







目录
一. 前言
本文对C语言程序编译的预处理相关工作进行解读。文章第二章介绍了几个常见的预定义符号,第三章介绍了#define定义标识符和宏,第四章介绍了头文件的包含。
二. 预定义符号
__FILE__ 被编译的源文件的的文件路径和文件名
__LINE__ 所在指令的行号
__DATE__ 文件被编译的日期
__TIME__ 文件被编译的时间
__STDC__ 如果编译器遵循ANSI C标准,其值为1,否则不确定。经测试,VS2019编译器不支持使用符号__STDC__
演示代码2.1完成的功能是写日志,将源文件被编译时的源文件路径、指令所在行号、源文件被编译的日期以及源文件被编译的时间写入文本文件log.txt中。运行代码,相关内容被写入log.txt文件(见图2.1)。
演示代码2.1:
#include<stdio.h>
int main()
{
FILE* pf = fopen("log.txt", "w"); //以只写的方式打开文件log.txt
if (NULL == pf) //检验文件是否成功打开
{
perror("fopen");
return 1;
}
fprintf(pf, "%s\n", __FILE__); //将源文件路径写入log.txt
fprintf(pf, "%d\n", __LINE__); //将本行指令所在行号(14)写入log.txt
fprintf(pf, "%s\n", __DATE__); //将源文件被编译的日期写入log.txt
fprintf(pf, "%s\n", __TIME__); //将文件被编译的时间写入log.txt
fclose(pf); //关闭文件
pf = NULL;
return 0;
}
三. define定义标识符和宏
3.1 define定义标识符
define定义标识符的本质是替换
语法:#define name stuff
其中name表示替换后的符号名称,stuff表示被替换的符号
如:#define MAX 1000 MAX在程序中就表示1000
#define不仅可以替换数字,还可以替换关键字、语句、命令行等。
例如,演示代码3.1定义了符号CASE用于替换break;case,用于防止程序员在使用switch循环语句时忘记在每个case分支后添加break。程序中从第二个选择分支开始使用CASE,这就相当于除最后一个defalut分支以外其余每个分支后面都存在break。
演示代码3.1:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define CASE break;case
int main()
{
int input = 0;
scanf("%d", &input);
switch (input)
{
case 1:
printf("%d\n", 1);
CASE 2:
printf("%d\n", 2);
CASE 3:
printf("%d\n", 3);
default:
printf("default\n");
}
return 0;
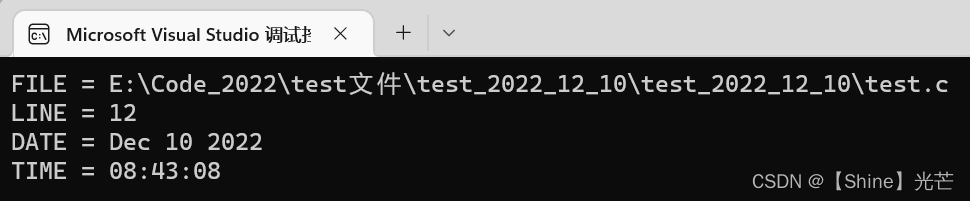
}如果sutff过长,可将其分为几行来书写,除最后一行外,每行后面都加一个反斜杠(续行符)。演示代码3.2使用LOG_PRINT标识符来替代写日志语句,将__FILE__、__LINE__、__DATE__、__TIME__ 放在一个printf中打印到屏幕上。运行程序,可以看到相关信息在屏幕上输出(见图3.1),证明替换是成功的。
演示代码3.2:
#include<stdio.h>
#define LOG_PRINT printf("FILE = %s\n",__FILE__);\
printf("LINE = %d\n", __LINE__);\
printf("DATE = %s\n",__DATE__);\
printf("TIME = %s\n",__TIME__);
int main()
{
LOG_PRINT;
return 0;
}
注意:#define定义标识符时,后面不要加分号。因为#define定义的标识符的本质是替换,在程序中,程序员一般会在使用标识符后添加分号,此时,如果在定义标识符时加了分号,就相当于一条语句后面出现了两个分号。这就有可能无端引入一条空语句,有时候会引起程序报错或是出现不符合预期的运行结果。
如:
#define MAX 1000;
max = MAX; //这条语句等价于max = 1000;; 语句后面两个分号,相当于两条语句
3.2 define定义宏
3.2.1 define定义宏的语法规则
宏的定义方式:#define name(parament-list)stuff
其中,parament-list是用逗号分隔的符号表,其可能出现在stuff中。
如: #define ADD(X,Y) ((X) + (Y))
警告:
- parament-list的左括号必须紧挨着name,如果两者之间有任何空格,parament-list都会被解释为stuff的一部分。
- stuff中的宏参数仅仅是替换,不默认添加括号。
演示代码3.3定义了宏,#define MUL(X,Y) X*Y,完成两个参数相加的功能,打印MUL(1,5)、MUL(1+5,1+5)以及3*MUL(1+2,5)的结果,分别为5、11和13。这是因为MAX(1,5)在预处理阶段被翻译为1*5,而由于定义宏时stuff中参数未被括号括起来,MUL(1+5,1+5)被翻译为1+5*1+5,3*MUL(1+2,5)被翻译为3*1+2*5。
演示代码3.3:
#include<stdio.h>
#define MUL(X,Y) X*Y
int main()
{
printf("%d\n", MUL(1, 5)); //1*5 = 5
printf("%d\n", MUL(1 + 5, 1 + 5)); //1+5*1+5 = 11
printf("%d\n", 3 * MUL(1 + 2, 5)); //3*1+2*5 = 13
return 0;
}注意:define定义宏时,所有参数都应用小括号括起来,同时,整个stuff也应添加括号。
如:#define MUL(X,Y) ((X)*(Y))
演示代码3.4将3.3中的宏替换为#define MUL(X,Y) X*Y,此时的运行结果变为:5、36、45。
演示代码3.4:
#include<stdio.h>
#define MUL(X,Y) ((X)*(Y))
int main()
{
printf("%d\n", MUL(1, 5)); //1*5 = 5
printf("%d\n", MUL(1 + 5, 1 + 5)); //(1+5)*(1+5) = 36
printf("%d\n", 3 * MUL(1 + 2, 5)); //3*((1+2)*5) = 45
return 0;
}两点注意事项:
- 在#define定义中可以出现使用其他define定义的符号,但宏不可以递归。
- 预处理器搜索#define定义的符号时,字符串常量的内容不被搜索。
如:
#define MAX 1000
printf("MAX = %d\n", MAX); //第一个MAX在字符串常量内部,不会被替换为1000
演示代码3.5定义了用define定义了一个参数和一个宏,分别为#define MIN 100 和 #define MAX(SPACE) MIN+SPACE,其中#define定义的宏使用了#define定义的符号。在主程序中向宏MAX传入参数50并打印MAX(50)的值,程序运行结果为150。证明#define定义中可以使用其他#define定义的符号。
演示代码3.5:
#include<stdio.h>
#define MIN 100
#define MAX(SPACE) MIN+SPACE
int main()
{
int space = 50;
printf("%d\n", MAX(space)); //150(100+50 = 150)
return 0;
}特别注意:要尽量避免将含有副作用的参数传入到宏中!
演示代码3.6定义了MAX宏,#define MAX(X,Y) ((X) > (Y) ? (X) : (Y)),这个宏使用条件运算符获取两个参数中较大的那个,其中有一个参数会被运算两次,比较一次,返回一次。在主程序中创建变量int i = 1,打印MAX(1,i++),在比较运算中,先运算一次i++,此时相当于判断1>1是否成立,显然不成立,应当返回表达式Y。但i++是带有副作用的表达式,这个宏返回的结果为2,且整个宏语句执行结束后i变为了3。因此,程序运行的结果为MAX = 2、i = 3。
由此可见,向宏中传入含有副作用的表达式是十分危险的,可能引发不可预期的后果。
演示代码3.6:
#include<stdio.h>
#define MAX(X,Y) ((X) > (Y) ? (X) : (Y))
int main()
{
int i = 1;
printf("MAX = %d\n", MAX(1, i++));
printf("i = %d\n", i);
return 0;
}3.2.2 #和##
首先明确,字符串具有自动连接的特点。
printf("hello world\n");
printf("hello " "world\n");
两个printf的运行结果相同,均为hello world
#的功能是将字符串参数转换为字符串。演示代码3.7定义宏,#define PRINT(VALUE)printf("the value of "#value" is:%d\n", (VALUE))。在主程序中定义int i = 2,将i+3作为参数传入PRINT宏,运行结果为the value of i+3 is:5
演示代码3.7:
#include<stdio.h>
#define PRINT(VALUE) printf("the value of "#VALUE" is:%d\n", (VALUE))
int main()
{
int i = 2;
PRINT(i + 3); //the value of i + 3 is:5
return 0;
}##的功能是将两个宏参数进行连接。演示代码3.8定义宏:#define PRINT(X,Y) printf("%d",X##Y),在主程序中定义整形变量int year2022 = 100,执行语句PRINT(year,2022),程序运行结果为100,即year2022的值,说明##将year和2022进行了连接。
演示代码3.8:
#include<stdio.h>
#define PRINT(X,Y) printf("%d",X##Y)
int main()
{
int year2022 = 100;
PRINT(year, 2022); //100,等价于printf("%d", year2022)
return 0;
}#和##并属侧边知识点,了解即可。
3.2.4 宏和函数的对比
宏的优点:
- 函数在调用和返回是均要耗费时间,宏的运算效率要高于函数。
- 函数要求形参被声明为特定类型(int、char、double、float等),而宏的参数无需关注类型。如:%d可以作为参数传给宏,但不能作为实参传给函数。
宏的缺点:
- 除非宏比较短,否则会大幅增加程序长度。
- 宏在预编译阶段就已经完成了替换,因此宏是无法编译的。
- 宏可能会带来运算优先级的问题,程序易出错。(所有应当在定义宏时将每个参数和整个stuff表达式用括号括起来)
- 如果传给宏的参数是有副作用的表达式,则极有可能使程序产生不可预期的结果。
宏相对于函数最大的优势是,可以实现一些函数无法实现的功能。这主要体现在宏可以传递类型作为参数而函数不行。
演示代码3.9定义了MALLOC宏来实现动态内存开辟,宏的两个参数分别为元素的个数和元素的类型。这就涉及到将类型作为宏的参数。
演示代码3.9:
#include<stdio.h>
#define MALLOC(num,type) (type*)malloc(num * sizeof(type))
int main()
{
int* ptr = MALLOC(5, int);
if (NULL == ptr)
{
perror("malloc");
return 1;
}
int i = 0;
for (i = 0; i < 5; i++)
{
*(ptr + i) = i;
printf("%d ", *(ptr + i)); // 0 1 2 3 4
}
printf("\n");
free(ptr);
ptr = NULL;
return 0;
}3.2.5 #undef移除一个宏
演示代码3.10定义了宏M表示100,在使用宏前,用#undef将宏移除,程序报错。
演示代码3.10:
#include<stdio.h>
#define M 10
int main()
{
#undef M
printf("%d\n", M); //宏M已经被移除,程序报错
return 0;
}四. 文件的包含
#include指令可以使另外一个文件被编译,就像它实际出现在#include指令的地方一样。如果一个文件被包含n次,那么他就实际被编译n次。
4.1 头文件被包含的方式
- 本地文件包含 #include "filename":先在源文件所在的目录下查找,如果该头文件未被找到,编译器就像查找库函数头文件一样在标准位置查找头文件。
- 库文件的包含#include<filename.h>:直接去标准路径下查找,如果找不到就报编译错误。
4.2 嵌套文件的包含
如果程序员在一份源文件中两次使用#include "filename"指令包含同一份头文件,那么就会造成文件内容的重复。
解决办法1:在头文件的文件首添加语句#pragma once //表明该文件只能被包含一次。
#pragma once
//头文件内容
解决方法2:使用条件编译
#ifndef __TEST_H__
#define __TEST_H__
//头文件内容
#endif
第一次包含头文件时__TEST_H__还未被定义,头文件内容会被编译。第二次包含头文件时__TEST_H__已被定义,头文件不会被再次编译。
全文结束,感谢大家的阅读,敬请批评指正。















 9986
9986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









