







redis
1、什么是redis?
redis是一个基于内存的高性能key-value数据库,它是完全开源免费的,用c语言编写的。
特点:
1. 基于内存操作的,吞吐量非常高,每秒可以达到十万次读写操作。
2. 读写模块是单线程操作的,可以保证命令执行的原子性。
3. 支持数据的持久化,可以把内存中的数据保存的磁盘中。
2、redis数据结构参考文章
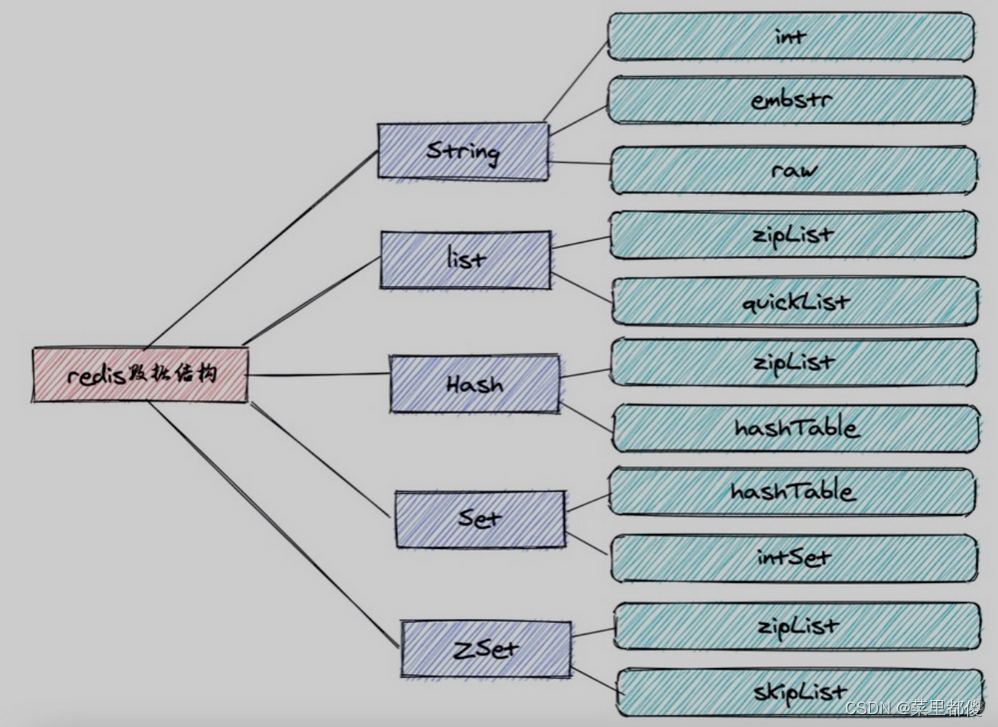
redis有7种结构这里只有五种。
2.1、String
string是redis最简单的数据结构,可以存储所有数据,比如图片、序列化后的对象。其本质是sds数组。它有三种编码方式int、embstr、raw。
int:存储的字符串全都是整数时,用int编码。
embstr:存储的字符串小于44字节,用embstr。
raw:存储的字符串大于44字节,用raw。
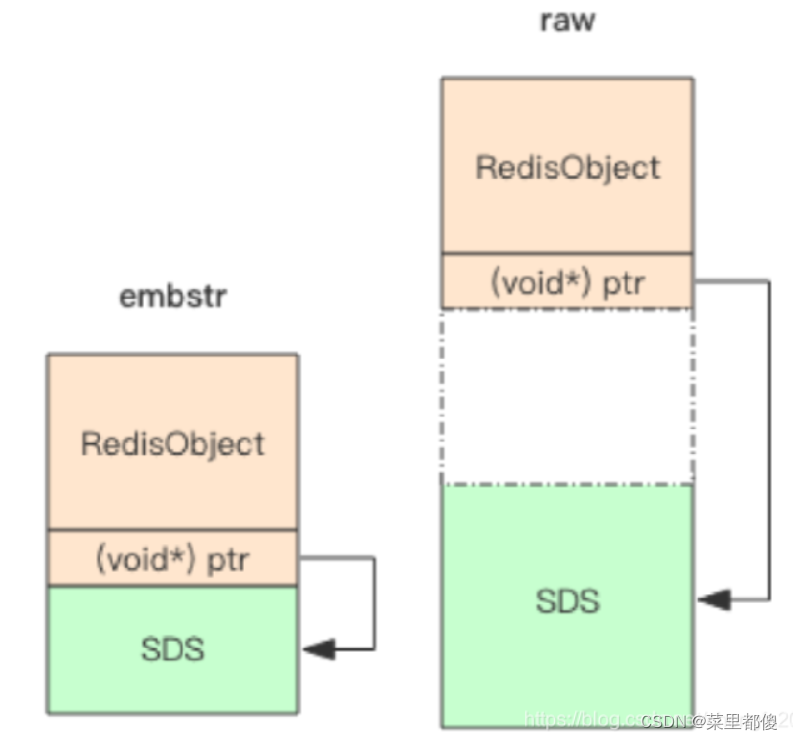
2.1.1、embstr与raw的区别:
对于embstr类型,redisObject对象头与sds对象的内存地址是连接在一起的。
对于raw类型,redisObject对象头与sds对象的内存地址不是连接在一起的。

2.1.2、应用
用redis做session内存共享。
用于统计网站的请求数,论坛的点赞、评论数。
2.1.3、操作命令
键值对
> set name codehole
OK
> get name
"codehole"
> exists name
(integer) 1
> del name
(integer) 1
> get name
(nil)
批量键值对
> set name1 codehole
OK
> set name2 holycoder
OK
> mget name1 name2 name3 # 返回一个列表
1) "codehole"
2) "holycoder"
3) (nil)
> mset name1 boy name2 girl name3 unknow
> mget name1 name2 name3
1) "boy"
2) "girl"
3) "unknown"
过期和 set 命令扩展
> set name codehole
> get name
"codehole"
> expire name 5 # 5s 后过期
... # wait for 5s
> get name
(nil)
> setex name 5 codehole # 5s 后过期,等价于 set + expire
> get name
"codehole"
... # wait for 5s
> get name
(nil)
> setnx name codehole # set 和 expire 原子执行,因为 name 不存在就执行创建成功
(integer) 1
> get name
"codehole"
> setnx name holycoder # set 和 expire 原子执行,因为 name 存在 set 创建不成功
(integer) 0
> get name
"codehole"
计数
> set age 30
OK
> incr age
(integer) 31
> incrby age 5
(integer) 36
> incrby age -5
(integer) 31
set codehole 9223372036854775807
# Long.Max
Ok
2.2、list
list是有序可重复列表,可以通过索引查询,插入和删除速度快。
2.2.1、底层实现
redis3.2前:
- list对象的编码方式有压缩列表ziplist和双向循环链表linkedlist。
- 所有元素小于64字节且元素数量小于512用ziplist,否则用linkedlist。
redis3.2后:
使用quicklist,它是一个双向链表,而且是一个基于ziplist的双向链表,quicklist的每个节点都是一个ziplist,结合了双向链表和ziplist的优点。
2.2.2、使用场景
- 消息队列。左进右出,lpush和rpop。
- 分页。
- 好友列表。
操作命令
左进右出:队列
> rpush books python java golang
(integer) 3
> llen books
(integer) 3
> lpop books
"python"
> lpop books
"java"
> lpop books
"golang"
> lpop books
(nil)
左进左出:栈
> rpush books python java golang
(integer) 3
> rpop books
"golang"
> rpop books
"java"
> rpop books
"python"
> rpop books
(nil)
> rpush books python java golang
(integer) 3
> lindex books 1 # O(n) 慎用,并不会删除 "java"
"java"
> lrange books 1 -1 # 获取从1开始到最后一个元素,O(n) 慎用, 并不会删除
1) "python"
2) "java"
3) "golang"
> ltrim books 1 -1 # O(n) 慎用
OK
> lrange books 0 -1 # 获取所有元素
1) "java"
2) "golang"
> ltrim books 1 0 # 这其实是清空了整个列表,因为区间范围长度为负
OK
> llen books
(integer) 0
2.3、hash
2.3.1、底层实现
- hash类型有两种编码方式一种是ziplist另一种是hashtable。
- 如果集合中保存的键和值都小于64字节并且键值对数量小于512则用ziplist,否则用hashtable。
2.3.2、应用场景
购物车:可以以用户id为key,商品id为field,商品数量为value。
2.3.3、编码操作
> hset books java "thinks in java" # books 是 key,Java 是 hash中的 key
# 如果 字符串包含空格 要用引号括起来
(integer) 1
> hset books golang "concurrency in go"
(integer) 1
> hgetall books # entries(),key 和 value 间隔出现
1) "java"
2) "thinks in java"
3) "golang"
4) "concurrency in go"
> hlen books
(integer) 2
> hget books golang
"concurrency in go"
> hset books golang "learning go programming" # 因为是更新操作,所以返回 0
(integer) 0
> hget books golang
"learning go programming"
> hmset books java "effective java" golang "modern golang
programming" # 批量 set
OK
2.4、set
redis中的list和set都可以存储多个字符串,不同之处在于list是有序可重复的,set是无序不可重复的。
2.4.1、底层实现
- set集合的编码可以有intset和hashtable。
- 如果集合中的所有元素都是整数并且保存的元素数量小于512则用intset,否则用hashtable。
2.4.2、使用场景
- 标签:可以将博客网站中所有个人的标签都存储在set中,然后按标签将每个人归档
- 存储好友
2.4.3、编码使用
> sadd books python
(integer) 1
> sadd books python # 重复
(integer) 0
> sadd books golang
(integer) 1
> smembers books # 注意顺序,和插入的并不一致,因为 set 是无序的
1) "golang"
2) "python"
> sismember books python # 查询某个 value 是否存在,相当于 contains(o)
(integer) 1
> sismember books rust
(integer) 0
> scard books # 获取长度相当于 count()
(integer) 2
> spop books # 弹出一个
"python"
2.5、zset
2.5.1、底层实现
- 有序集合的编码可以是 ziplist 或者 skiplist。
- 如果有序集合保存的元素数量小于 128 个并且保存的所有元素成员的长度都小于 64 字节,用 ziplist 编码;否则使用skiplist;
- 当ziplist作为zset的底层存储结构时候,每个集合元素使用两个紧挨在一起的 ziplist 节点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值。
- 当skiplist作为zset的底层存储结构的时候,使用skiplist按序保存元素及分值,使用dict来保存元素和分值的映射关系。
2.5.2、应用场景
排行榜:有序集合最常用的场景。如新闻网站对热点新闻排序,比如根据点击量、点赞量等。
2.5.2、操作命令
> zadd books 9.0 "think in java"
(integer) 1
> zadd books 8.9 "java concurrency"
(integer) 1
> zadd books 8.6 "java cookbook"
(integer) 1
> zrange books 0 -1 # 按 score 排序列出,参数区间为排名范围
1) "java cookbook"
2) "java concurrency"
3) "think in java"
> zrevrange books 0 -1 # 按 score 逆序列出,参数区间为排名范围
1) "think in java"
2) "java concurrency"
3) "java cookbook"
> zcard books # 相当于 count()
(integer) 3
> zscore books "java concurrency" # 获取指定 value 的 score
"8.9000000000000004" # 内部 score 使用 double 类型进行存储,所以存在小数点精度问题
> zrank books "java concurrency" # 排名
(integer) 1
> zrangebyscore books 0 8.91 # 根据分值区间遍历 zset
1) "java cookbook"
2) "java concurrency"
> zrangebyscore books -inf 8.91 withscores # 根据分值区间 (-∞, 8.91] 遍历 zset,同时返回分值。inf 代表 infinite,无穷大的意思。
1) "java cookbook"
2) "8.5999999999999996"
3) "java concurrency"
4) "8.9000000000000004"
> zrem books "java concurrency" # 删除 value
(integer) 1
> zrange books 0 -1
1) "java cookbook"
2) "think in java"
3、过期策略
redis的过期策略采用定时遍历和惰性策略。
3.1、定时遍历和惰性策略
- 定时遍历:redis会把设置了过期时间的key放到同一个字典。每秒进行十次过期扫描,每次选20个key,删除这20个key中过期的key,删除数超过1/4就重复扫描。每次扫描时间不能超过25ms。
- 惰性策略:访问key时进行一次过期检查。
3.2、从库过期策略
从库不会主动删除过期key,主库中key过期会在aof文件中添加一条del记录,同步到从库中,从库执行del语句。
4、内存淘汰机制
redis.conf文件中有,8种。
淘汰最近最少使用、淘汰将要过期、淘汰使用频率最高等。
5、redis持久化参考文章
redis有两种持久化方式,rdb和aof。默认是关机时使用rdb进行持久化,也可以在redis.conf文件中配置自定义触发条件。
5.1、rdb
rdb是指以快照形式将内存中的数据全量写入磁盘中。
5.1.1、rdb的优缺点
- 优点是恢复数据时加载进内存的速度快,适合大规模数据恢复。
- 缺点是容易丢失当前到上次快照的数据。二是快照是把内存中的数据全量复制到磁盘,数据量大时IO压力大。三是folk子进程会阻塞。
5.1.2、rdb持久化的过程详细参考该文章持久化部分
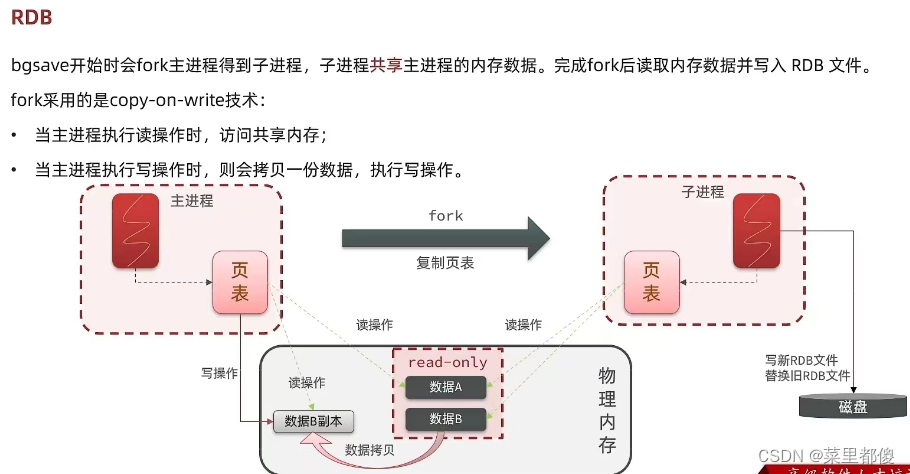
- redis调用bgsave命令
- fork主进程得到子进程,共享内存(进程通过页表来和物理内存产生映射关系,fork时是共享物理内存的,只是子进程复制了一份页表。)。
- 子进程读取内存数据并写入新的rdb文件中。
- 如果主进程在此时发生写操作则使用cow机制把要修改的数据页复制一份,主进程修改该副本并修改页表使主进程与副本产生映射。
5.2、aof
aof日志存储的是redis的写操作。恢复时从前往后执行一遍即可。
5.2.1、aof备份时机
aof默认是关闭的,需要修改redsi.conf

5.2.2、aof重写

6、redis集群
redis集群有三种模式:主从集群、哨兵集群、分片集群。集群有高可用、负载均衡、数据分片等优点。
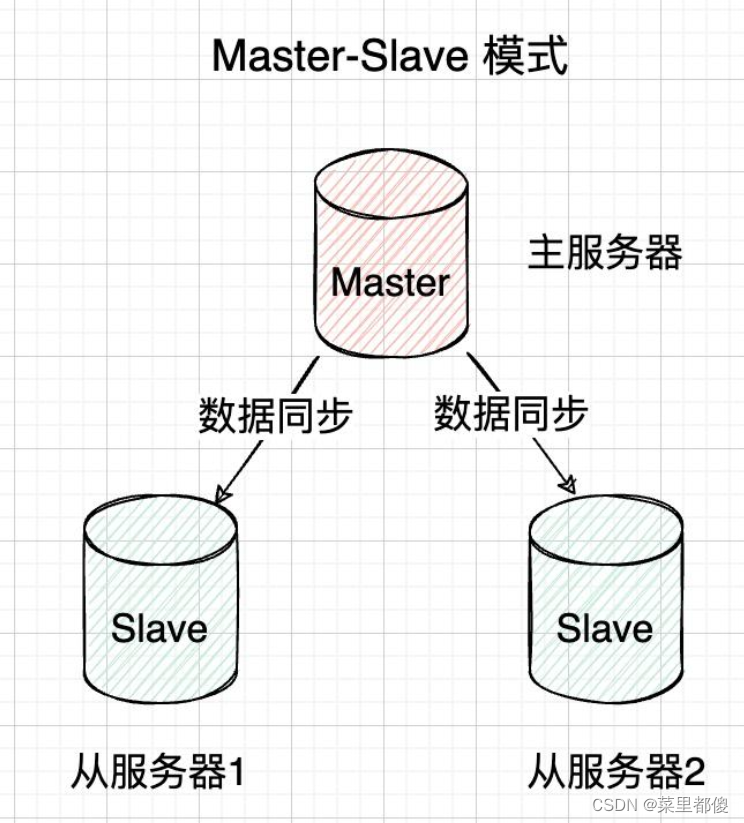
6.1、主从集群(Master-Slave)
主从复制是redis集群的一种基本集群模式。主从复制通过将主节点的数据复制到从节点,主节点负责读写,从节点负责读并且从节点会实时同步主节点的数据。
6.1.1、主从复制配置和实现
配置主节点:在主节点的redis.conf配置文件中,无需进行特殊配置,主节点默认监听所有客户端请求。
# 主节点默认端口号6379
port 6379
配置从节点:在从节点的redis.conf配置文件中,添加如下配置,指定主节点的地址和端口:
# 从节点设置端口号6380
port 6380
# replicaof 主节点IP 主节点端口
replicaof 127.0.0.1 6379
6.1.2、主从复制的优缺点
- 优点:读写分离提高系统系能、配置简单易于实现、实现数据冗余提高数据安全性。
- 缺点:主节点负责所有的读写压力大、主节点故障需要手动切换到从节点。
6.1.3、简述主从集群全量数据同步的流程
- slave请求增量同步。
- master判断replid不一致,拒绝增量同步。
- maser 将完整的内存数据生成RDB,发送RDB到slave。
- salve清空本地数据,加载RDB到slave。
- master将RDB期间执行的命令记录到rep_backlog并发送到slave。
- slave执行接收到的命令,保持主从同步。


6.2、哨兵机制
redis的哨兵机制主要是用来实现主从集群自动故障恢复的(假如主节点故障,哨兵就会从从节点中选出新主节点)
6.2.1、哨兵机制的三个作用:
- 监控:监控主节点和从节点是否正常运作
- 故障转移:主节点发生故障,就选出新的主节点
- 通知:通知客户端新的主节点
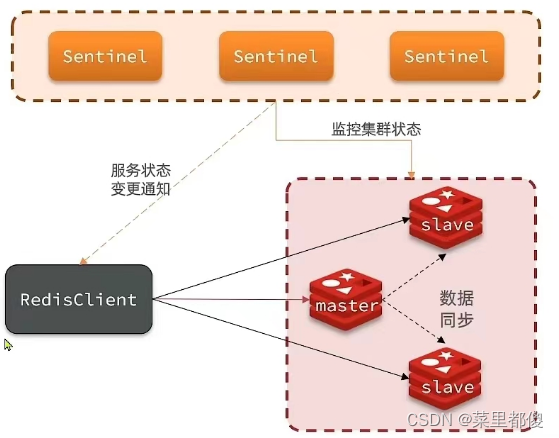
6.2.2、sentinel如何判断一个redis实例是否健康?
- 每隔1秒ping一次,超过一定时间不响应则认为主观下线。
- 超过半数的哨兵都认为主观下线,则判断节点下线。
6.2.3、故障转移的步骤有哪些?
- 选一个新的主节点
- 让所有的从节点设置新的主节点
- 让故障节点设置新的主节点
6.3、分片集群
7、分布式锁
8、缓存的各种问题
8.1、操作缓存需要注意的问题
-
删除缓存还是更新缓存?选删除缓存
每次更新数据库都更新缓存可能会出现无效写操作过多。
所以应该在更新数据库时让缓存失效,查询时在更新缓存。 -
先更新数据库还是先删除缓存?
先更新数据库再删除缓存

-
延时双删
如果非要先删除缓存就用延时双删。
先删缓存-》更新数据库-》休眠-》再删缓存
8.2、缓存穿透
缓存穿透指的是客户端请求的数据在缓存和数据库中都不存咋,这些请求直接打到数据库。
解决方案:
- 返回空对象(设置过期时间)
- 布隆过滤器
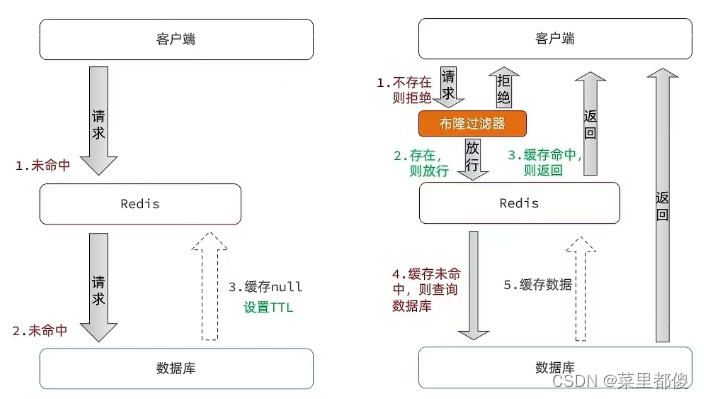
8.3、缓存击穿
缓存击穿指的是某个热点key突然失效,大量请求打到数据库。
- 逻辑过期
- 互斥锁
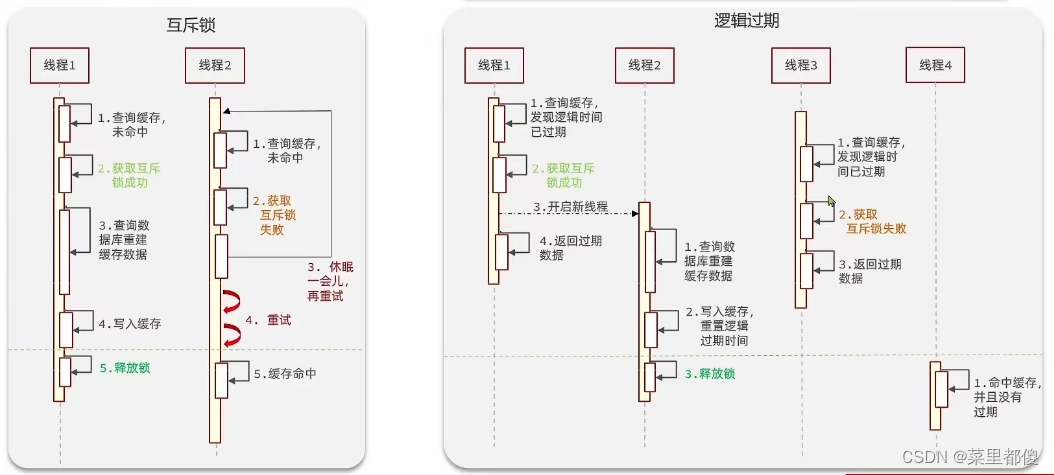
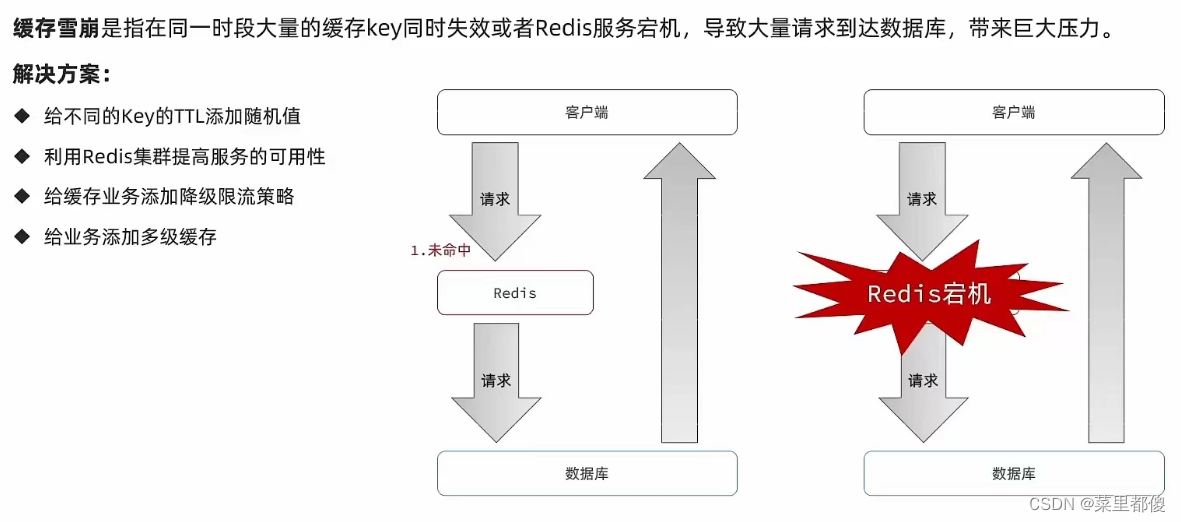
8.4、缓存雪崩
缓存雪崩指的是大量key同时失效,导致大量请求直接打到数据库。
解决方案:
- 设置随机过期时间
- 部署redis集群
















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











