






文章目录
引语
笔者是在学习可见性和 java 的 volatile 中得知该知识点,学习 CPU Cache 和在写此文的过程中,发现其相关内容较多,于是打算分为上中下三篇进行讲述。
上文主要介绍 CPU Cache 相关的基础概念以及内存地址到 Cache 的三种映射方式,中篇讲述 Cache Miss 和 Cache Line 的替换策略(即缓存不命中和行替换),下文会针对 Cache 一致性和写策略
该知识点较为重要,是解决多线程高并发程序的基础知识,了解了相关知识后,可以相对理解许多并发问题发生的原因,但是由于涉及到的新知识点很多,以及一些新的名词,他们之间又相互有联系,导致不好讲述,我会先对各个名词给出初步的解释,这期间会遗留许多问题,但当看完这篇文章,你将能把各个知识点串联起来,这些问题就可以得到解答,希望耐心看完。(本文内容参考了《深入理解计算机》一书)
CPU Cache
我们都知道一个程序运行时的各种数据是放在内存(主存)中, CPU 运行程序就需要去内存中取数据,但是由于 CPU 速度太快了,内存和 CPU 运行速度有着几个数量级的差距,要是每次都要去内存中取数据,那么 CPU 的大部分时间都等待内存读写了,为了避免这种情况,我们加入了 CPU Cache 也就是 CPU 高速缓存
CPU Cache 的速度比起内存会快很多,CPU 读取数据时就去 Cache 中取数据而不是直接取内存取
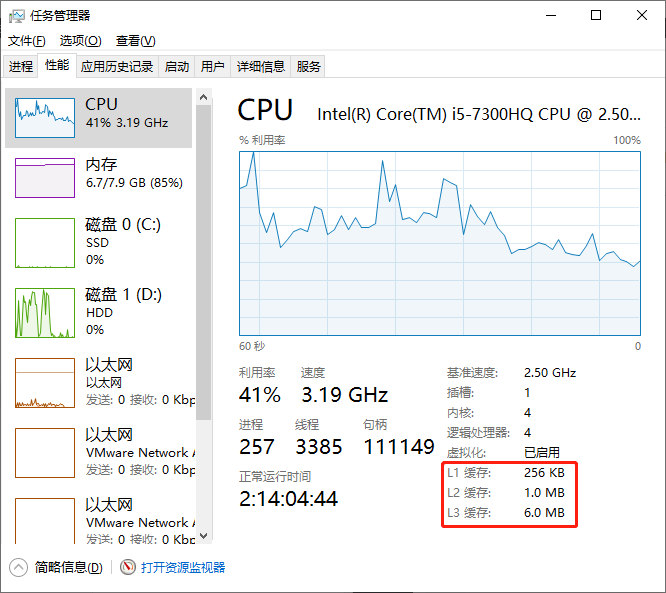
CPU Cache 分为三级 L1, L2, L3,依次容量增大,速度下降;
L1 是位于 CPU 核心上,运行速度和 CPU 一样快,L2 也被称为外部缓存,比 L1 慢,访问时间大概是 L1 的 5 倍
L1 和 L2 都是每一个 CPU 核心独自拥有的,而 L3 是所有核心共享的,所以也叫共享缓存
在 win 下打开任务管理器可以看到
Cache Line
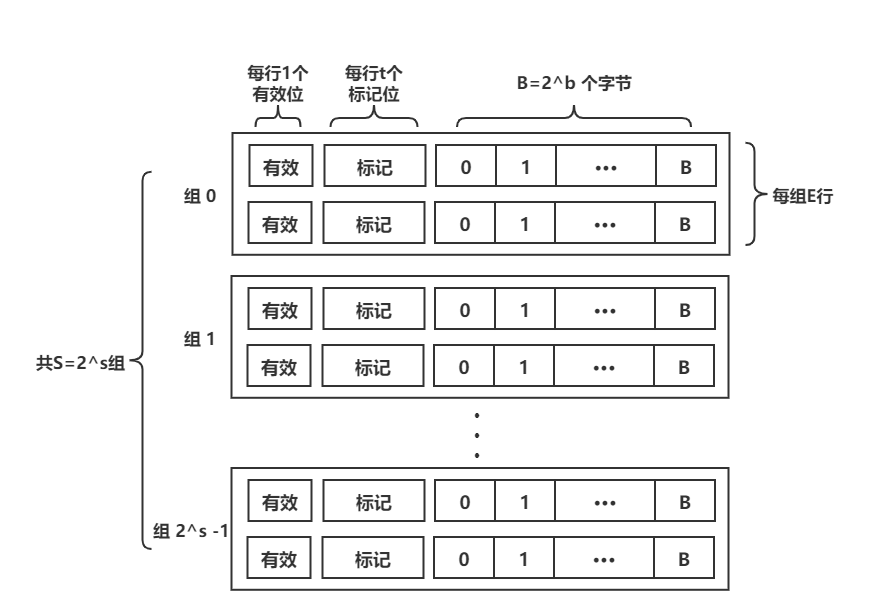
缓存行 Cache Line 是缓存中的最小单位,下面是一个 Cache Line 的结构示意图(很多 blog 都只说到了 Cache Line 由 2b 个字节组成,笔者曾经也这么以为)

主要有三部分组成:有效位,标记位和实际数据
有效位指明这个行是否包含有意义的信息
标记位是当前块的内存地址的位的一个子集,唯一标识存储在这个高速缓存行中的块在内存中的地址,这里许多博客都这样写,这里我认为仅靠标记位是不能唯一识别的,需要和组索引一起,而组索引是什么以及原因我们后面再来说明
实际数据部分又叫高速缓存块(看到很多博客说缓冲行为缓存块,可能原因在此吧),通常是 2b 个字节,大部分 CPU 的 Cache Line 是以 64 Bytes(为什么设计成 2b 个,我们后面再内存地址里解释)
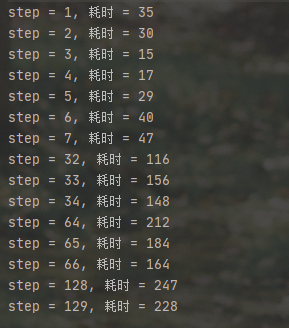
由于每次都只读取一个数据的话成本太高,效率低,又有局部性原理下,我们就读取内存数据到缓存时以 Cache Line 为单位读取的,所以要是每次读取的数据都隔着很远,因为每次读取的数据高速缓存中都找不到,所以要去内存中读入,那么就可能导致 CPU 执行速度的下降,我们可以写一个程序验证一下
//JVM 参数 -Xms4000m -Xmx4000m
package cn.arc.java.cpucache;
/**
* 通过改变步长查看运行速度
* @author arc3102
* @date 2021/5/6 22:04
*/
public class CpuCacheLineTest {
public static byte[] bytes;
public static void main(String[] args) {
bytes = new byte[1024*1024*1900];
for(int i = 0; i < bytes.length; i++) {
bytes[i] = 1;
}
int[] steps = new int[]{1,2,3,4,5,6,7,32,33,34,64,65,66,128,129};
for(int step : steps) {
forInStep(step);
}
}
public static void forInStep(int step) {
int count = 0;
long end;
long start = System.currentTimeMillis();
for(int i = 0; count < 15000000; i+=step) {
bytes[i] *= 3;
count++;
}
end = System.currentTimeMillis();
System.out.println("step = " + step + ", 耗时 = " + (end - start));
}
}
为了保证每次读取元素一致,加了一个计时器,运行结果很明显,步长大了,执行时间久了许多
Cache Set
高速缓存组,由一个或更多 Cache Line 组成,一个 CPU Cache 会被分为多组高速缓存组,通常是 2s 个,(为什么设计成 2s 个,我们后面再内存地址里解释)
此时我们可以用一下的图表示一个 CPU Cache
内存地址
介绍一个内存地址前,我们先大致了解一下 32 位和 64 位系统的区别,以及字的概念
计算机各个硬件之间进行信息传递是通过贯穿整个系统的是一组电子管道,称做总线,它携带信息字节并负责在各个部件间传递。
硬件之间进行信息交流需要有一个统一的标准,也就是二进制信息传递规则,为了高效考虑,通常总线被设计成传送定长的字节块,也就是字(word)。字中的字节数(即字长)是一个基本的系统参数,在各个系统中的情况都不尽相同。
操作系统中的 32 位(4 个字节)或 64 (8 个字节)位就叫总线的字长单位。
也就是说信息在硬件之间传输是定长的,64 位系统相比于 32 位系统可以一次传输的数据更大,这就使得 64 位的寻址空间更大(64 位可以表示的不同地址更多)
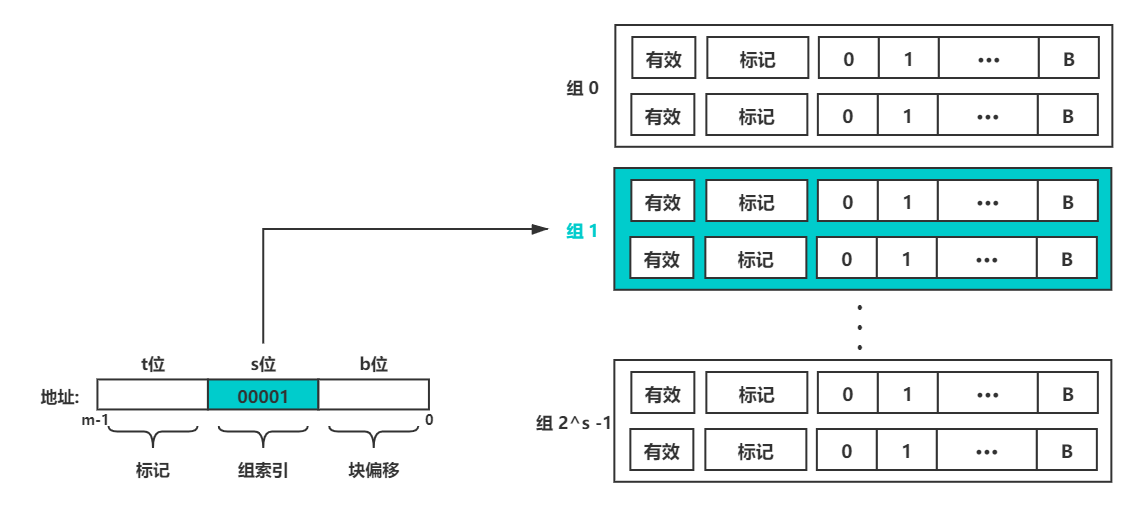
所以内存地址就是一个 32 位或 64 位的二进制数,但内存地址并不是用一个整数对内存空间进行简单地标识,我们给他的各部分赋予了不同的意义,使其与高速缓存配合使用;
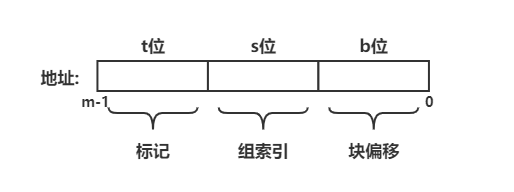
下面是一个内存地址各组成部分示意图(假设内存地址共 m 位)
看到这里,读者可能会疑惑,内存地址是连续的,像图中给把地址拆分成几个部分,那地址是否还连续呢,其实这并不冲突,我们抛去图中设置的各个部分,把地址当成一个整数,那么他就是连续的,每个地址代表一个字节。我们是在这个地址的基础之上把每部分赋予不同的意义;
内存地址的组成部分
主要分为三部分
- 标记:总共占 t 位,与 Cache Line 中的标记位一致,就是前文中说到标记位说的内存地址的位的一个子集
- 组索引:总共占 s 位,Cache Set 的索引值
- 块偏移:总共占 b 位,通过标记和组索引确定到一个 Cache Line 后,通过块偏移就可以确定该字节在高速缓存中的位置
各部分中的位数计算
首先我们给出 s 和 b 的计算:
记得之前说 Cache Set 的个数是 2s 个,以及高速缓存块由 2b 个字节组成吗
这里 s 和 b 就是组索引和块偏移所占的位数
至于 t 就是内存地址减去 s 位和 b 位后剩余的部分,t = m - s - t
CPU Cache 的映射方式
一个主存中地址映射到 CPU 高速缓存有三种映射方式:
- 直接映射
- 组相联
- 全相联
一个主存的地址映射到高速缓存中有三个步骤:
- 组选择(查找 Cache Set)
- 行匹配(查找 Cache Line)
- 字抽取(查找高速缓存块中一个字的起始字节)
直接映射
每个 Cache Set 只有一个 Cache Line 的映射方式就叫做直接映射
组选择
直接看图,内存地址中的组索引部分就对应 Cache Set
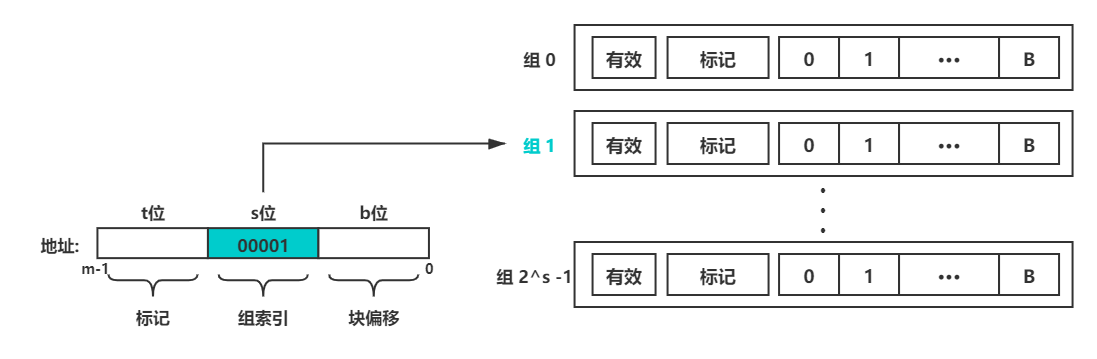
行匹配
直接映射中的行匹配很简单,因为一个 Cache Set 只有一个 Cache Line
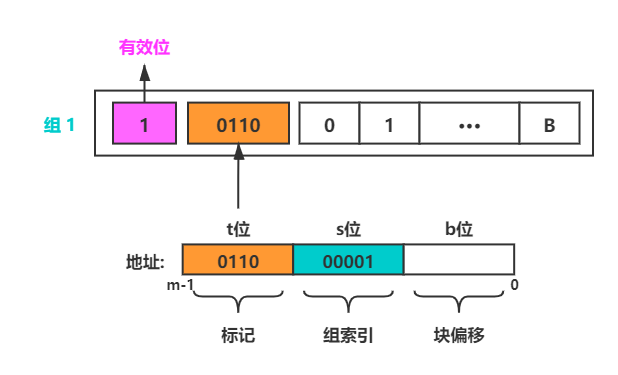
可能你会疑惑这个会有多个内存地址对应一个有效位,那么不就冲突了吗,确实有多个内存地址的有效位是一致的,这就回到了我们之前说的问题,有效位加上组索引才是一个地址的真正的位置,相同的有效位的地址他们的组索引是不同的
字抽取
将高速缓存块看成一个数组,块偏移的值(二进制数)就是数组的索引,这样我们就定位到了该地址在 CPU Cache 中的映射位置了,就是该字的起始字节,然后根据字长向后取字节即可
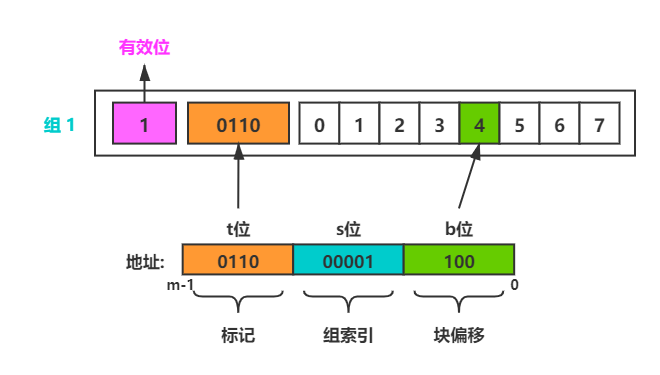
图解
❗️❗️❗️ 以下图中是以一个高速缓存块大小为单位,而不是字节为单位
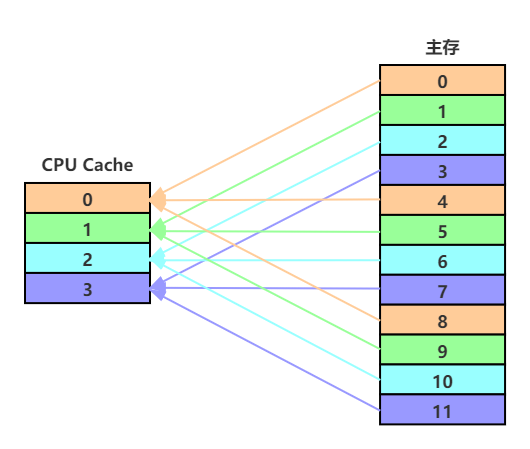
《深入理解计算机系统》中解释了为什么把中间位作为组索引,这里我懒得做图了,贴下截图
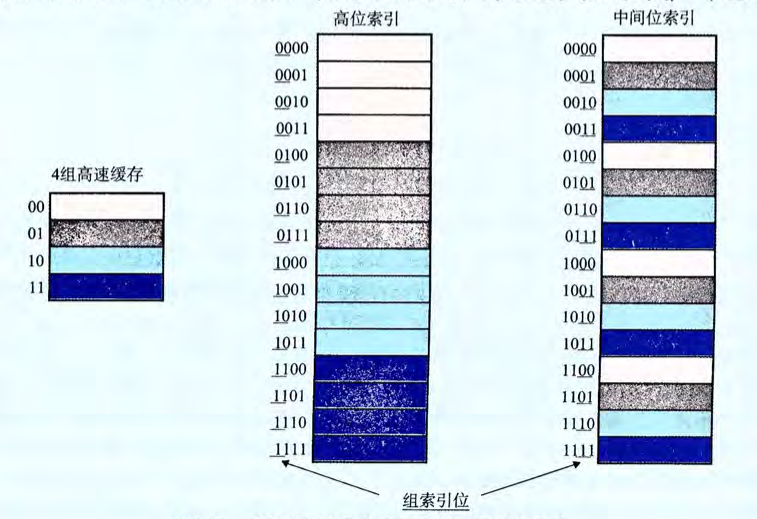
可以看出来如果使用了高位的组索引,内存中相邻的块被映射到了同一个 Cache Set 中,这样子的话,如果程序有良好的空间局部性,也就是一个数据周围的数据会被经常访问,那么就会出现,明明有其他 Cache Set 可以存放数据,但是由于这些数据都映射到一个 Cache Set,导致会发生频繁的 Cache Line 的替换,
而利用中间位可以将相邻的内存块映射到不同的 Cache Line,充分利用空间局限性,提高缓存的命中率(缓存命中该概念还没有讲,但我相信读者大致明白)
优缺点
由于每个地址的映射位置都固定,所以容易发生冲突,命中率低。但是映射速度快。
组相联
一个 CPU Cache 有两个或以上 Cache Set,一个 Cache Set 包含两个或以上的 Cache Line,的映射方式就是组相联
多个 Cache Set,一个 Cache Set 多个 Cache Line)
组选择
和直接映射是一样的,这里简单贴一下图
行匹配
一个内存块可以映射到一个固定的 Cache Set 的任意一个 Cache Line ,就是说组是固定的,行是可变的,所以在行匹配中涉及到要寻找到这一行,所以必须搜索组中每一行,找到有效的行并且标记位和地址相同的
字抽取
字抽取和直接映射是一样的,这里就不再重复了
图解
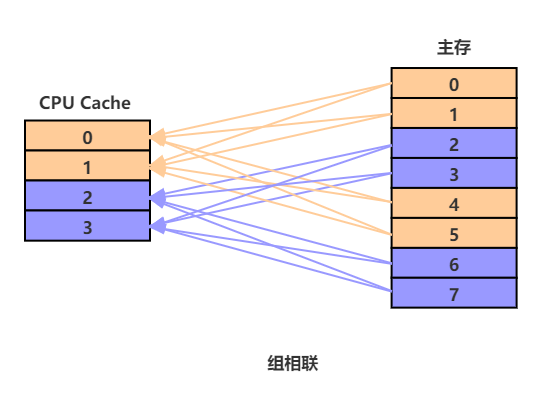
优缺点
比直接映射的命中率高,但是由于每个块在缓存中的映射位置不确定,在查找和读入数据时 速度慢
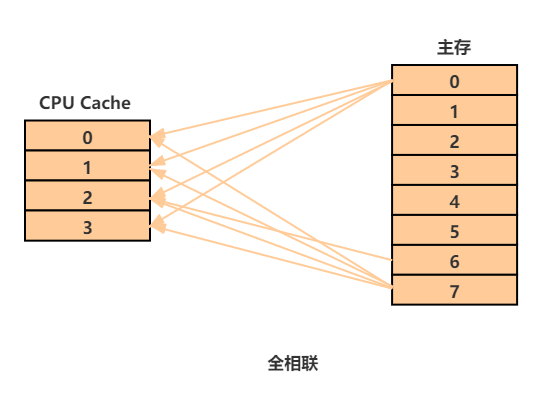
全相联
一个 CPU Cache 只有一个 Cache Set,该 Cache Set 包含 CPU Cache 的所有 Cache Line 就是全相联
组选择
由于只存在一个 Cache Set ,也就不存在组选择了,内存地址也就没有组索引了
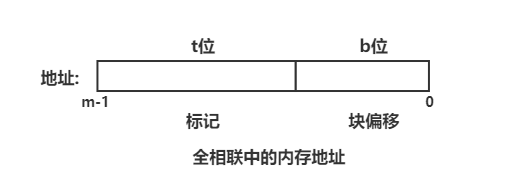
行匹配
和组相联类似的,全相联中行也可以映射到组中的任意一个内存块,只不过是只有一个组了
字抽取
字选择和直接映射和组相联都是一致的
图解
(避免图形过于复杂,只给出了两个内存块的映射关系,读者理解即可)
优缺点
命中率高,但是速度比组相联慢,在一些很小的缓存上使用















 3230
3230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









