






整体结构
def forward(self, img):
# embedding
x = self.to_patch_embedding(img)
b, n, _ = x.shape
# cls token
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
# position embedding
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
# transformer (encoder,decoder)
x = self.transformer(x)
# 平均token,或者取clstoken进行后处理
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
# 输出分类
x = self.to_latent(x)
return self.mlp_head(x)
-
embedding
-
clstoken
-
position embedding
-
transformer(encoder,decoder)
-
mean token or clstoken
-
classifer
embedding
(B,L,V)-embedding(fc(V→dim))→(B,L,dim)。V代表词汇表长度,dim代表embedding后的表示向量长度
文本:词表通过embedding方法转换成d_model维度的向量
图像:vit:patch方法拉平后通过一个fc层转化成向量
detr:通过cnn抽取特征后再拉平
如果是图像的话emdding后会增加一个cls_token
img patch
vit中将图像进行patch处理转化成transformer可以接受的形式
patch_h,patch_w代表一个patch的宽高
(B,C,H,W)-patch→(B, H/patch_hW/patch_w, patch_hpatch_w*C)
H/patch_h*W/patch_w→patch的个数
Clstoken
embedding的向量中增加一个cls token。后续可以只用clstoken来进行任务。也可以使用所有token的平均值。
增加clstoken的好处
1、该token随机初始化,并随着网络的训练不断更新,它能够编码整个数据集的统计特性;
2、该token对所有其他token上的信息做汇聚(全局特征聚合),并且由于它本身不基于图像内容,因此可以避免对sequence中某个特定token的偏向性;
3、对该token使用固定的位置编码能够避免输出受到位置编码的干扰。ViT中作者将class embedding视为sequence的头部而非尾部,即位置为0。
https://blog.csdn.net/chumingqian/article/details/124660657
positionencodding
位置编码:绝对位置编码,相对位置编码,可学习位置编码
encoder
整体结构
def forward(self, x, src_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=src_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
return x
attention
-
生成qkv矩阵
通过三个fc矩阵将输入输出三个矩阵,q,k,v
(B,L,dim)→fc(dim,dim)→(B,L,dim)
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# q,k,v
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
-
多头注意力机制
拆分多头
(B,L,D)->(B,L,nhead,D/nhead)-transpose->(B,nhead,L,D/nhead)
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
# (B,L,D)->(B,L,nhead,D/nhead)-transpose->(B,nhead,L,D/nhead)
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return tensor
权重计算
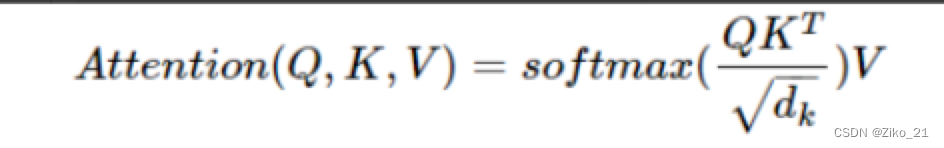
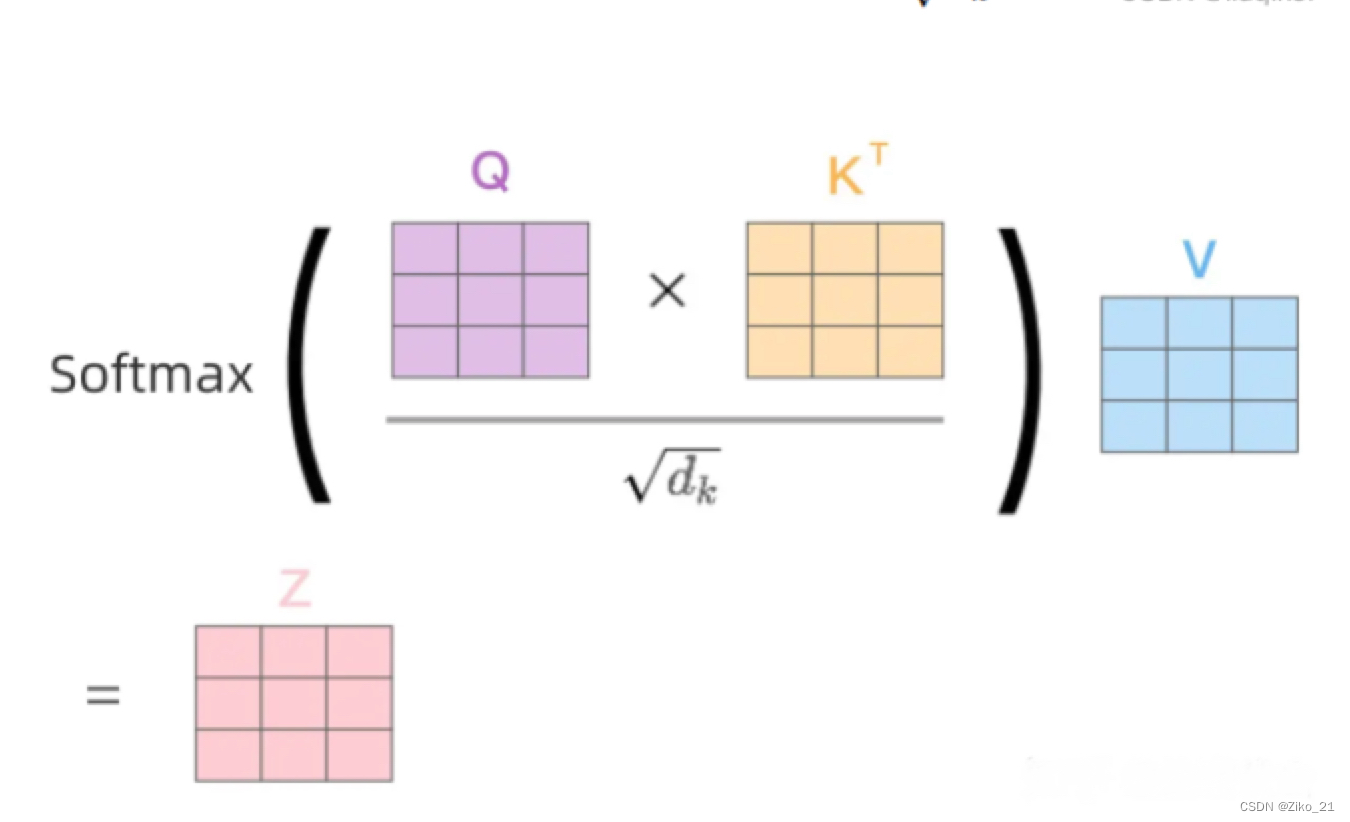
def forward(self, q, k, v, mask=None, e=1e-12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
# 将掩码中0的值填充为-10000
score = score.masked_fill(mask == 0, -10000)
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score
注意力计算中,query(Q)、key(K)和value(V)可以有不同的维度,但是它们的某些维度必须匹配以便进行计算。
-
query的维度是[seq_len_q, batch_size, embed_dim],即[l_q, b, d_model]。 -
key和value的维度是[seq_len_kv, batch_size, embed_dim],即[l_kv, b, d_model]。 -
q的维度l_q可以与l_kv不同。但是kv的维度必须一样
-
q@kT→(l_q,d_model)*(l_kv,d_model)→(l_q,l_kv)
( q @ k T ) a b @ v (q@kT)\sqrt{ab}@v (q@kT)ab@v
→(l_q,l_kv)*(l_kv,d_model)→(l_q,d_model)
最终得到与q相同的维度
多头合并
(B,head,L,d)→(B,L,dim) 还原回未分头的状态
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.size()
d_model = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
return tensor
最后再接一个fc层
self.w_concat = nn.Linear(d_model, d_model)
LN
使用LN而不是用BN
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
var = x.var(-1, unbiased=False, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out
FFN
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
decode
跟encode结构相似,但是有两个multihead,第一个qkv都是来自于tgr,mask用tgr的mask。
第二个multihead,q是tgt,kv来自于encode
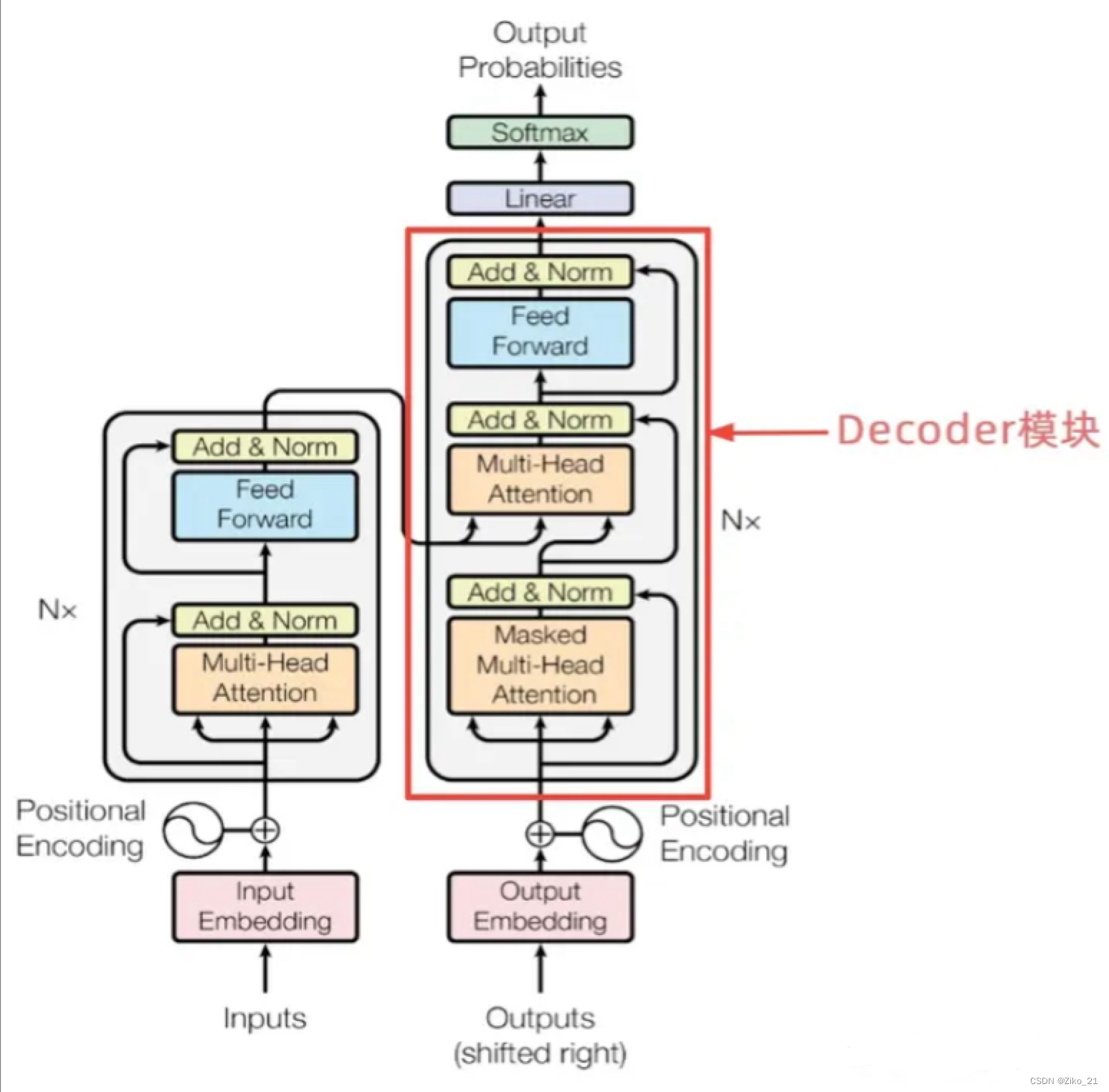
def forward(self, dec, enc, trg_mask, src_mask):
# 1. compute self attention
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=trg_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
if enc is not None:
# 3. compute encoder - decoder attention
_x = x
## k,v是encode的
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=src_mask)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
# 5. positionwise feed forward network
_x = x
x = self.ffn(x)
# 6. add and norm
x = self.dropout3(x)
x = self.norm3(x + _x)
return x
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









