







起因:
学院整理档案,但是模板excel的时间,导员写成了去年。
目的:
写一个python脚本,把所有的excle中的某个替换掉。

开始找了个脚本,但是并不成功。。
后来输出excel中的文件,发现这个貌似不简单。
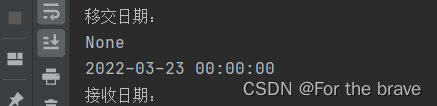
再百度一下,发现这里应该是一个时间数据,所以换方法。
搞定了,爽啊!!
一下子处理完的感觉!!!
代码:
import openpyxl
import re
import traceback
changeCells = 0
# replace the special content
"""
file: file path : str
mode: type of the operatoration : int
text: the string need to be replaceed : int or str
replaceText: replacement Text : int or str
"""
def changeData(file, mode, text, replaceText):
# load the file(*.xlsx)
wb = openpyxl.load_workbook(file)
# ! deal with one sheet
ws = wb.worksheets[0]
global changeCells
# get rows and columns of file
rows = ws.max_row
cols = ws.max_column
print(rows)
print(cols)
changeFlag = False
try:
for row in range(1, rows + 1):
for col in range(1, cols + 1):
content = ws.cell(row=row, column=col).value
#print(content)
#print(ws.cell(row, col).ctype)
if (content != None):
# mode1: fullmatch replacement
if (mode == 1):
if (content == text):
ws.cell(row=row, column=col+2).value = replaceText
changeFlag = True
changeCells += 1
# mode2: partial replacement
elif (mode == 2):
if (type(content) == str):
ws.cell(row=row, column=col).value = content.replace(
text, replaceText, 1)
changeFlag = True
changeCells += 1
# mode3: partialmatch and filling
elif (mode == 3):
if (type(content) == str):
ws.cell(row=row, column=col).value = content.replace(
text, text + replaceText, 1)
changeFlag = True
changeCells += 1
else:
return 0
# status_1: modified success
if (changeFlag):
wb.save(file)
return changeCells
# status_2: no modified
else:
return changeCells
# status_3: exception
except Exception as e:
print(traceback.format_exc())
# read the content of file
"""
file: file path : str
"""
# def rdxl(file):
# # load the file(*.xlsx)
# wb = openpyxl.load_workbook(file)
# # ! deal with one sheet
# ws = wb.worksheets[0]
# global changeCells
# # get rows and columns of file
# rows = ws.max_row
# cols = ws.max_column
# changeFlag = False
# cells = 0
# for row in range(1, rows + 1):
# for col in range(1, cols + 1):
# content = ws.cell(row=row, column=col).value
# print(content)
# cells += 1
# print('cells', cells)
import os
from os import path
# def scaner_file(url):
# file = os.listdir(url)
# for f in file:
# real_url = path.join(url, f)
# if path.isfile(real_url):
# print(path.abspath(real_url))
# # 如果是文件,则以绝度路径的方式输出
# elif path.isdir(real_url):
# # 如果是目录,则是地柜调研自定义函数 scaner_file (url)进行多次
# scaner_file(real_url)
# else:
#
# print("其他情况")
# pass
# print(real_url)
if __name__ == "__main__":
url="C:\\Users\LXH\Desktop\档案\ceshi\ZY2"
file = os.listdir(url)
for f in file:
real_url = path.join(url, f)
res = changeData(real_url, 1, '移交日期:', '2023/3/23')
print(real_url,':已修改 :', res, ' 处')
#scaner_file("C:\\Users\LXH\Desktop\档案\ceshi\ZY2")
#res = changeData('C:\\Users\LXH\Desktop\档案\ceshi\ZY2\ZY2106101-陈新月.xlsx', 1, '移交日期:', '2023/3/23')
#if (res != None):
# print('已修改 ', res, ' 处')
# else:
# print('操作失败:\n'+res)
#rdxl('C:\\Users\LXH\Desktop\档案\ceshi\ZY2\ZY2106101-陈新月.xlsx')
总结:
因为那个2022/3/23的格式一直搞不定,后面就直接用它前面那个单元格,然后列数加2来解决了,也很简单。。
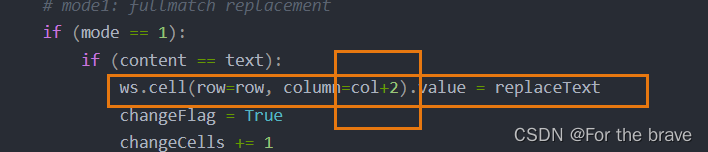
开心,很有成就感。














 1204
1204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









