time.time() - start_time))
return current
def evaluate(self): # 评估模型对输入图像的分类结果
prob = self.forward()
top1 = np.argmax(prob[0])
print('Classification result: id = %d, prob = %f' % (top1, prob[0, top1]))
if __name__ == '__main__':
vgg = VGG19() # 创建VGG19模型实例
vgg.build_model() # 构建模型
vgg.init_model() # 初始化模型参数
vgg.load_model() # 加载预训练模型参数
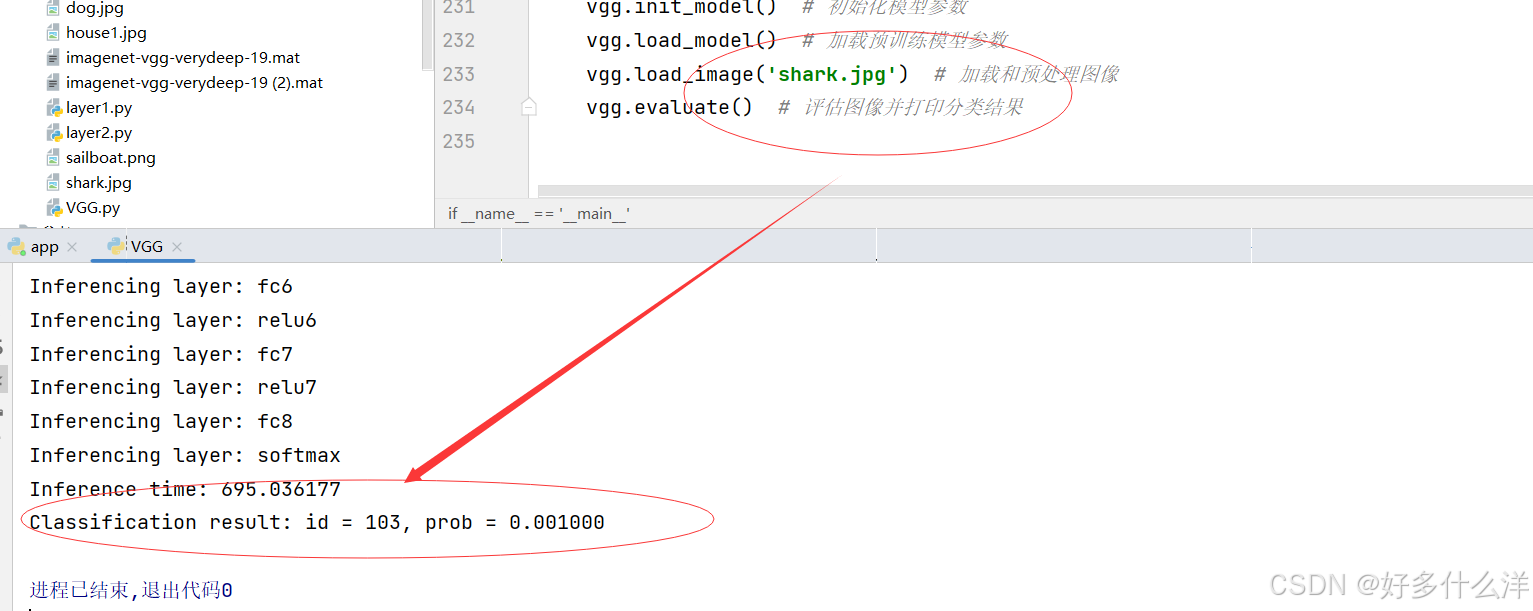
vgg.load_image('shark.jpg') # 加载和预处理图像
vgg.evaluate() # 评估图像并打印分类结果
注意:本实验室基于vgg预训练模型进行推理实现的,所以需要下载预训练文件imagenet-vgg-verydeep-19.mat
四、实验结果

模型预测属于这个类别(类别ID 381)的概率非常低,只有0.1%。这意味着模型对这个预测不是很有信心。同时,经查资料显示id=381为spider monkey, Ateles geoffroyi',对应的是蜘蛛猴,但是传入的图片为狗,说明模型并没有很好的进行分类判断。
当再次选择同样的照片进行图像分类时,得到的结果是:类别ID=286,与第一次的不同。

传入名为“sahrk”的图片,分类的准确率任然很低,说明应该是代码出现了错误。
代码可以正常运行,但是准确率非常低,因为在无法找到normalization时,选择直接跳过不做处理,可能会导致结果准确率很低。经检查,是因为imagenet-vgg-verydeep-19.mat文件下载出错,与代码中对应的内容有缺失。
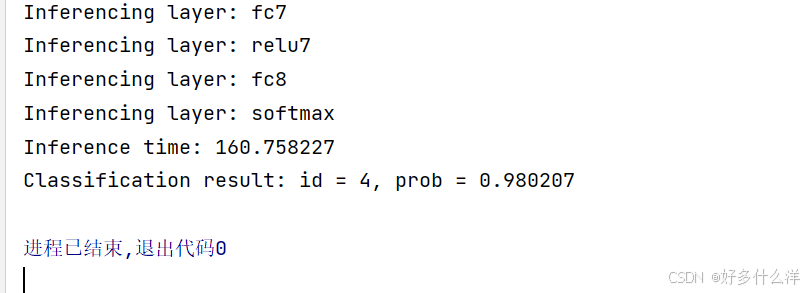
导入正确的预训练文件,正确结果如下,可以看到预测结果为:id=4,准确率为0.98
经过查验,id=4为shark与传入图片内容相符合。
希望这篇分享能够激励每一位读者,无论你是一名正在学习深度学习的学生,还是一个渴望在技术领域不断突破的工程师。记住,每一次失败都是一次成长的机会,每一次尝试都将你推向更广阔的未来。让我们一起,继续在这条充满未知与奇迹的道路上前行,用代码编织梦想,用数据解读世界。
如果你在阅读过程中有任何疑问或想要进一步交流的地方,欢迎在评论区留言。你的参与和反馈是我们持续进步的动力。感谢陪伴,期待下一次的探索之旅!

















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









