







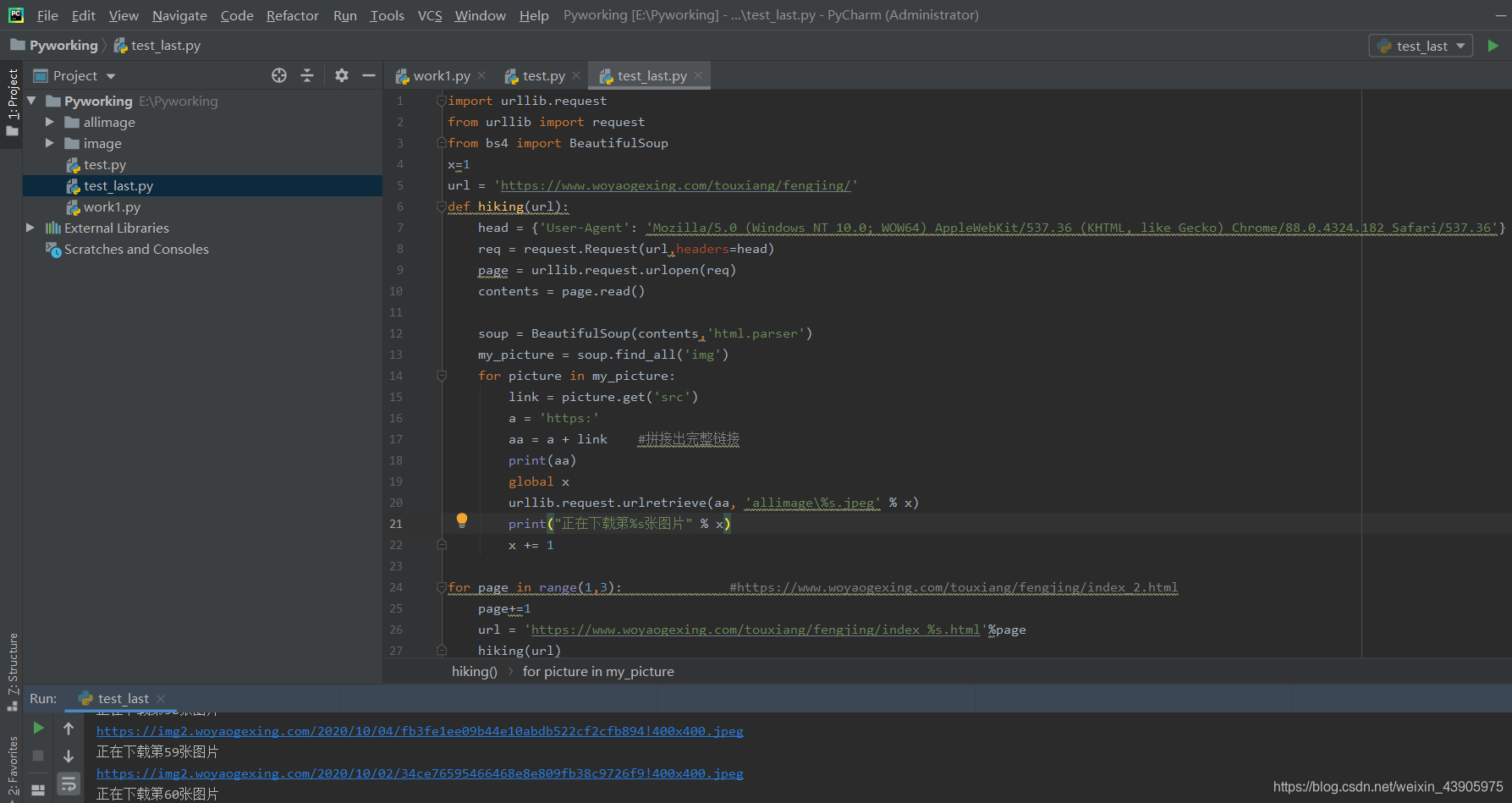
import urllib.request
from urllib import request
from bs4 import BeautifulSoup
x=1
url = 'https://www.woyaogexing.com/touxiang/fengjing/'
def hiking(url):
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'}
req = request.Request(url,headers=head)
page = urllib.request.urlopen(req)
contents = page.read()
soup = BeautifulSoup(contents,'html.parser')
my_picture = soup.find_all('img')
for picture in my_picture:
link = picture.get('src')
a = 'https:'
aa = a + link #拼接出完整链接
print(aa)
global x
urllib.request.urlretrieve(aa, 'allimage\%s.jpeg' % x)
print("正在下载第%s张图片" % x)
x += 1
for page in range(1,3): #https://www.woyaogexing.com/touxiang/fengjing/index_2.html
page+=1
url = 'https://www.woyaogexing.com/touxiang/fengjing/index_%s.html'%page
hiking(url)
















 73
73











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











