







 本文详细介绍了机器学习中数据预处理的几个关键步骤,包括使用`MinMaxScaler`进行数据归一化,`StandardScaler`进行数据标准化,以及如何处理缺失值。讨论了`SimpleImputer`的不同策略如使用平均值、中位数、0值填充空值。同时,还探讨了编码和哑变量的重要性,如`LabelEncoder`、`OrdinalEncoder`和`OneHotEncoder`的应用。此外,文章还提及了二值化和分段处理,如`Binarizer`和`KBinsDiscretizer`的使用场景。
本文详细介绍了机器学习中数据预处理的几个关键步骤,包括使用`MinMaxScaler`进行数据归一化,`StandardScaler`进行数据标准化,以及如何处理缺失值。讨论了`SimpleImputer`的不同策略如使用平均值、中位数、0值填充空值。同时,还探讨了编码和哑变量的重要性,如`LabelEncoder`、`OrdinalEncoder`和`OneHotEncoder`的应用。此外,文章还提及了二值化和分段处理,如`Binarizer`和`KBinsDiscretizer`的使用场景。
目录
1.preprocessing.MinMaxScaler归一化
2.preprocessing.StandardScaler标准化
StandardScaler和MinMaxScaler选哪个?
1.preprocessing.LabelEncoder标签编码
2.preprocessing.OrdinalEncoder特征编码
3.preprocessing.OneHotEncoder独热编码
1.sklearn.preprocessing.Binarizer二值化
2.preprocessing.KBinsDiscretizer分箱
一、数据无量纲化
#建模之前的流程
#1.获取数据
#2.数据预处理
#3.特征工程(挑选相关特征,或者生成新的特征(降维或者计算))
# (降低计算成本,提升模型上限)
#4.建模
#5.上线模块preprocessing:几乎包含数据预处理的所有内容
模块Impute:填补缺失值专用
模块feature_selection:包含特征选择的各种方法的实践
数据无量纲化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”。譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。
(一个特例是决策树和树的集成算法们,对决策树我们不需要无量纲化,决策树可以把任意数据都处理得很好。)
数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered或者Meansubtraction)处理和缩放处理(Scale)。
中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。
缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
1.preprocessing.MinMaxScaler归一化
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。
注意,Normalization是归一化,不是正则化,真正的正则化是regularization,不是数据预处理的一种手段。归一化之后的数据服从正态分布,公式如下:
在sklearn当中,我们使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有一个重要参数,feature_range,控制我们希望把数据压缩到的范围,默认是[0,1]。
#归一化的实现
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
data![]()
#如果换成表是什么样子?
import pandas as pd
pd.DataFrame(data)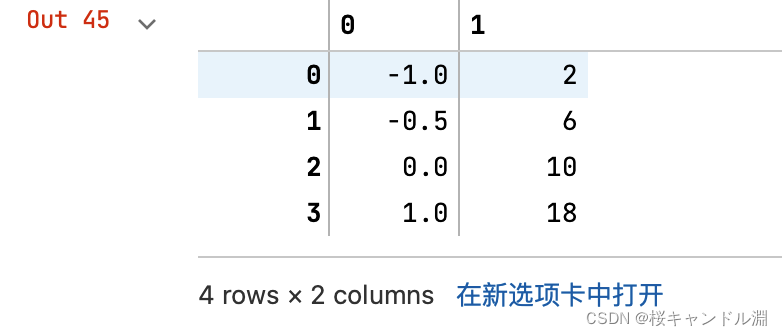
#实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #通过接口导出结果
#生成已经归一化完毕的数据,是一个矩阵
#这个矩阵和我们上面的那个原来的矩阵都是四行两列的
#其归一化的球阀就是对每一列中的每一个数据减去这一列数据中的最小值然后除以这一列当中的最大值减去这一列当中的最小值
#比方说我们下面的第0列中的[0][0]就是这一列中的最小值,所以是-1
#第0列中的[0][3]是这一列当中的最大值,所以是1
#最大值减去最小值就是2
#所以我们第0列的[0][1]就是将原本[0][1]的数据-0.5,减去-1.0得到0.5,然后用0.5除以2,得到了0.25
#
result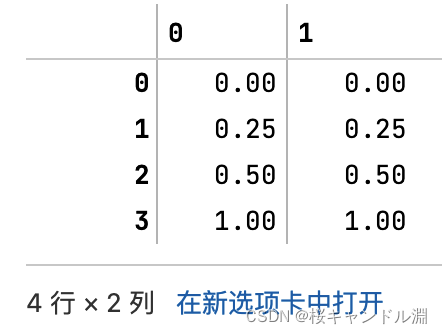
#上面的fit和transform完全可以被这一行代替
result_ = scaler.fit_transform(data) #训练和导出结果一步达成
result_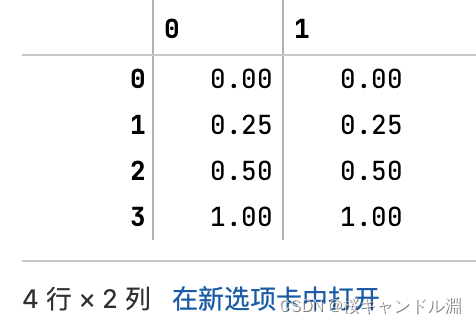
scaler.inverse_transform(result) #将归一化后的结果逆转,也就是返回我们原本的数据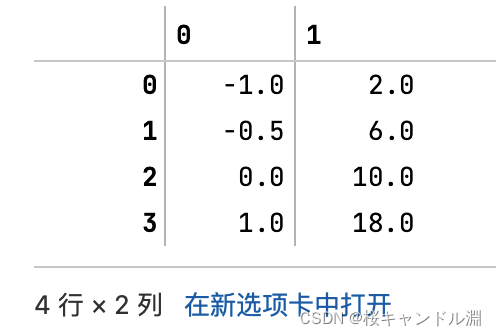
①归一化到[0,1]以外的范围
#使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5,10]) #依然实例化,指定将feature_range的归一化的范围限定在5-10之间
result = scaler.fit_transform(data) #fit_transform一步导出结果
result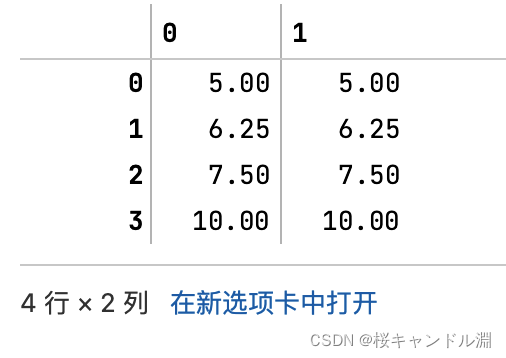
#当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了
#此时使用partial_fit作为训练接口
#实例化后的模型.partial_fit(传入的数据)
#scaler = scaler.partial_fit(data)②用numpy实现归一化
#用numpy实现归一化
import numpy as np
X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
#归一化
#对每一列(axis=0逐行按列进行运算)的数据执行下面的代码,也就是我们归一化的公式
#(x-最小值)/极差(最大值-最小值)
X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_nor
③逆转归一化
#逆转归一化
#逆归一化就是归一化之后的数据乘以原来数据的极差,然后加上原来每一列数据中的极小值
X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
X_returned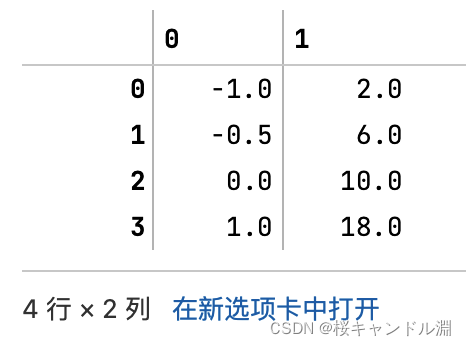
2.preprocessing.StandardScaler标准化
#数据的标准化
#让所有的数据减去一个值,从而让整个图像平移到某一个位置,例子:正太分布的数据都减掉其均值,将整个图像平移到以y轴为中心的图像preprocessing.StandardScaler
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
(数据减去均值再除以标准差来缩放就能将我们的数据变成均值为0,方差为1的标准正态分布了)
#导入相应的库
#standardscaler就是用于标准化数据的库
from sklearn.preprocessing import StandardScaler
#这里的数据依然是这两组数据,跟我们上面的数据是一模一样的
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
data=pd.DataFrame(data)
data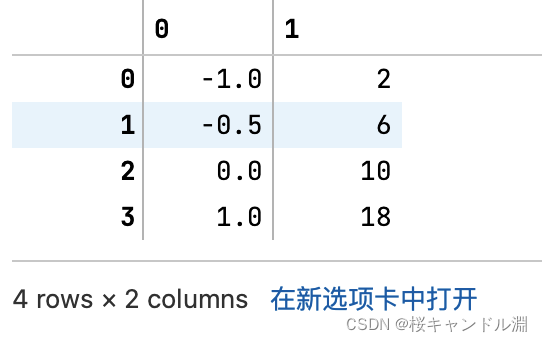
scaler = StandardScaler() #实例化
scaler.fit(data) #fit,本质是生成均值和方差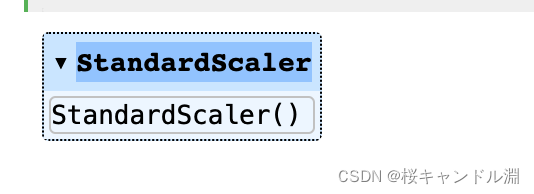
#这里的mean_所得出的是分别求出这两列的平均值
#不像numpy中使用min,max的时候需要传入轴向的参数,
#sklearn自动就会知道你想算的数据是按列计算的均值和方差
#因为没人会把一整行的数据,也就是一条记录的数据,压缩到0到1直接,或者是服从正太状态分布,这是没有意义的
#我们所要压缩的是我们的特征
scaler.mean_ #查看均值的属性mean_
#分别求出这两列的方差
scaler.var_ #查看方差的属性var_
x_std = scaler.transform(data) #通过接口导出结果
x_std
#我们注意到两类数据导出了相同的值,因为这两列数据虽然大小不同,但是其两列数据的分布是一样的,所以它们在被标准化之后,数据也会一模一样 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9025
9025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









