






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、课程笔记
2.2 逻辑回归
神经元 z= w1x1+w2x2+b
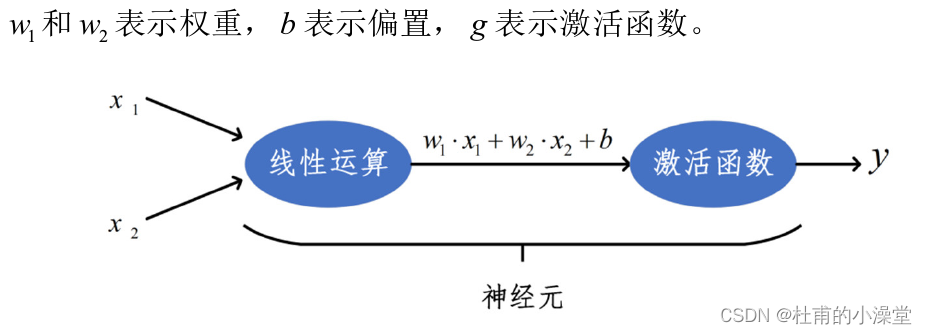
激活函数 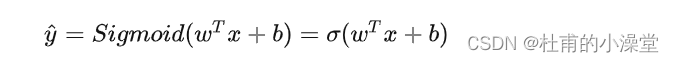
其中 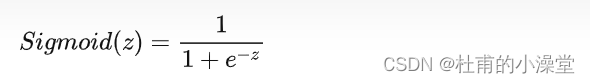
2.3 logistic回归损失函数
常见的损失函数多为均方误差损失函数

对于logistic regression 来说,一般不适用平方错误来作为Loss Function
平方错误损失函数一般是非凸函数(non-convex),进行梯度下降运算时,容易得到局部最优解,而不是全局最优解。因此要选择凸函数
2.4 梯度下降
代价函数:所有训练数据集的Loss function损失函数和的平均值
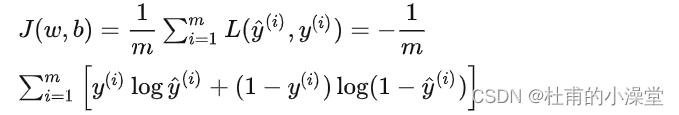
用梯度下降法(Gradient Descent)算法最小化Cost function,计算合适的w和b的值。

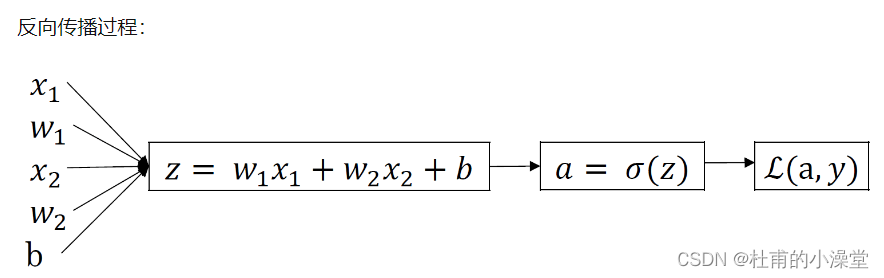 多个样本,使用numpy矩阵
多个样本,使用numpy矩阵
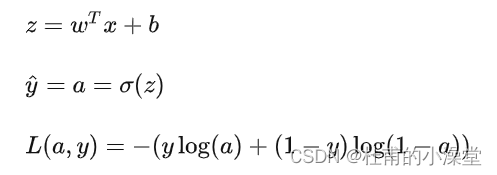
使用梯度下降计算dw,db

二、代码总结
1.作业1
math.sin(x)中x只能是1个数,不能是1组数
np.sin(x),x可以是个数组,返回也是数组
x = np.array([1, 2, 3])
print ("sigmoid_derivative(x) = " + str(sigmoid(x)))
print中前部分是str字符串,后面也需要转成str字符串,否则直接使用print(sigmoid(x))
2.作业1.3+2.11向量化+2.15广播
- a = np.random.randn(5),输出(5,)数组 a =
np.random.randn(5,1),输出(5,1)矩阵,推荐下面这种写法 - assert内嵌判断语句,对向量或数组的维度进行判断 assert(a.shape == (5,1))
- numpy中的数组变形有reshape和resize两种方法,reshape不会改变原数组的值,resize可以增删原数组的值
a=np.resize(变量,(维度))为resize固定用法
a = np.array([1,2,3]).reshape(1,3)
a=np.resize(a,(2,3))
print(a)
输出:
[[1 2 3]
[1 2 3]]
- reshape或shape前面放要变形的变量名,不能是np
import numpy as np
def image2vector(image):
v = image.reshape((image.shape[0]*image.shape[1]*image.shape[2],1))
# 错误写法:v = np.reshape; 报错:_reshape_dispatcher() missing 1 required positional argument: 'newshape'
# 原因:没有申明要在这reshape什么,reshape或shape前面放要变形的变量名,不能是np
return v
image = np.arange(36).reshape((4,3,3))
print(image2vector(image).shape)
1.4 行标准化
- 归一化后梯度下降的收敛速度更快,表现效果会更好。 归一化,就是将x更改为X/||X||
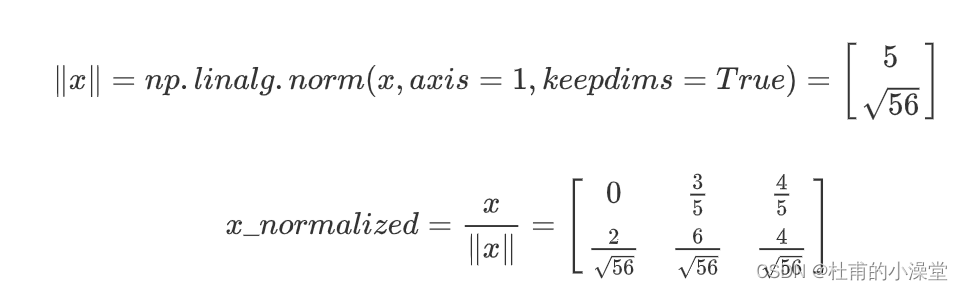
注意:
此处并非矩阵除法(求逆),而是对矩阵每行分别除以对应行范数;
矩阵标准化不改变矩阵的形状和维数
2.1 L1和L2损失函数
- L1损失函数定义
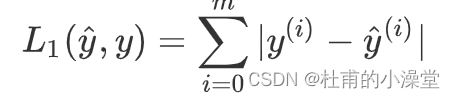
loss = np.sum(np.abs(y - yhat))
- L2损失函数定义
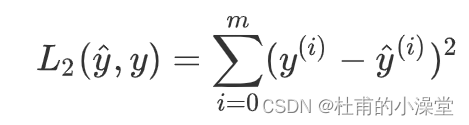
loss = np.dot((y - yhat),(y - yhat).T)
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









