






源码:link
我的环境:win11+torch1.7.1
1、数据准备
1.1 使用labelme标注数据集
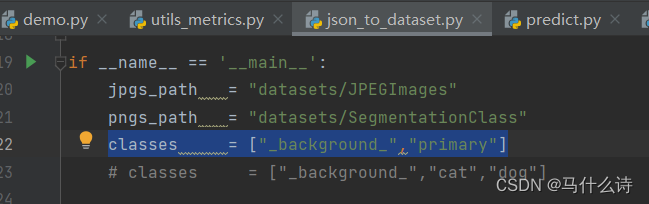
1.2 将标注好的图片文件和.json放在dataste/before/文件夹下,然后修改json_to_dataset.py文件中的classes,保留background,添加自己的类型。此后在JPEGImages中看到自己的图片,SegmentationClass看到制作好后的.json标注文件。
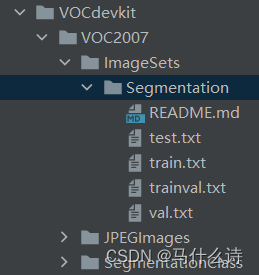
1.3 将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中,将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的SegmentationClass中。运行根目录下的voc_annotation.py,从而生成train.txt和val.txt。
2、训练
2.1 修改参数
修改train.py中的num_classes。num_classes用于指向检测类别的个数+1!训练自己的数据集必须要修改!
2.2 训练过程
下面就train.py代码进行具体分析
①设置参数
#---------------------------------#
# Cuda 是否使用Cuda
# 没有GPU可以设置成False
#---------------------------------#
Cuda = True
#---------------------------------------------------------------------#
# distributed 用于指定是否使用单机多卡分布式运行
# 终端指令仅支持Ubuntu。CUDA_VISIBLE_DEVICES用于在Ubuntu下指定显卡。
# Windows系统下默认使用DP模式调用所有显卡,不支持DDP。
# DP模式:
# 设置 distributed = False
# 在终端中输入 CUDA_VISIBLE_DEVICES=0,1 python train.py
# DDP模式:
# 设置 distributed = True
# 在终端中输入 CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py
#---------------------------------------------------------------------#
distributed = False
#---------------------------------------------------------------------#
# sync_bn 是否使用sync_bn,DDP模式多卡可用
#---------------------------------------------------------------------#
sync_bn = False
#---------------------------------------------------------------------#
# fp16 是否使用混合精度训练
# 可减少约一半的显存、需要pytorch1.7.1以上
#---------------------------------------------------------------------#
fp16 = False
#-----------------------------------------------------#
# num_classes 训练自己的数据集必须要修改的
# 自己需要的分类个数+1,如2+1
#-----------------------------------------------------#
num_classes = 2
#---------------------------------#
# 所使用的的主干网络:
# mobilenet
# xception
#---------------------------------#
backbone = "mobilenet"
#----------------------------------------------------------------------------------------------------------------------------#
# pretrained 是否使用主干网络的预训练权重,此处使用的是主干的权重,因此是在模型构建的时候进行加载的。
# 如果设置了model_path,则主干的权值无需加载,pretrained的值无意义。
# 如果不设置model_path,pretrained = True,此时仅加载主干开始训练。
# 如果不设置model_path,pretrained = False,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#----------------------------------------------------------------------------------------------------------------------------#
pretrained = False
#----------------------------------------------------------------------------------------------------------------------------#
# 权值文件的下载请看README,可以通过网盘下载。模型的 预训练权重 对不同数据集是通用的,因为特征是通用的。
# 模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。
# 预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好
# 训练自己的数据集时提示维度不匹配正常,预测的东西都不一样了自然维度不匹配
#
# 如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。
# 同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。
#
# 当model_path = ''的时候不加载整个模型的权值。
#
# 此处使用的是整个模型的权重,因此是在train.py进行加载的,pretrain不影响此处的权值加载。
# 如果想要让模型从主干的预训练权值开始训练,则设置model_path = '',pretrain = True,此时仅加载主干。
# 如果想要让模型从0开始训练,则设置model_path = '',pretrain = Fasle,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#
# 一般来讲,网络从0开始的训练效果会很差,因为权值太过随机,特征提取效果不明显,因此非常、非常、非常不建议大家从0开始训练!
# 如果一定要从0开始,可以了解imagenet数据集,首先训练分类模型,获得网络的主干部分权值,分类模型的 主干部分 和该模型通用,基于此进行训练。
#----------------------------------------------------------------------------------------------------------------------------#
model_path = "model_data/deeplab_mobilenetv2.pth"
#---------------------------------------------------------#
# downsample_factor 下采样的倍数8、16
# 8下采样的倍数较小、理论上效果更好。
# 但也要求更大的显存
#---------------------------------------------------------#
downsample_factor = 16
#------------------------------#
# 输入图片的大小
#------------------------------#
input_shape = [512, 512]
#----------------------------------------------------------------------------------------------------------------------------#
# 训练分为两个阶段,分别是冻结阶段和解冻阶段。设置冻结阶段是为了满足机器性能不足的同学的训练需求。
# 冻结训练需要的显存较小,显卡非常差的情况下,可设置Freeze_Epoch等于UnFreeze_Epoch,此时仅仅进行冻结训练。
#
# 在此提供若干参数设置建议,各位训练者根据自己的需求进行灵活调整:
# (一)从整个模型的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(不冻结)
# 其中:UnFreeze_Epoch可以在100-300之间调整。
# (二)从主干网络的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 120,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 120,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(不冻结)
# 其中:由于从主干网络的预训练权重开始训练,主干的权值不一定适合语义分割,需要更多的训练跳出局部最优解。
# UnFreeze_Epoch可以在120-300之间调整。
# Adam相较于SGD收敛的快一些。因此UnFreeze_Epoch理论上可以小一点,但依然推荐更多的Epoch。
# (三)batch_size的设置:
# 在显卡能够接受的范围内,以大为好。显存不足与数据集大小无关,提示显存不足(OOM或者CUDA out of memory)请调小batch_size。
# 受到BatchNorm层影响,batch_size最小为2,不能为1。
# 正常情况下Freeze_batch_size建议为Unfreeze_batch_size的1-2倍。不建议设置的差距过大,因为关系到学习率的自动调整。
#----------------------------------------------------------------------------------------------------------------------------#
#------------------------------------------------------------------#
# 冻结阶段训练参数
# 此时模型的主干被冻结了,特征提取网络不发生改变
# 占用的显存较小,仅对网络进行微调
# Init_Epoch 模型当前开始的训练世代,其值可以大于Freeze_Epoch,如设置:
# Init_Epoch = 60、Freeze_Epoch = 50、UnFreeze_Epoch = 100
# 会跳过冻结阶段,直接从60代开始,并调整对应的学习率。
# (断点续练时使用)
# Freeze_Epoch 模型冻结训练的Freeze_Epoch
# (当Freeze_Train=False时失效)
# Freeze_batch_size 模型冻结训练的batch_size
# (当Freeze_Train=False时失效)
#------------------------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 40
Freeze_batch_size = 24
#------------------------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
# UnFreeze_Epoch 模型总共训练的epoch
# Unfreeze_batch_size 模型在解冻后的batch_size
#------------------------------------------------------------------#
UnFreeze_Epoch = 80
Unfreeze_batch_size = 12
#------------------------------------------------------------------#
# Freeze_Train 是否进行冻结训练
# 默认先冻结主干训练后解冻训练。
#------------------------------------------------------------------#
Freeze_Train = True
#------------------------------------------------------------------#
# 其它训练参数:学习率、优化器、学习率下降有关
#------------------------------------------------------------------#
#------------------------------------------------------------------#
# Init_lr 模型的最大学习率
# 当使用Adam优化器时建议设置 Init_lr=5e-4
# 当使用SGD优化器时建议设置 Init_lr=7e-3
# Min_lr 模型的最小学习率,默认为最大学习率的0.01
#------------------------------------------------------------------#
Init_lr = 7e-4
Min_lr = Init_lr * 0.01
#------------------------------------------------------------------#
# optimizer_type 使用到的优化器种类,可选的有adam、sgd
# 当使用Adam优化器时建议设置 Init_lr=5e-4
# 当使用SGD优化器时建议设置 Init_lr=7e-3
# momentum 优化器内部使用到的momentum参数
# weight_decay 权值衰减,可防止过拟合
# adam会导致weight_decay错误,使用adam时建议设置为0。
#------------------------------------------------------------------#
optimizer_type = "sgd"
momentum = 0.9
weight_decay = 1e-8
#------------------------------------------------------------------#
# lr_decay_type 使用到的学习率下降方式,可选的有'step'、'cos'
#------------------------------------------------------------------#
lr_decay_type = 'cos'
#------------------------------------------------------------------#
# save_period 多少个epoch保存一次权值
#------------------------------------------------------------------#
save_period = 5
#------------------------------------------------------------------#
# save_dir 权值与日志文件保存的文件夹
#------------------------------------------------------------------#
save_dir = 'logs'
#------------------------------------------------------------------#
# eval_flag 是否在训练时进行评估,评估对象为验证集
# eval_period 代表多少个epoch评估一次,不建议频繁的评估
# 评估需要消耗较多的时间,频繁评估会导致训练非常慢
# 此处获得的mAP会与get_map.py获得的会有所不同,原因有二:
# (一)此处获得的mAP为验证集的mAP。
# (二)此处设置评估参数较为保守,目的是加快评估速度。
#------------------------------------------------------------------#
eval_flag = True
eval_period = 5
#------------------------------------------------------------------#
# VOCdevkit_path 数据集路径
#------------------------------------------------------------------#
VOCdevkit_path = 'VOCdevkit'
#------------------------------------------------------------------#
# 建议选项:
# 种类少(几类)时,设置为True
# 种类多(十几类)时,如果batch_size比较大(10以上),那么设置为True
# 种类多(十几类)时,如果batch_size比较小(10以下),那么设置为False
#------------------------------------------------------------------#
dice_loss = True
#------------------------------------------------------------------#
# 是否使用focal loss来防止正负样本不平衡
#------------------------------------------------------------------#
focal_loss = False
#------------------------------------------------------------------#
# 是否给不同种类赋予不同的损失权值,默认是平衡的。
# 设置的话,注意设置成numpy形式的,长度和num_classes一样。
# 如:
# num_classes = 3
# cls_weights = np.array([1, 2, 3], np.float32)
#------------------------------------------------------------------#
cls_weights = np.ones([num_classes], np.float32)
#------------------------------------------------------------------#
# num_workers 用于设置是否使用多线程读取数据,1代表关闭多线程
# 开启后会加快数据读取速度,但是会占用更多内存
# keras里开启多线程有些时候速度反而慢了许多
# 在IO为瓶颈的时候再开启多线程,即GPU运算速度远大于读取图片的速度。
#------------------------------------------------------------------#
num_workers = 4
#------------------------------------------------------#
# 设置用到的显卡
#------------------------------------------------------#
ngpus_per_node = torch.cuda.device_count()
if distributed:
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
device = torch.device("cuda", local_rank)
if local_rank == 0:
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) training...")
print("Gpu Device Count : ", ngpus_per_node)
else:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
local_rank = 0
#----------------------------------------------------#
# 下载预训练权重
#----------------------------------------------------#
if pretrained:
if distributed:
if local_rank == 0:
download_weights(backbone)
dist.barrier()
else:
download_weights(backbone)
②DeepLabV3+模型
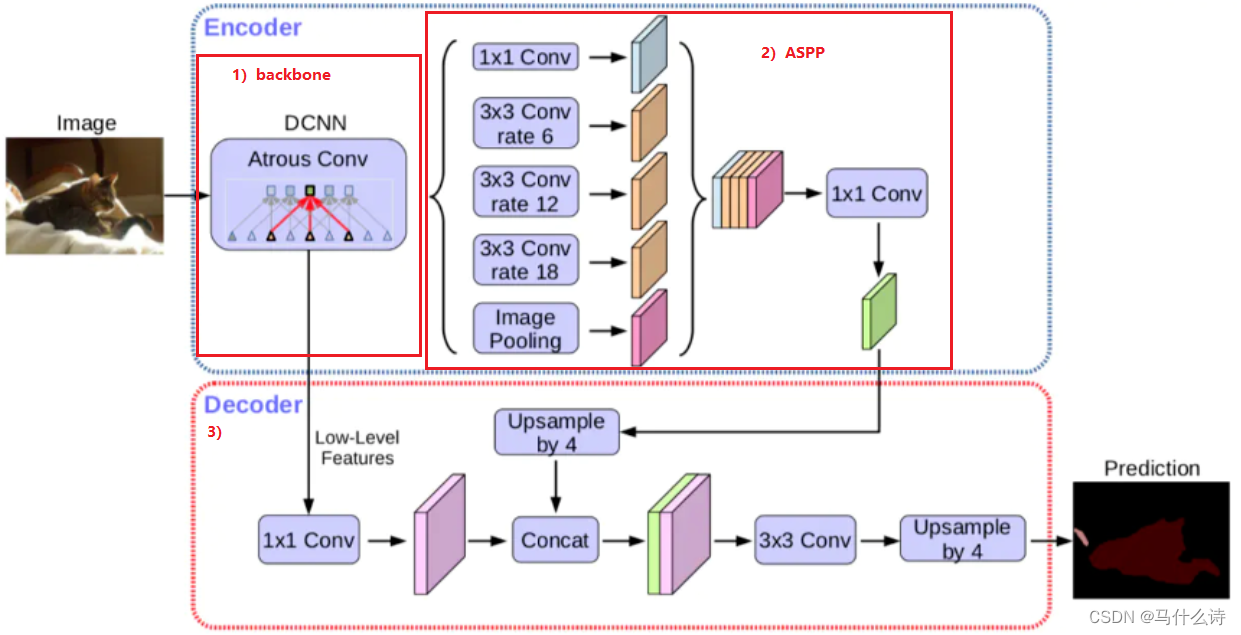
1)Encoder: backbone-MobileNetV2
class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
interverted_residual_setting = [
# t(扩展比例), c(输出通道数), n(重复次数), s(步长) 每个Inverted Residual Block的设置参数
[1, 16, 1, 1], # 256, 256, 32 -> 256, 256, 16
[6, 24, 2, 2], # 256, 256, 16 -> 128, 128, 24 2
[6, 32, 3, 2], # 128, 128, 24 -> 64, 64, 32 4
[6, 64, 4, 2], # 64, 64, 32 -> 32, 32, 64 7
[6, 96, 3, 1], # 32, 32, 64 -> 32, 32, 96
[6, 160, 3, 2], # 32, 32, 96 -> 16, 16, 160 14
[6, 320, 1, 1], # 16, 16, 160 -> 16, 16, 320
]
assert input_size % 32 == 0
# 根据宽度倍数调整输入通道数和最后输出通道数
input_channel = int(input_channel * width_mult)
self.last_channel = int(last_channel * width_mult) if width_mult > 1.0 else last_channel
# 512, 512, 3 -> 256, 256, 32
self.features = [conv_bn(3, input_channel, 2)]
# 通过遍历interverted_residual_setting列表中的每个设置参数,构建MobileNetV2模型的特征提取部分。
for t, c, n, s in interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n): # n=17
if i == 0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel, 1, expand_ratio=t))
input_channel = output_channel
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
self.features = nn.Sequential(*self.features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, n_class),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.mean(3).mean(2)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
class MobileNetV2(nn.Module):
def __init__(self, downsample_factor=8, pretrained=True):
super(MobileNetV2, self).__init__()
from functools import partial
model = mobilenetv2(pretrained)
# ---------------------------------------------------------#
# 把最后一层卷积剔除,也就是
# 17 InvertedResidual后跟着的 18 常规1x1卷积 剔除
# ---------------------------------------------------------#
self.features = model.features[:-1]
# ----------------------------------------------------------------------#
# 18 = 开始的常规conv + 17 个InvertedResidual,即features.0到features.17
# ----------------------------------------------------------------------#
self.total_idx = len(self.features)
# ---------------------------------------------------------#
# 每个 下采样block 所处的索引位置
# 即Output Shape h、w尺寸变为原来的1/2
# ---------------------------------------------------------#
self.down_idx = [2, 4, 7, 14]
# -------------------------------------------------------------------------------------------------#
# 若下采样倍数为8,则网络会进行3次下采样(features.0,features.2,features.4),尺寸 512->64
# 需要对后两处下采样block(步长s为2的InInvertedResidual)的参数进行修改,使其变为空洞卷积,尺寸不再下降
# 再解释一下,下采样倍数为8,表示输入尺寸缩小为原来的1/8,也就是经历3次步长为2的卷积
#
# 若下采样倍数为16,则会进行4次下采样(features.0,features.2,features.4,features.7),尺寸 512-> 32
# 只需要对最后一处 下采样block 的参数进行修改
# -------------------------------------------------------------------------------------------------#
if downsample_factor == 8:
for i in range(self.down_idx[-2], self.down_idx[-1]):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=4)
)
elif downsample_factor == 16:
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
# ----------------------------------------------------------------------#
# _nostride_dilate函数目的:通过修改卷积参数实现 self.features[i] 尺寸不变
# ----------------------------------------------------------------------#
def _nostride_dilate(self, m, dilate):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if m.stride == (2, 2):
m.stride = (1, 1)
if m.kernel_size == (3, 3):
m.dilation = (dilate//2, dilate//2)
m.padding = (dilate//2, dilate//2)
else:
if m.kernel_size == (3, 3):
m.dilation = (dilate, dilate)
m.padding = (dilate, dilate)
def forward(self, x):
# ------------------------------------------------------------------------------#
# low_level_features表示低(浅)层语义特征,只进行了features.0和features.2两次下采样,
# features.3的输出尺寸和features.2一样
# 输入为512x512,下采样倍数为16时,CHW:[24, 128, 128]
# ------------------------------------------------------------------------------#
low_level_features = self.features[:4](x)
# ------------------------------------------------------#
# x表示高(深)层语义特征,其h、w尺寸更小些
# 输入为512x512,下采样倍数为16时,CHW:[320, 32, 32]
# ------------------------------------------------------#
x = self.features[4:](low_level_features)
return low_level_features, x
2)Encoder: ASPP
#-----------------------------------------#
# ASPP特征提取模块
# 利用不同膨胀率的膨胀卷积进行特征提取
#-----------------------------------------#
class ASPP(nn.Module):
def __init__(self, dim_in, dim_out, rate=1, bn_mom=0.1):
super(ASPP, self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 1, 1, padding=0, dilation=rate,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=6*rate, dilation=6*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=12*rate, dilation=12*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=18*rate, dilation=18*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
# -----------------------------------------#
# 结合forward中第五个分支去看
# -----------------------------------------#
self.branch5_conv = nn.Conv2d(dim_in, dim_out, 1, 1, 0,bias=True)
self.branch5_bn = nn.BatchNorm2d(dim_out, momentum=bn_mom)
self.branch5_relu = nn.ReLU(inplace=True)
# -----------------------------------------#
# 五个分支堆叠后的特征,经1x1卷积去整合特征
# -----------------------------------------#
self.conv_cat = nn.Sequential(
nn.Conv2d(dim_out*5, dim_out, 1, 1, padding=0,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
def forward(self, x):
[b, c, row, col] = x.size()
#-----------------------------------------#
# 一共五个分支
#-----------------------------------------#
conv1x1 = self.branch1(x)
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
#-----------------------------------------#
# 第五个分支,全局平均池化+卷积
#-----------------------------------------#
global_feature = torch.mean(x,2,True)
global_feature = torch.mean(global_feature,3,True)
global_feature = self.branch5_conv(global_feature)
global_feature = self.branch5_bn(global_feature)
global_feature = self.branch5_relu(global_feature)
# ---------------------------------------------#
# 利用插值方法,对输入的张量数组进行上\下采样操作
# 这样才能去和上面四个特征图进行堆叠
# (row, col):输出空间的大小
# ---------------------------------------------#
global_feature = F.interpolate(global_feature, (row, col), None, 'bilinear', True)
#-----------------------------------------#
# 将五个分支的内容堆叠起来
# 然后1x1卷积整合特征。
#-----------------------------------------#
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
result = self.conv_cat(feature_cat)
return result
3)Decoder: 将浅层特征和深层特征进行特征融合,经过特征融合后的特征图将通过进一步的卷积操作和上采样操作,以生成最终的分割预测。
#-----------------------------------------#
# 获得两个特征层
# low_level_features: 浅层特征-进行卷积处理
# x : 主干部分-利用ASPP结构进行加强特征提取
#-----------------------------------------#
low_level_features, x = self.backbone(x)
x = self.aspp(x)
# -----------------------------------------#
# 对获取到的特征进行分类,获取每个像素点的种类
# 对于VOC数据集,输出尺寸CHW为[21, 128, 128]
# 21个类别,这儿就输出21个channel,
# 然后经过softmax以及argmax等操作完成像素级分类任务
# -----------------------------------------#
low_level_features = self.shortcut_conv(low_level_features)
#-----------------------------------------#
# 将加强特征边上采样
# 与浅层特征堆叠后利用卷积进行特征提取
#-----------------------------------------#
x = F.interpolate(x, size=(low_level_features.size(2), low_level_features.size(3)), mode='bilinear', align_corners=True)
x = self.cat_conv(torch.cat((x, low_level_features), dim=1))
x = self.cls_conv(x)
# -----------------------------------------#
# 通过上采样使得最终输出层,高宽和输入图片一样。
# -----------------------------------------#
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
3、预测
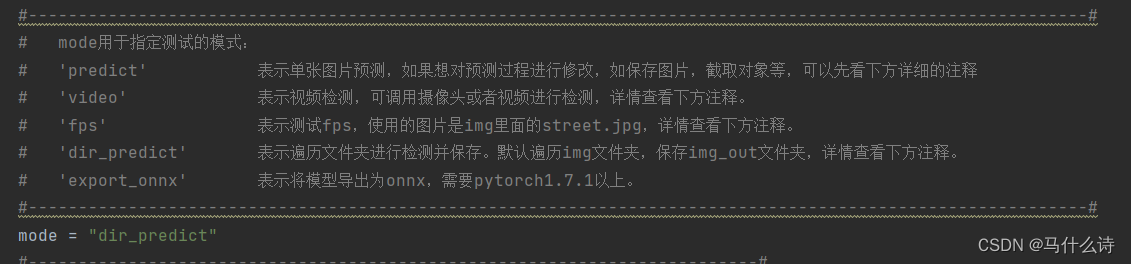
在predict.py文件中找到mode进行参数修改,选择指定的测试模式。
参考文章:
1、https://blog.csdn.net/hhb3329/article/details/127711336
2、https://blog.csdn.net/weixin_45377629/article/details/124083978















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









