









2-1 众数问题
20201004-20201010
参考链接:
https://www.cnblogs.com/program-ai-cv-ml-se-fighting/p/11944099.html
https://blog.csdn.net/hasfun/article/details/82688428
写文件:https://blog.csdn.net/u010925447/article/details/75046810
1.问题描述
给定含有n个元素的多重集合s,每个元素在S中出现的次数称为该元素的重数。多重集S中重数最大的元素称为众数。
例如:S={1,2,2,2,3,5}。多重集S的众数的2,其重数为3.
- 算法设计:对于给定的由N个自然数组成的多重集S,计算S的众数及其重数。
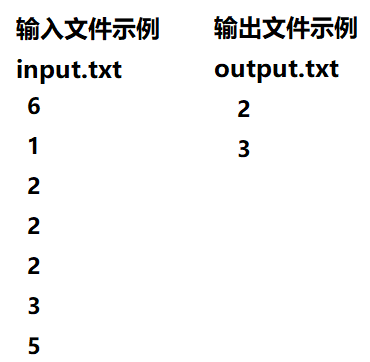
- 数据输入:输入数据有文件名为input.txt的问问文件内容提供。文件的第一行为多重集S中元素个数n留在接下来的n行中,每行有一个自然数。
- 结果输出:将计算结果输出到文件output.txt。输出文件有2行,第1行是众数,第2行数重数。
2.问题分析
2.1.分治分析
由于最近在学分治算法,所以就先拿分治来开个刀吧!
回顾题目:给定N个元素,求出元素中的众数以及众数重数。例如:2 2 2 1 3 5
思路:将元素集合进行排序(1 2 2 2 3 5),假定此时的中位数为众数(中位数2),指针左右滑动求出中位数的次数,依据中位数为中间集合进行划分,分为三个集合区域,如果左边、右边集合总长度 > 中位数次数,那么按照上述方法依次划分;否则(即总长度 < 中位数次数),那么此时中位数便是众数了,没有必要再继续划分了!
(如下图,m为随机取的中位数,空白部分为快速排序的基准值,i,j为分治快速排序时的左右下标,当ij在3处相遇时,,众数即中位数重数=1,左边部分长度=3》1,继续划分,右边=1,不划分)

2.2.非分治算法
这个是在偶然看见的一个算法,觉得很是巧妙,所以就记录下来了,但是这个损耗空间资源较大!
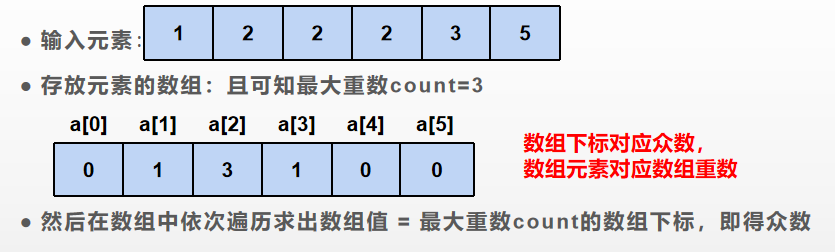
思路:先定义一个长度为1000的数组a(假设输入的数据大小 < 1000),输入的元素对应数组的下标,数组元素的值对应数组的重数,(假设输入2,a[2]++,所以下标 2-->元素,a[2]=1-->2的重数为1)输入时求出最大的重数。然后在数组中寻找元素值 = 最大重数的下标,即求出众数
3.代码实现
3.1.分治算法
// mode_function.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <stdio.h>
#include <iostream.h>
#include<fstream>//用于文件输入输出
#include <time.h>
#include <stdlib.h>
using namespace std;
#define N 1024
/*---交换函数*/
inline void swap(int &a,int &b)
{
int temp=a;a=b;b=temp;
}
/*---快速排序算法*/
//含有重复元素时候,例如:2 2 2 1 3 5
int Partition_sort(int a[],int low,int high)
{
int x=a[low];
int i=low,j=high;
while(i!=j){
while(x<=a[j] && i<j) j--;
if(i<j) {
int temp=a[i];
a[i]=a[j];
a[j]=temp;
i++;
}
while(x>=a[i] && i<j) i++;
if(i<j) {
int temp=a[i];
a[i]=a[j];
a[j]=temp;
j--;
}
}
// cout<<"low="<<low<<endl;------0
// cout<<"high="<<high<<endl;------5
// cout<<"i="<<i<<endl;------3
return i;
/*
for(int m=0;m<6;m++){
cout<<"第"<<m<<"个元素为"<<a[m]<<endl;
}
*/
}
//随取一个数作为基准值
int RandomizedPartition(int a[],int l,int r)
{
srand(time(NULL));
int i=rand()%(r-1)+1;
swap(a[i],a[l]);
return Partition_sort(a,l,r);
}
/*---按中位数划分成两段*/
void split(int a[],int m,int l,int r,int *left,int *rigth)
{
int med=a[m];
/*---从中位数开始向左右划分,知道遇见!=中位数*/
while(a[--(*left)] == med);
while(a[++(*rigth)] == med);
(*left)++;
(*rigth)--;
}
/*---分治求解*/
void mode(int *a,int l,int r,int *largest,int *count)//largest和count为地址
{
int m = RandomizedPartition(a,l,r);//--返回中位数
//cout<<"m="<<m<<endl;
int left=m,rigth=m;
split(a,m,l,r,&left,&rigth);//将数组a划分为3部分
if(*largest < rigth-left+1){//--保留众数个数最大值,以及众数下标
*largest=rigth-left+1;
*count=m;
}
if(left-1 > *largest) mode(a,l,left-1,largest,count);//左边的元素大于众数的个数,继续分治
if(r-rigth > *largest ) mode(a,rigth+1,r,largest,count);//右边元素大于众数个数,则继续分治
// cout<<"众数是:"<<count<<"\t重数是:"<<largest<<endl;
}
int main()
{
ifstream infile("input.txt",ios::in);
/*-------------读取元素的个数*/
int n;
infile>>n;
//cout<<n;
//元素读取
int a[N];
for(int i=0; i<n;i++)infile>>a[i];
infile.close();
//for(i=0; i<n;i++) cout<<a[i];
int largest=0,count=0;//large:重数,count:众数下标
mode(a,0,n-1,&largest,&count);
cout<<"众数是:"<<a[count]<<"\t重数是:"<<largest<<endl;
ofstream outfile;
outfile.open("out.txt");
cout << "Writing to the file" << endl;
outfile<<a[count]<< endl;
outfile<<largest<< endl;
outfile.close();
return 0;
}
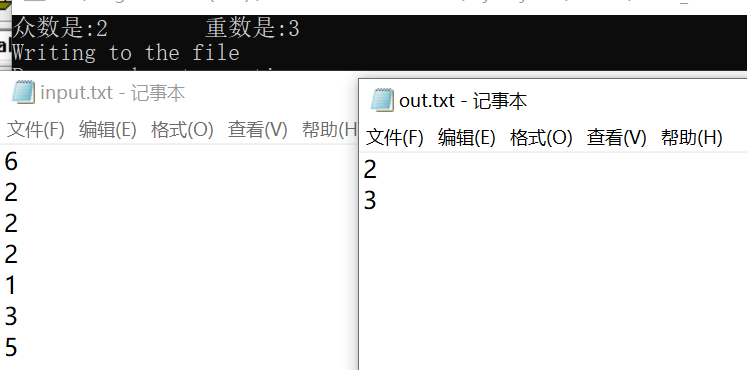
输出结果:
3.2.非分治算法
#include "stdafx.h"
#include <iostream>
#include<fstream>//用于文件输入输出
using namespace std;
#define N 1000
/*----------main()*/
int main()
{
ifstream infile("input.txt",ios::in);
/*-------------读取元素的个数*/
int n;
infile>>n;
//cout<<n;
//元素读取
int a[N]={0};
int elem,count=0;
//元素值对应数组下标,数组值对应重数
for(int i=0; i<n;i++)
{
infile>>elem;
a[elem]++;
if(a[elem] > count) count=a[elem];
}
infile.close();
//for(i=0; i<n;i++) cout<<a[i];
int b[N]={0},j=0;//存放众数的数组和下标
for(i=0;i<N;i++)
{
if(a[i] == count && i<N)
{
b[j]=i,j++;//i就是众数
}
}
//结果写入
ofstream outfile;
outfile.open("out.txt");
cout << "Writing to the file" << endl;
for(i=0;i<j;i++)
{
cout<<"众数为"<<b[i]<<"\t"<<"重数为"<<count<<endl;
outfile<<b[i]<<"\t"<<count<<endl;
}
outfile.close();
return 0;
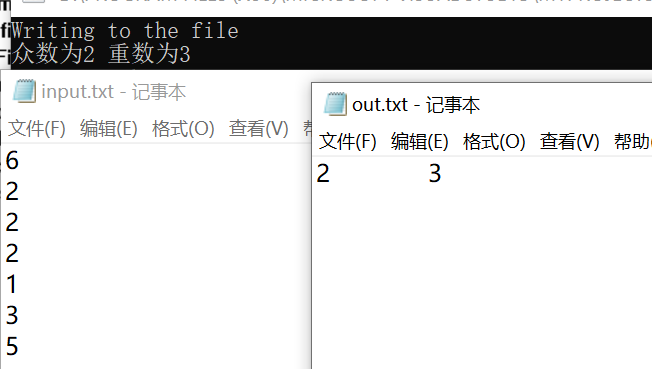
}输出结果:
tips
看代码如果看不太懂的话,建议读者按照代码把实际的数代入进去,对于代码理解很好哦!下面是我自己在理解代码时的手稿,字迹潦草,仅供参考!
分值算法:


非分治算法:
















 3102
3102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









