







- 逻辑架构
- 架构图

- 组件说明
-
Client
提供了访问HBase的一系列API接口,如Java Native API、Rest风格http API、Thrift API、scala等,并维护cache来加快对HBase的访问
-
Zookeeper
保证任何时候,集群中只有一个master
存贮所有Region的寻址入口。
实时监控Region server的上线和下线信息,并实时通知Master
存储HBase的schema和table元数据
-
Master
为Region server分配region
负责Region server的负载均衡
发现失效的RegionServer并重新分配其上的region
管理用户对table的增删改操作
-
RegionServer
(1)Region server维护region,处理对这些region的IO请求,向HDFS文件系统中读写数据。
一个RegionServer由多个region组成,一个region由多个store组成,一个store对应一个CF(列族),而一个store包括1个storefile或多个, 每个storefile以HFile格式保存在HDFS上。写操作先写入memstore,当memstore中的数据达到某个阈值时,RegionServer会启动flashcache进程写入storefile,每次写入形成单独的一个storefile。
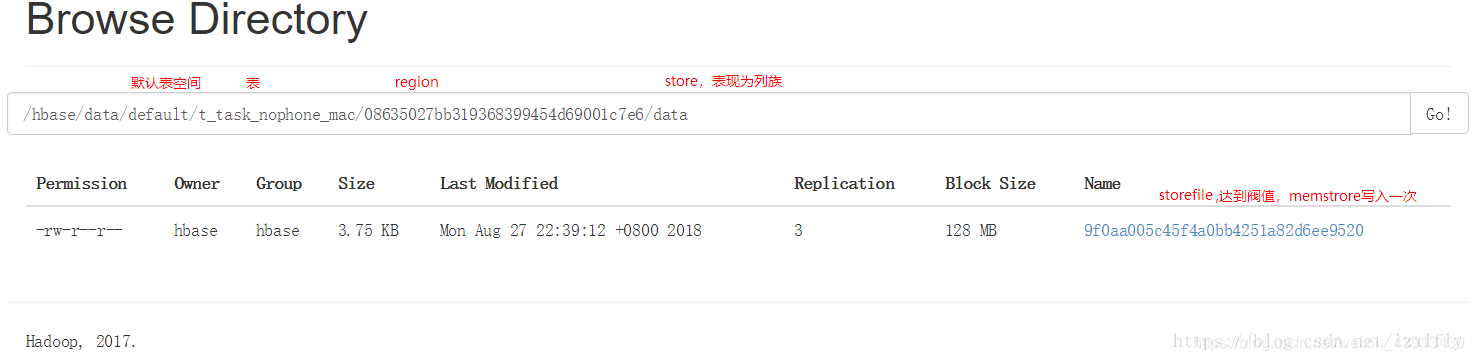
(2)Region server负责切分在运行过程中变得过大的region
每个表一开始只有一个region,随着表数据不断插入,数据越来越多,storefile也越来越大,当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),minor主要是合并一些小的文件,不做删除,清理操作,而majar在合并过程中会进行版本合并和删除工作,形成更大的storefile。
(3)当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个新的region(裂变),每个region保存一段连续的数据片段,如此往复,就会有越来越多的region,并由Master分配到相应的RegionServer服务器,这样一张完整的表被保存在多个Regionserver 上,实现负载均衡。
-
Region
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
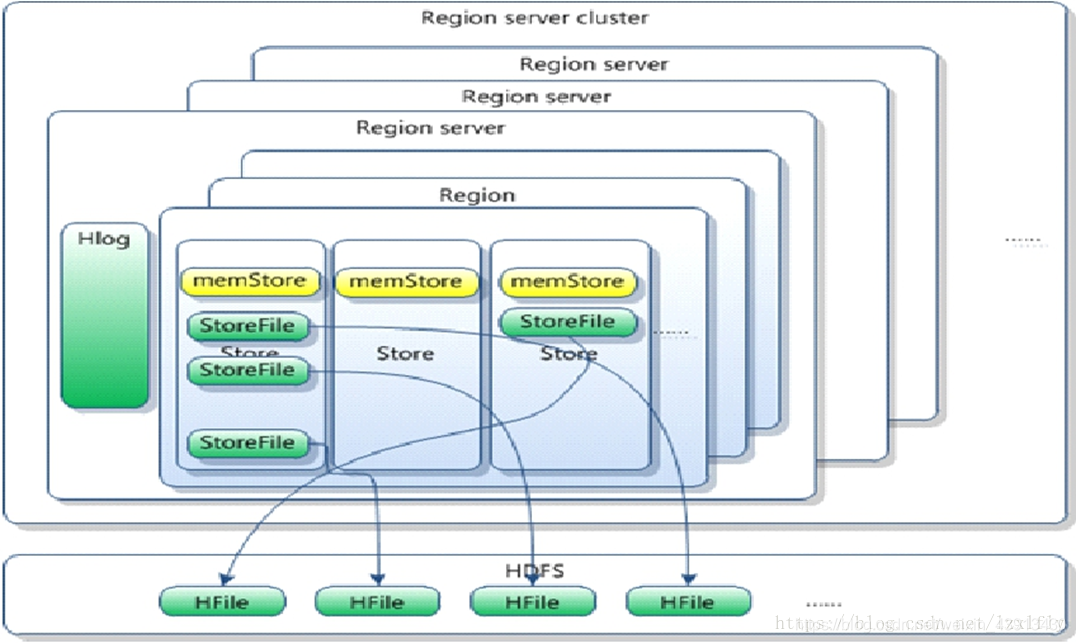
HRegion由一个或者多个Store组成,每个store保存一个columns family。每个Strore又由一个memStore和0至多个StoreFile组成,每个storefile以HFile格式保存在HDFS上,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile,如下图。

-
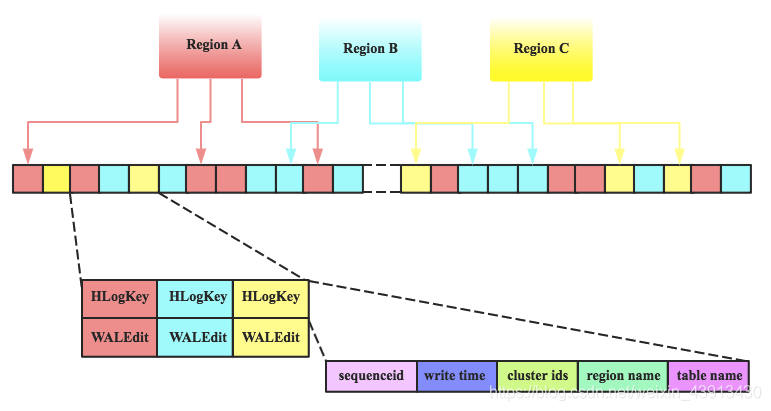
HLog(Write Ahead Log)
在分布式系统环境中,无法避免系统出错或者宕机,因此一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog了。每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的Key、Value
-
- hlog的基本结构
- 逻辑图
- hlog 生成过程

hlog 滚动:regionserver启动一个线程定期(由参数’hbase.regionserver.logroll.period’决定,默认1小时)对hlog进行滚动,重新创建一个新的hlog.,这样,regionserver上就会产生很多小的hlog 文件,hbase这样做的原因是当hbase的数据越来越多时,hlog的大小就会越来越大。当memorystore 刷写到磁盘时,过期的hlog 并没有作用便可删除,一个个小的hlog文件便于删除。
hlog失效:当memorystore flush 到磁盘后,将hlog中最大的seqId与memorystore中最大的seqId进行比较,如果小于memorystore中的seqId,则改hlog失效,便将该hlog移到由wals文件夹移到oldwals文件中去
hlog删除:当hlog失效后,不立即删除是因为region replica可能正在对hlog进行读写,所以regionserver启动一个线程每隔一段时间(由参数’hbase.master.cleaner.interval’,默认1分钟)对检查该hlog是否可以被删除,在oldwals文件夹中的hlog文件都有过期时间,默认(由参数’hbase.master.logcleaner.ttl’决定)为10分钟
- 逻辑图
- 内存布局
- 逻辑图

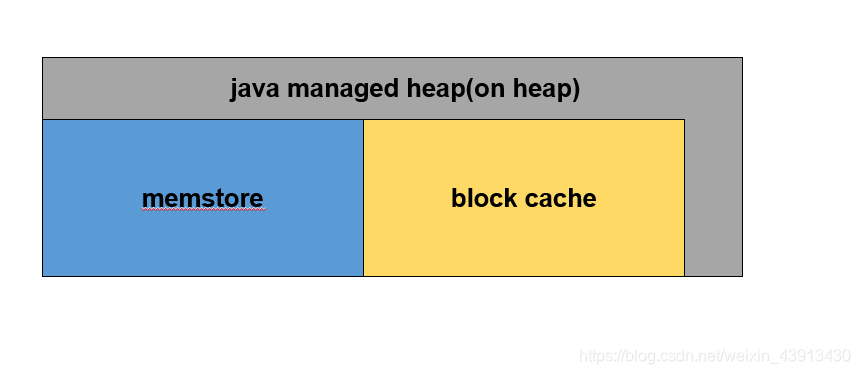
- JVM内存即我们通常俗称的堆内内存,这块内存区域的大小分配在HBase的环境脚本中设置,在堆内内存中主要有三块内存区域,
- 20%分配给hbase regionserver rpc请求队列及一些其他操作
- 80%分配给memstore + blockcache
- java direct memory即堆外内存,
- 其中一部分内存用于HDFS SCR/NIO操作
- 另一部分用于堆外内存bucket cache,其内存大小的分配同样在hbase的环境变量脚本中实现
- 逻辑图
- 流程分析
- 写入流程

- client--->wal---->Memstore
- memstore会根据策略进行数据持久化到本地文件
- 什么时候出发Memstore Flush
- Region 中所有 MemStore 占用的内存超过相关阈值
- 整个 RegionServer 的 MemStore 占用内存总和大于相关阈值
- WAL数量大于相关阈值
- 定期自动刷写
- 数据更新超过一定阈值
- 手动触发刷写
- Region 中所有 MemStore 占用的内存超过相关阈值
- 阈值由
hbase.hregion.memstore.flush.size参数控制,默认为128MB - 大小等于 RegionServer_heapsize* hbase.regionserver.global.memstore.size。
- hbase.hregion.memstore.block.multiplier默认值为4
- 当整个regionServer下所有region占用memstore的大小超过hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier进行刷新
- 阈值由
- 整个 RegionServer 的 MemStore 占用内存总和大于相关阈值
- 整个 RegionServer 的 MemStore 占用内存总和大于 hbase.regionserver.global.memstore.size.lower.limit * hbase.regionserver.global.memstore.size *RegionServer_heapsize 的时候将会触发 MemStore 的刷写。
- 其中 hbase.regionserver.global.memstore.size.lower.limit 的默认值为 0.95。
hbase.regionserver.global.memstore.size的默认值是 0.4
- WAL数量大于相关阈值
- 如果某个 RegionServer 的 WAL 到达一定的数量时进行一次刷写操作。
- 这个阈值(maxLogs)的计算公式如下:如果设置了 hbase.regionserver.maxlogs,那就是这个参数的值;否则是 max(32, hbase_heapsize * hbase.regionserver.global.memstore.size / logRollSize)
- logRollSize=WAL blocksize * 0.95# 默认blocksize=128MB
- 定期自动刷写
- 如果我们很久没有对 HBase 的数据进行更新,这时候就可以依赖定期刷写策略了。
- RegionServer 在启动的时候会启动一个线程 PeriodicMemStoreFlusher
- 每隔 hbase.server.thread.wakefrequency 时间去检查属于这个 RegionServer 的 Region有没有超过一定时间都没有刷写,
- 这个时间是由 hbase.regionserver.optionalcacheflushinterval 参数控制的,默认是 3600000,
- 也就是1小时会进行一次刷写
- 数据更新超过一定阈值
- 如果 HBase 的某个 Region 更新的很频繁,
- 而且既没有达到自动刷写阀值,
- 也没有达到内存的使用限制,
- 但是内存中的更新数量已经足够多,
- 比如超过 hbase.regionserver.flush.per.changes 参数配置,默认为30000000,
- 那么也是会触发刷写的。
- 读取流程
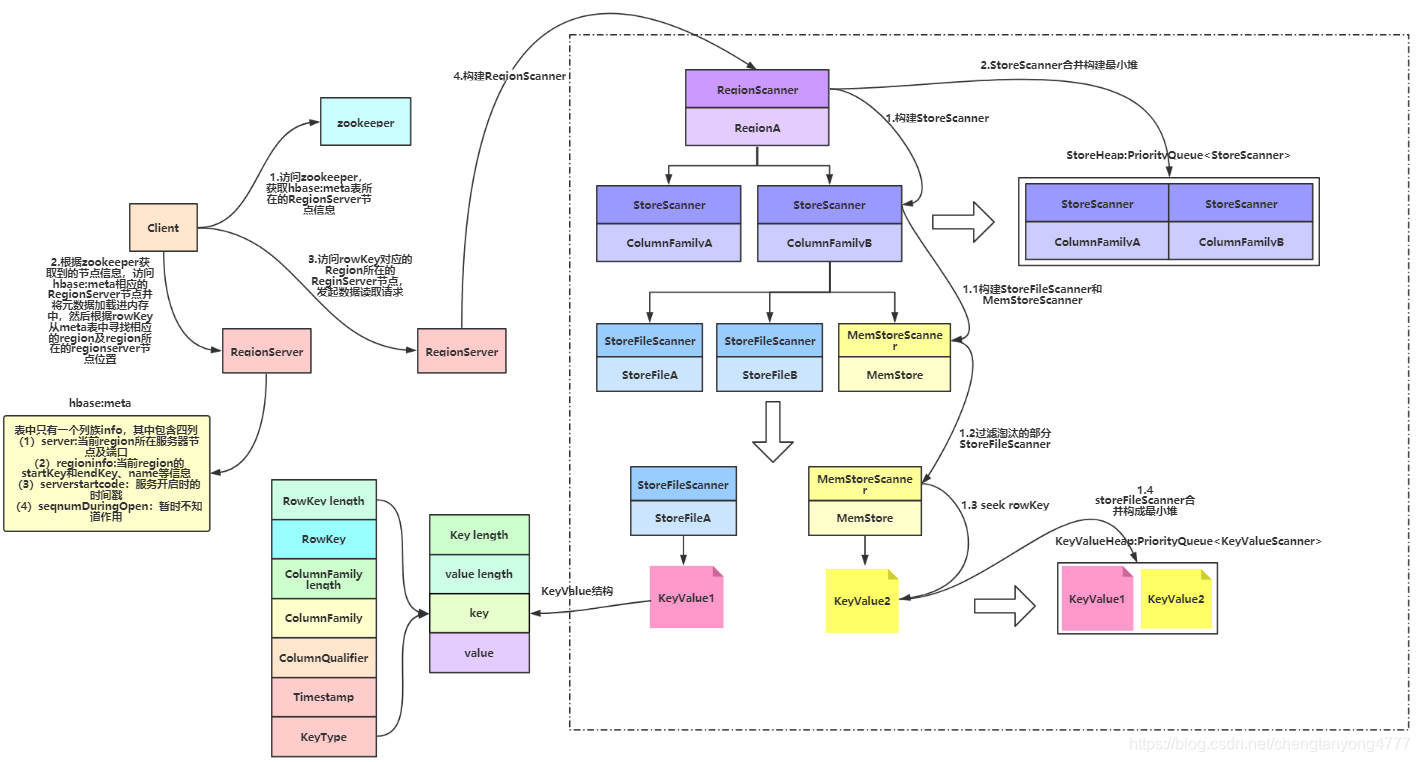
- Client访问zookeeper,获取hbase:meta所在RegionServer的节点信息。
- Client访问hbase:meta所在的RegionServer,获取hbase:meta记录的元数据后先加载到内存中,然后再从内存中根据需要查询的RowKey查询出RowKey所在的Region的相关信息(Region所在RegionServer)
- Client访问RowKey所在Region对应的RegionServer,发起数据读取请求
- RegionServer构建RegionScanner(需要查询的RowKey分布在多少个Region中就需要构建多少个RegionScanner),用于对该Region的数据检索
- RegionScanner构建StoreScanner(Region中有多少个Store就需要构建多少个StoreScanner,Store的数量取决于Table的ColumnFamily的数量),用于对该列族的数据检索
- 多个StoreScanner合并构建最小堆(已排序的完全二叉树)StoreHeap:PriorityQueue<StoreScanner>
- StoreScanner构建一个MemStoreScanner和一个或多个StoreFileScanner(数量取决于StoreFile数量)
- 过滤掉某些能够确定所要查询的RowKey一定不在StoreFile内的对应的StoreFileScanner或MemStoreScanner
- 经过筛选后留下的Scanner开始做读取数据的准备,将对应的StoreFile定位到满足的RowKey的起始位置
- 将所有的StoreFileScanner和MemStoreScanner合并构建最小堆KeyValueHeap:PriorityQueue<KeyValueScanner>,排序的规则按照KeyValue从小到大排序
- 从KeyValueHeap:PriorityQueue<KeyValueScanner>中经过一系列筛选后一行行的得到需要查询的KeyValue。
- 合并流程
- HBase Compaction分为两种:Minor Compaction 与 Major Compaction,通常我们简称为小合并、大合并

- Minor Compaction:指选取一些小的、相邻的HFile将他们合并成一个更大的HFile。默认情况下,minor compaction会删除选取HFile中的TTL过期数据。
- Major Compaction:指将一个Store中所有的HFile合并成一个HFile,这个过程会清理三类没有意义的数据:被删除的数据(打了Delete标记的数据)、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此,生产环境下通常关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
- Compaction 触发条件
- memstore flush:可以说compaction的根源就在于flush,memstore 达到一定阈值或其他条件时就会触发flush刷写到磁盘生成HFile文件,正是因为HFile文件越来越多才需要compact。HBase每次flush之后,都会判断是否要进行compaction,一旦满足minor compaction或major compaction的条件便会触发执行。
- 后台线程周期性检查: 后台线程 CompactionChecker 会定期检查是否需要执行compaction,检查周期为hbase.server.thread.wakefrequency * hbase.server.compactchecker.interval.multiplier,这里主要考虑的是一段时间内没有写入请求仍然需要做compact检查。其中参数 hbase.server.thread.wakefrequency 默认值 10000 即 10s,是HBase服务端线程唤醒时间间隔,用于log roller、memstore flusher等操作周期性检查;参数 hbase.server.compactchecker.interval.multiplier 默认值1000,是compaction操作周期性检查乘数因子。10 * 1000 s 时间上约等于2hrs, 46mins, 40sec。
- 性能优化
- 模型参数优化
- 根据hbase使用用途决定内存分配比例
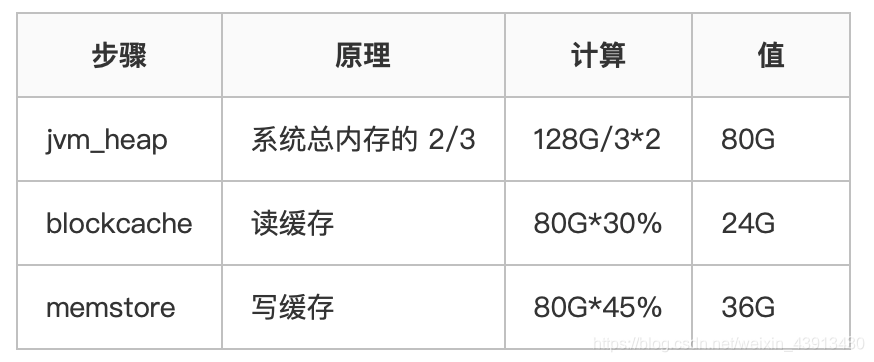
- 写多读少
- hbase-site.xmll
<property> <name>hbase.regionserver.global.memstore.size</name> <value>0.45</value> </property> <property> <name>hfile.block.cache.size</name> <value>0.3</value> </property>
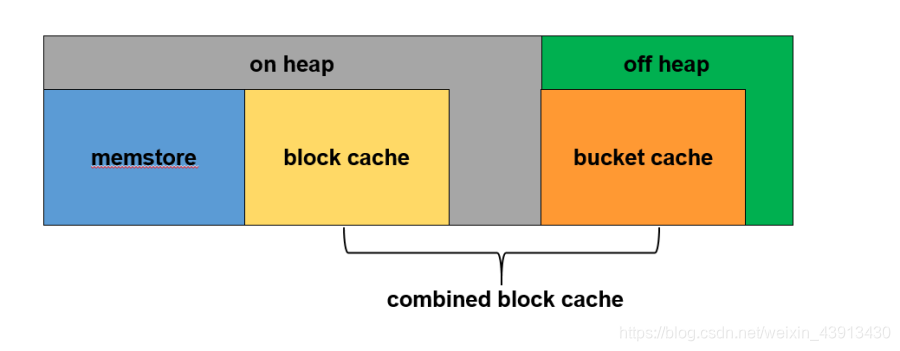
- 读多写少
-
步骤 原理 计算 值 RS总内存系统总内存的 2/3 128G/3*2 80G combinedBlockCache 读缓存设置为整个RS内存的70% 80G*70% 56G blockcache 主要缓存数据块元数据,数据量相对较小。设置为整个读缓存的10% 56G*10% 6G bucketcache 主要缓存用户数据块,数据量相对较大。设置为整个读缓存的90% 56G*90% 50G memstore 写缓存设置为jvm_heap的60% 30G*60% 18G jvm_heap rs总内存-堆外内存 80G-50G 30G - hbase-site.xml
<property> <name>hbase.bucketcache.combinedcache.enabled</name> <value>true</value>#必须设置为true </property> <property> <name>hbase.bucketcache.ioengine</name> <value>offheap</value> #同时作为master的rs要用heap </property> <property> <name>hbase.bucketcache.size</name> <value>50176</value> #单位MB。这个值至少要比bucketcache小1G,作为master的rs用heap,那么这里要填<1的值作为从heap中分配给bucketcache的百分比 </property> <property> <name>hbase.regionserver.global.memstore.size</name> <value>0.60</value> #heap减小了,那么heap中用于memstore的百分比要增大才能保证用于memstore的内存和原来一样 </property> <property> <name>hfile.block.cache.size</nname> <value>0.20</value> #使用了bucketcache作为blockcache的一部分,那么heap中用于blockcache的百分比可以减小 </property> - hbase-env.sh
export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC -Xms30g –Xmx30g -XX:MaxDirectMemorySize=50g
- 其他参数优化
- *hbase.hstore.blockingStoreFiles:默认值7.如果storefile的数量超过了阈值,就会阻塞flush,compact线程进行合并,如果想让数据写入更加平滑或者业务写入量巨大,可以考虑增大该值。
- *hbase.hregion.memstore.flush.size:默认值128MB,指单个region中memstore使用内存超过多大进行flush。如果region大量写入数据超过阈值会执行flush操作。可根据实际数据流量来确定是否需要扩大该值。
- *hbase.hregion.memstore.block.multiplier:默认值4.指mestore的内存大小超过hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier就会阻塞写入操作。如果数据量很大建议扩大该值,也不建议设置很大,如果太大则会增大导致整个RS的memstore内存超过memstore.upperLimit限制的可能性,进而增大阻塞整个RS的写的几率
- *hbase.regionserver.global.memstore.upperLimit: 默认值0.4。regionserver所有memstore占用内存在总内存中的upper比例,当达到该值,则会从整个regionserver中找出最需要flush的region进行flush,直到总内存比例降到该数以下,采用默认值即可。
- *hbase.regionserver.global.memstore.lowerLimit:默认值0.35,采用默认值即可。
- *hfile.block.cache.size:默认值0.25,regionserver的block cache的内存大小限制,在偏向读的业务中,可以适当调大该值,需要注意的是hbase.regionserver.global.memstore.upperLimit的值和hfile.block.cache.size的值之和必须小于0.8。
- *hbase.regionserver.handler.count:默认值10,每个regionserver启动的RPC Listener实例个数,hbase.master.handler.count参数意思跟它基本一样。handler个数并非越多越好,如果设置了过多的handler可能得到一个适得其反的结果。如果是read-only的场景,handler的个数接近与cpu个数比较好。在调整该参数时候,建议设置为cpu个数的倍数,从两倍cpu个数开始调整。
- *hbase.hregion.max.filesize:默认值10G。控制region split的阀值,需要注意:如果有多个列簇,不管哪个列簇达到了该值,就会触发split,并且是region级别的,哪怕其他的列簇的hfile值还很小。目前来说,推荐的最大region size为10-20G,当然也可以设置的更大,比如50G(如果设置了压缩,该值指的是压缩之后的大小)
- hbase.regionserver.region.split.policy = SteppingSplitPolicy split算法
- *zookeeper.session.timeout:默认值90000。在设置该参数值需要注意,要关注zookeeper server的Minimum session timeout和Maximum session timeout,zookeeper默认Minimum session timeout 为 2 * tick time,Maximum session timeout 为 20*tick time,tick time为心跳间隔(默认2秒)也就是说你在hbase侧设置的最大会话超时时间在是以client的身份设置的,所以最终还是以zookeeper server为主
- *hbase.regionserver.thread.compaction.small:默认值1。用于minor compact的线程数,当compact quene比较高的时候,建议增加该值。可以设置为5。
- *hbase.regionserver.thread.compaction.large:默认值1。regionserver做Major Compaction时线程池里线程数目,可以设置为8。
- *hbase.hregion.majorcompaction:默认值1。 major compact时间周期,默认1天,但是触发时间点往往都不是最佳的。所以一般线上环境都禁用major compact(设置为0),然后在合适的时间手动执行
- *hbase.hstore.compaction.min:默认值3,如果任何一个store里的storefile总数超过该值,会触发默认的合并操作,可以设置5~8,在手动的定期major compact中进行storefile文件的合并,减少合并的次数,不过这会延长合并的时间,以前的对应参数为hbase.hstore.compactionThreshold。
- hbase.hstore.compaction.max:默认值10,一次最多合并多少个storefile,避免OOM
- hbase.regionserver.hlog.blocksize :默认值128MB。默认即可,但是需要了解的是WAL一般在达到该值的95%的时候就会滚动
- *hbase.regionserver.maxlogs :默认值32。配置WAL Files的数量,WAL files过少的话,会触发更多的flush,太多的话,hbase recovery时间会比较长。可以参考 max(32, hbase_heapsize * hbase.regionserver.global.memstore.size / logRollSize)
- *hbase.wal.provider:可以设置成mutiwal。默认情况下,一个regionserver只有一个wal文件,所有region的walEntry都写到这个wal文件中,在HBase-5699之后,一个regionserver可以配置多个wal文件,这样可以提高写WAL时的吞吐,进而降低数据写延时
- hfile.block.index.cacheonwrite:在index写入的时候允许put无根(non-root)的多级索引块到block cache里,默认是false,设置为true,或许读性能更好,但是是否有副作用还需调查
- hbase.rs.cacheblocksonwrite:默认false,
- dfs.socket.timeout:默认值60000(60s),建议根据实际regionserver的日志监控发现了异常进行合理的设置,比如我们设为900000,这个参数的修改需要同时更改hdfs-site.xml
- dfs.datanode.socket.write.timeout:默认480000(480s),有时regionserver做合并时,可能会出现datanode写超时的情,这个参数的修改需要同时更改hdfs-site.xml
- HBase表属性调整
- *Compression
1.可以选择的有NONE, GZIP, SNAPPY, 等等 2.指定压缩方式:create ’test', {NAME => ’cf', COMPRESSION => 'SNAPPY’}} 3.节省磁盘空间 4.压缩针对的是整个块,对get或scan不太友好 5.缓存块的时候不会使用压缩,除非指定hbase.block.data.cachecompressed = true, 这样可以缓存更多的块,但是读取数据时候,需要进行解压缩 - HFile Block Size
1. 不等同于HDFS block size 2. 指定BLOCKSIZE属性 create ‘test′,{NAME => ‘cf′, BLOCKSIZE => ’4096'} 3.默认64KB,对Scan和Get等同的场景比较友好 4.增加该值有利于scan 5.减小该值有利于get
- *Compression
- *RegionServer节点硬件配置
- 硬盘和内存比例
Disk/Heap ratio=RegionSize / MemstoreSize *ReplicationFactor *HeapFractionForMemstores * 2 - 那么在默认情况下,该比例等于:10gb/128mb * 3 * 0.4 * 2 = 192。在磁盘上每存储192字节的数据,对应堆的大小应为1字节,那么如果设置32G的堆,磁盘上也就是可以存储大概6TB的数据(32gb * 192 = 6tb)
- 理想状况下regionserver的硬件配置:
1.每个节点<=6TB的磁盘空间 2.regionserver heap 约等于磁盘大小/200(上面的比例公式) 3.由于hbase属于cpu密集型,所以较多的cpu core数量更适合 4.网卡带宽和磁盘吞吐量的匹配值: (背景:磁盘使用传统HDD,I/O 100M/s) CASE1:1GE的网卡,配备24块磁盘,像这样的搭配是不太理想的,因为1GE的网卡流量等于125M/s,而24块磁盘的吞吐量大概2.4GB/s,网卡成为瓶颈 CASE2:10GE的网卡,配备24块磁盘,比较理想 CASE3:1GE的网卡,配置4-6块磁盘,也是比较理想的
- 硬盘和内存比例
- Hbase Client端优化
1.hbase.client.write.buffer:默认为2M,写缓存大小,推荐设置为5M,单位是字节,当然越大占用的内存越多,此外测试过设为10M下的入库性能,反而没有5M好hbase.client.write.buffer:默认为2M,写缓存大小,推荐设置为5M,单位是字节,当然越大占用的内存越多,此外测试过设为10M下的入库性能,反而没有5M好2.hbase.client.pause:默认是1000(1s),如果你希望低延时的读或者写,建议设为200,这个值通常用于失败重试,region寻找等hbase.client.pause:默认是1000(1s),如果你希望低延时的读或者写,建议设为200,这个值通常用于失败重试,region寻找等3.hbase.client.retries.number:默认值是10,客户端最多重试次数,可以设为11,结合上面的参数,共重试时间71shbase.client.retries.number:默认值是10,客户端最多重试次数,可以设为11,结合上面的参数,共重试时间71s4.hbase.ipc.client.tcpnodelay:默认是false,建议设为true,关闭消息缓冲hbase.ipc.client.tcpnodelay:默认是false,建议设为true,关闭消息缓冲5.hbase.client.scanner.caching:scan缓存,默认为1,避免占用过多的client和rs的内存,一般1000以内合理,如果一条数据太大,则应该设置一个较小的值,通常是设置业务需求的一次查询的数据条数hbase.client.scanner.caching:scan缓存,默认为1,避免占用过多的client和rs的内存,一般1000以内合理,如果一条数据太大,则应该设置一个较小的值,通常是设置业务需求的一次查询的数据条数 如果是扫描数据对下次查询没有帮助,则可以设置scan的setCacheBlocks为false,避免使用缓存;6.table用完需关闭,关闭scannertable用完需关闭,关闭scanner7.限定扫描范围:指定列簇或者指定要查询的列,指定startRow和endRow限定扫描范围:指定列簇或者指定要查询的列,指定startRow和endRow8.使用Filter可大量减少网络消耗使用Filter可大量减少网络消耗9.通过java多线程入库和查询,并控制超时时间。后面会共享下我的hbase单机多线程入库的代码通过java多线程入库和查询,并控制超时时间。后面会共享下我的hbase单机多线程入库的代码10.建表注意事项:建表注意事项合理的设计rowkey 进行预分区 开启bloomfilter - zookeeper调优
1.zookeeper.session.timeout:默认值3分钟,不可配置太短,避免session超时,hbase停止服务zookeeper.session.timeout:默认值3分钟,不可配置太短,避免session超时,hbase停止服务2.zookeeper数量:建议5个或者7个节点。给每个zookeeper 4G左右的内存,最好有独立的磁盘。zookeeper数量:建议5个或者7个节点。给每个zookeeper 4G左右的内存,最好有独立的磁盘。3.hbase.zookeeper.property.maxClientCnxns:zk的最大连接数,默认为300,无需调整。hbase.zookeeper.property.maxClientCnxns:zk的最大连接数,默认为300,无需调整。4.设置操作系统的swappiness为0,则在物理内存不够的情况下才会使用交换分区,避免GC回收时会花费更多的时间,当超过zk的session超时时间则会出现regionserver宕机的误报设置操作系统的swappiness为0,则在物理内存不够的情况下才会使用交换分区,避免GC回收时会花费更多的时间,当超过zk的session超时时间则会出现regionserver宕机的误报 - hdfs调优
1.dfs.name.dir:namenode的数据存放地址,可以配置多个,位于不同的磁盘并配置一个nfs远程文件系统,这样namenode的数据可以有多个备份dfs.name.dir:namenode的数据存放地址,可以配置多个,位于不同的磁盘并配置一个nfs远程文件系统,这样namenode的数据可以有多个备份2.dfs.namenode.handler.count:namenode节点RPC的处理线程数,默认为10,可以设置为60dfs.namenode.handler.count:namenode节点RPC的处理线程数,默认为10,可以设置为603.dfs.datanode.handler.count:datanode节点RPC的处理线程数,默认为3,可以设置为30dfs.datanode.handler.count:datanode节点RPC的处理线程数,默认为3,可以设置为304.dfs.datanode.max.xcievers:datanode同时处理文件的上限,默认为256,可以设置为8192dfs.datanode.max.xcievers:datanode同时处理文件的上限,默认为256,可以设置为8192 - regionserver的region数量不要过1000,过多的region会导致产生很多memstore,可能会导致内存溢出,也会增加major compact的耗时















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











