







文章目录
如题目所示,本篇的思想是Prompt也经过预训练,得到Prompt的表示,然后在固定任务的数据集上微调。
预训练方法
符号: P V P = < f , v > PVP=<f, v> PVP=<f,v> to denote this pattern-verbalizer pair,即输入 f f f与输出端 v v v的表示。
作者把所有的下游任务分为三种大任务:Sentence-Pair Classification,Multiple-Choice Classification,Single-Sentence Classfication,大任务中又包含若干种特定的小任务。作者针对这三种任务提出了相应的预训练模板 P V P i p r e = < f i p r e , v i p r e > PVP_i^{pre}=<f_i^{pre}, v_i^{pre}> PVPipre=<fipre,vipre>,i 代表第 i 种大任务。后来,作者又把这几个任务unifying为 Multiple-Choice Classification。经过预训练以后,再在那种大任务的具体小任务的数据集上微调,得到该小任务的模板 P V P i k = < f i k , v i k > PVP_i^k=<f_i^{k}, v_i^{k}> PVPik=<fik,vik>,代表第 i 种大任务,第k个特定的小任务的模板。
预训练过程:
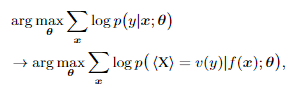
Sentence-Pair Classification
作者把 Sentence-Pair Classification 转换成3分类任务,
l
a
b
e
l
s
:
Y
=
[
0
,
1
,
2
]
labels : \mathcal{Y}=[0, 1, 2]
labels:Y=[0,1,2]。label 0 代表来自不同document的句子对;label 1 代表来自相同document的,不相邻的句子;label 2 代表来自相邻的两个句子。
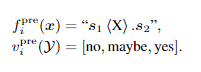
在微调时:对于只有两种label可以令
v
i
k
(
Y
)
=
[
no, yes
]
v_{i}^{k}(\mathcal{Y})=[\text { no, yes }]
vik(Y)=[ no, yes ];对于三种label,令
v
i
k
=
v
i
p
r
e
v_{i}^{k}=v_i^{pre}
vik=vipre;对于算两个句子之间的概率,可以转换成计算{no, yes}的概率。
Multiple-Choice Classification
对于多项选择任务的label,
Y
=
[
1
,
2
,
3
,
4
,
5
,
6
]
\mathcal{Y} = [1,2,3,4,5,6]
Y=[1,2,3,4,5,6];输入
x
=
(
s
q
,
s
1
,
s
2
,
s
3
,
s
4
,
s
5
,
s
6
)
x=(s_q,s_1,s_2,s_3,s_4,s_5,s_6)
x=(sq,s1,s2,s3,s4,s5,s6),其中,一个句子与
s
q
s_q
sq相临,其他句子来自不同的document。
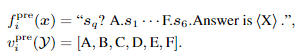
在微调时:不改变PVP,即
P
V
P
i
k
=
P
V
P
i
p
r
e
PVP_i^{k}=PVP_i^{pre}
PVPik=PVPipre。
Single-Sentence Classfication
作者把Single-Sentence Classfication设置成预测伪标签的任务,用 Fine-tuned PLMs 生成 伪label。
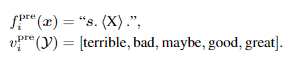
在微调时:不改变PVP,即
P
V
P
i
k
=
P
V
P
i
p
r
e
PVP_i^{k}=PVP_i^{pre}
PVPik=PVPipre。
Unifying Task Formats
作者提出另一种方法,即把所有任务转换成 Multiple-Choice Classification 。具体来说,对于 Sentence-Pair Classification , s q s_q sq是两个句子的拼接,然后有三个选项:maybe,yes,no,对于 Single-Sentence Classfication , s q s_q sq是一个句子,选项是对应的labels。
实验结果
其中 FT 的部分展示了各种尺寸 T5 模型的全模型微调结果;PT 的部分展示了 PPT 和其他基线的结果。第一个基线是 Vanilla PT,其中的 soft token 是从正态分布中随机初始化的;第二个基线是混合策略;然后该研究还考虑了 Lester 等人(2021)使用的 LM Adaption。其中 T5 模型通过语言建模进一步预训练 10K 步,以减少预训练和微调之间的差距。除了 PPT 以外,该研究还测试了 PPT 的两种变体:一种是 Hybrid PPT,将精心设计的 hard prompt 与预训练的 soft prompt 相结合;另一种是 Unified PPT,其中所有任务都以 multiple-choice 的格式统一。
-
随着参数数量的增加,FT 的性能有所提升。
-
在大多数数据集中,PPT 明显优于 Vanilla PT 和 LM Adaption。
-
PPT 在所有中文数据集和大多数英文数据集上都优于 10B 模型的 FT。
-
PPT 在大多数数据集上会产生较小的方差,相比之下,一般的 few-shot 学习常存在不稳定性,例如 Vanilla PT。

以上所有数据集的分类标签都少于 5 个,该研究进一步在超过 5 个标签的数据集上测试了 Unified PPT,实验结果如下表 5 所示。

研究者探究了当训练样本数量增加时 FT、PT 和 PPT 的比较结果。下图 4 展示了这些方法在 RACEm 和 CB 数据集上的趋势。从中可以观察到,对于从 32 到 128 个样本,PPT 始终优于 Vanilla PT,当数量增长到 256 时,三种方法的性能逐渐收敛。

引用:
https://arxiv.org/pdf/2109.04332.pdf
一个「PPT」框架,让超大模型调参变简单:清华刘知远、黄民烈团队力作















 3848
3848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









