







 本文详细介绍了8086汇编语言的基础知识,包括处理器结构、寄存器、数据储存方式、寻址方式和80x86指令系统。讲解了数据传送、地址传送、类型转换、算术、逻辑、串处理等指令,并通过实例演示了如何使用这些指令。此外,还探讨了子程序、伪指令以及上机实验中遇到的问题和解决方法,为读者提供了全面的8086汇编学习指南。
本文详细介绍了8086汇编语言的基础知识,包括处理器结构、寄存器、数据储存方式、寻址方式和80x86指令系统。讲解了数据传送、地址传送、类型转换、算术、逻辑、串处理等指令,并通过实例演示了如何使用这些指令。此外,还探讨了子程序、伪指令以及上机实验中遇到的问题和解决方法,为读者提供了全面的8086汇编学习指南。
8086处理器基础知识
汇编语言是大小写不敏感的低级语言,意思就是mov和MOV是汇编语言来说是一样的,当然大小写混用也是可以的,如Mov
在8086汇编语言里,数字默认是十进制的,如果是其他进制数字则需要标识,我们用十进制和十六进制较多,记住这两个即可,特别注意如果十六进制数首个字符是字母则需要在前面多添一个0(因为不加0编译器会将它看作一个变量名,而不是一个十六进制数字),如
mov ax,50;50是十进制的
mov ax,50h;50h是十六进制的
mov ax,abc2h;报错
mov ax,0abc2h;需要在a前添0
80x86微处理器有8086、8088、80286等型号,我们要学习的就是8086微处理器的汇编指令系统,主要记住下表内容
| 型号 | 字长(位) | 数据总线宽度(位) | 地址总线宽度(位) | 寻址空间 |
|---|---|---|---|---|
| 8086 | 16 | 16 | 20 | 1M |
- 字长:计算机一次性能处理二进制数的位数叫字长
- 寻址空间:可理解成地址范围1M=220,计算机内部存储空间都会编上号,就像每个户人家都有一个门牌号一样,总共有1M户人家,依次被编号0~ 220-1
由于地址总线的宽度是20位,而数据总线宽度只有16位,为了能够表示20位的地址,我们采用如下方式
两个十六位数字的经过一定的计算变成一个20位的地址
2000h∗16+1000h=21000h2000h*16+1000h=21000h2000h∗16+1000h=21000h
(这里的h代表十六进制,每一位代表4个二进制数)
2000h乘以16,相当于十六进制数左移一位
2000h和1000h这里被称为虚地址(也叫逻辑地址)
而计算出的21000h称为实地址(也叫物理地址)
此时这里的2000h就称为段地址,后面的1000h就称为偏移地址。那么存放段地址的寄存器就是段寄存器
8086寄存器
段寄存器和其他寄存器也不能随意搭配使用,下表是8086的段寄存器和存放偏移地址的寄存器之间的默认组合
| 段 | 偏移 |
|---|---|
| CS(code segment) | IP (index pointer) |
| SS (stack segment) | SP(stack pointer)、IP |
| DS(data segment) | BX(base)、DI(destination index)、SI(source index)或一个16位数字 |
| ES (extra segment) | DI(用于串指令) |
通用寄存器和专用寄存器以及它们的常用用途
| 通用寄存器 | 用途 |
|---|---|
| AX(accumulate) | 主要用于算术运算,在乘除指令存放操作数,I/O指令与外部设备传送信息 |
| BX (base) | 在计算实地址时,用作基址寄存器 |
| CX(count) | 在移位指令、循环指令(loop)和串处理指令用作隐含的计数器 |
| DX(data) | 在双字长(即32位)运算时会把DX、AX组合用来存放双字长数,DX存放高位字,AX存放低位字,对某些I/O操作,DX可以存放I/O的端口地址 |
| 专用寄存器 | 用途 |
|---|---|
| SP(stack pointer) | 它与堆栈段寄存器(SS)一起来确定堆栈段中栈顶的位置 |
| IP (instruction pointer) | 指令指针寄存器,用来存放代码段中指令的偏移地址 |
| FLAGS(标志寄存器)又称程序状态寄存器(PSW,program status word) | 顾名思义,用来存放各种状态的寄存器 |
所有的通用寄存器都可以自由使用
但每个寄存器又有其单独的用途
AX,BX,CX,DX 可以拆分为高8位和低8位使用, 分别是AH&AL, BH&BL…
而SP, BP, SI, DI四个只能以16位的方式使用
SP, BP, SI, DI四个寄存器更经常的用途是在储存器寻址时, 提供偏移地址
FLAGS, 此寄存器是按位使用的, 各个位的功能如下:

| 状态标志位 | 功能 |
|---|---|
| OF(overflow flag) | 作为有符号数溢出标志,如果运算结果的次高位产生一个进位或借位,则OF置1,否则OF为0。 |
| CF(carry) | 作为无符号数溢出标志,如果运算结果的最高位产生一个进位或借位,则CF置1,否则CF为0。 |
| SF(sign) | 运算结果为负数SF置1,否则SF为0 |
| ZF(zero) | 运算结果为0数ZF置1,否则ZF为0 |
| AF(auxiliary carry flag) | 辅助进位位,反映半个字节运算结果产生进位或借位的情况,如1000h+1234h,即记录00h+34h进位或借位的情况,有进位置1,否则为0 |
| PF(parity flag) | 奇偶位,如果运算结果“1”的个数为偶数时,则PF置1, 否则PF为0 |
| TF(trap flag) | 单步标志位,用于程序跟踪调试。当TF=1,CPU进入单步方式,TF=0,CPU正常工作。 |
| IF(interrupt flag) | 中断允许位,当IF=1时,CPU为开中断。 当IF=0时,CPU为关中断。 |
| DF(direction flag) | 方向位,决定串操作指令执行时的指针寄存器的调整方向,DF=1,SI和DI减小,使得串处理从高地址向低地址方向处理,DF=0,则相反,常用于字符串正序和倒序输出 |
tips:
CF是最高位产生了进位或借位时的标志,是无符号数溢出的标志位
OF是次高位产生了进位或借位时的标志位,是有符号数溢出的标志位
同符号数相加,运算结果符号变了,说明发生溢出
不同符号数相加,一定不会发生溢出
数据储存方式
80X86的CPU绝大多数是用小端模式进行存储,而ARM绝大多数都是大端存储
| 模式 | 特点 |
|---|---|
| 大端模式 | 数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中 |
| 小端模式 | 是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中 |
总结:大端就是高放低,小端就是高放高,8086是小端。
寻址方式
一条指令一般都是由一个操作码和多个操作数构成的
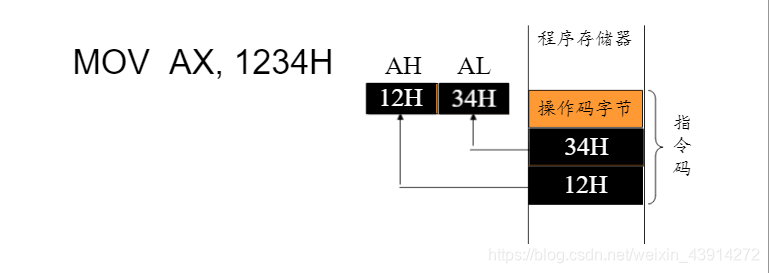
mov ax,5
;mov为操作码
;ax和5为操作数
;二地址指令
寻址方式是用来确定操作数地址, 从而找到操作数的
通常操作数字段为1个或2个, 也有少数是3个的,有几个操作数就是几地址指令,如一地址指令, 二地址指令, 三地址指令
下表是一些寻址方式及其举例(名字可以不用死记,记住它们的例子和特征就好)
| 寻址方式 | 特点 | 举例 |
|---|---|---|
| 立即寻址方式 | 操作数是一个数字 | mov al,5 |
| 寄存器寻址方式 | 操作数放在一个寄存器里 | mov ax,bx |
| 直接寻址方式 | 只含位移量 | mov ax,[2000h] |
| 寄存器间接寻址方式 | 只含基址或只含变址 | mov ax,[bx] |
| 寄存器相对寻址方式 | 基址或变址+位移量 | mov ax,count[si] |
| 基址变址寻址方式 | 基址+变址 | mov ax,[bx][di] |
| 相对基址变址寻址方式 | 基址+变址+位移量 | mov count[bx][si] |
每个指令通常都有其对应的寻址方式, 操作数要么就是在指令中显式给出,要么就是在寄存器中,要么就是在内存中。
直接显示给出就是立即寻址方式,那个数字就被称为立即数
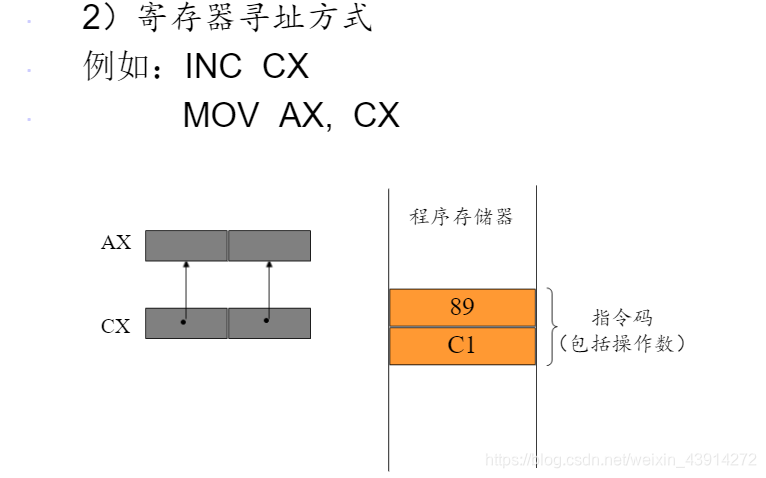
在寄存器中,就是寄存器寻址方式
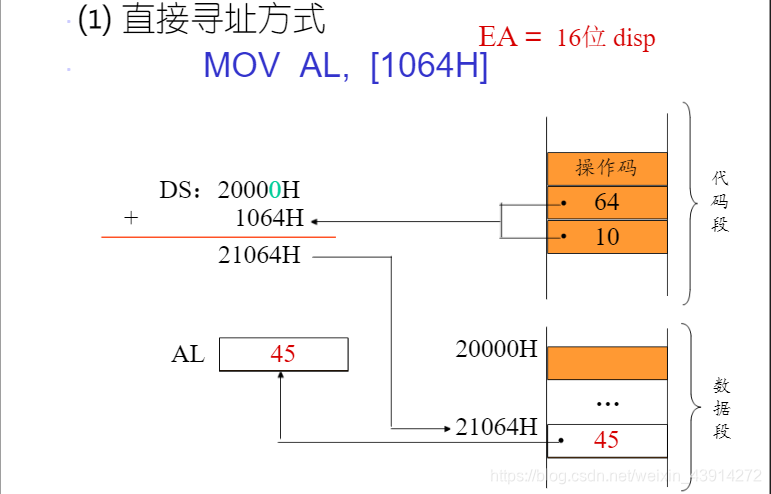
在内存中
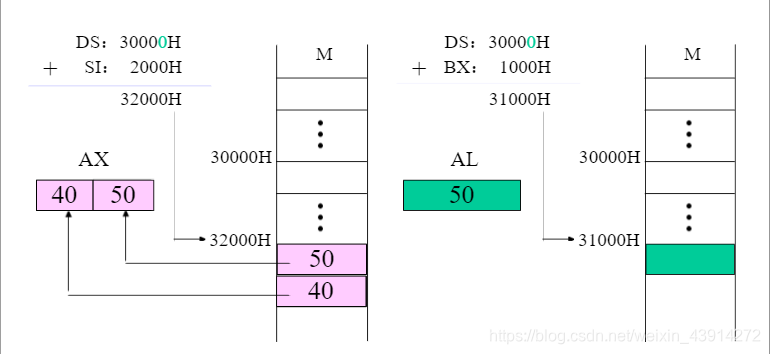
寄存器间接寻址
eg:mov ax,[si]
如果在内存中,那就要根据以下公式来辨别其寻址方式了
有效地址的计算公式:
EA(effective address) = 基址 + (变址 * 比例因子) + 位移量
操作数的偏移地址称为有效地址EA, 有效地址可以用以下四种成分组成:
| 成分 | 功能 |
|---|---|
| 位移量(displacement) | 位移量是存放在指令中的一个8位, 16位或32位的数,但他不是一个立即数,而是一个地址 |
| 基址(base) | 基址是存放在基址寄存器BX或BP中的内容,其指有效地址的基址部分。通常要来指向数据段中的数组和字符串的首地址 |
| 变址(index, 即下标) | 变址是存放在变址寄存器SI或DI中的内容,它通常用来访问数组中的某个元素和字符串中的某个字符。 |
| 比例因子(scale factor, 80386机型后才有) | 比例因子的值通常就是1,2,4,8, 比例因子用于在寻址过程中将变址寄存器的内容乘以比例因子来取得变址值, 所以在访问元素长度为2,4,8字节的数组特别有用 |
至于为何要上4种,成分 而不仅仅基址+位移量两种, 是因为引入变址和比例因子使得有效地址的计算更加灵活
其中除比例因子以外, 其他3个都可以是负数, 以保证指针移动的灵活性
每种成分可有可无,但比例因子和变址必须同时存在,故根据这个公式可以有23种寻址方式,但含比例因子的寻址方式只80386及其以后的机型有,我们主要掌握8086的寻址方式即可,整理如下表
| 寻址方式 | 特点 | 举例 |
|---|---|---|
| 直接寻址方式 | 只含位移量 | mov ax,[2000h] |
| 寄存器间接寻址方式 | 只含基址或只含变址 | mov ax,[bx] |
| 寄存器相对寻址方式 | 基址或变址+位移量 | mov ax,count[si] |
| 基址变址寻址方式 | 基址+变址 | mov ax,[bx][di] |
| 相对基址变址寻址方式 | 基址+变址+位移量 | mov count[bx][si] |
寻址方式只确定了操作数的偏移地址,前面也说过
操作数的实地址=段地址*16+偏移地址
段寄存器和其他寄存器也不能随意搭配使用,下表是8086的段寄存器和存放偏移地址的寄存器之间的默认组合
| 段 | 偏移 |
|---|---|
| CS(code segment) | IP (index pointer) |
| SS (stack segment) | SP(stack pointer)、IP |
| DS(data segment) | BX(base)、DI(destination index)、SI(source index)或一个16位数字 |
| ES (extra segment) | DI(用于串指令) |
我们也可以强制指定其他段寄存器使用, 称为段跨越前缀, 如:
mov ax,[0000]
;程序默认使用的是ds:0000,那它实地址为ds*16+0000
而使用了跨越段前缀就使用你指定的段寄存器
mov ax,es:[0000]
;程序就会使用es:0000,那它实地址为es*16+0000
凡事都可能有例外,有三种情况不允许使用段跨越前缀:
- 串处理指令的目的串必须使用ES段
- PUSH指令的目的和POP指令的源必须使用SS段
- 指令必须存放在CS段中
80x86指令系统
主要指令可以分为以下6种:
数据传送指令
串处理指令
算数指令
控制转移指令
逻辑指令
处理机控制指令
数据传送指令
数据传送指令用于把数据, 地址或立即数传送到寄存器或储存单元中, 即相当于实现赋值功能
通用数据传送指令
| 指令 | 功能 | 格式举例 |
|---|---|---|
| MOV (move) | 传送 | mov ax,5 |
| PUSH(push onto the stack) | 进栈 | push src |
| POP(pop from the stack) | 出栈 | pop dst |
| XCHG(exchange) | 交换 | xchg oper1,oper2 |
MOV:
正确和错误格式举例
;--正确--
mov ax,5;寄存器赋值
mov num,5;符号地址赋值(符号地址相当于高级语言中的变量名)
mov [bx],1000h;[]内bx的值相当于地址,将1000h赋值给存储单元的[bx]中
mov ax,2000h
mov ss,ax;需要借助一个通用寄存器来给段寄存器赋初值
;--错误--
mov num1,num2;此时num1和num2都是符号地址(相当于高级语言中的变量名),都是存储器,mov指令不允许在存储单元之间传送数据
mov ss,2000h;不可直接给段寄存器赋值
PUSH & POP
PUSH支持所有的寻址方式
(寄存器reg, 储存器mem, 立即数data, 段寄存器segreg)
POP支持除立即数以外的任何寻址方式
二者的执行效果:
相当于对堆栈指针SP移位, 16位操作±2字节, 32位操作±4字节, 而后将SRC的数据进栈弹出SRC或将栈顶元素存入DST
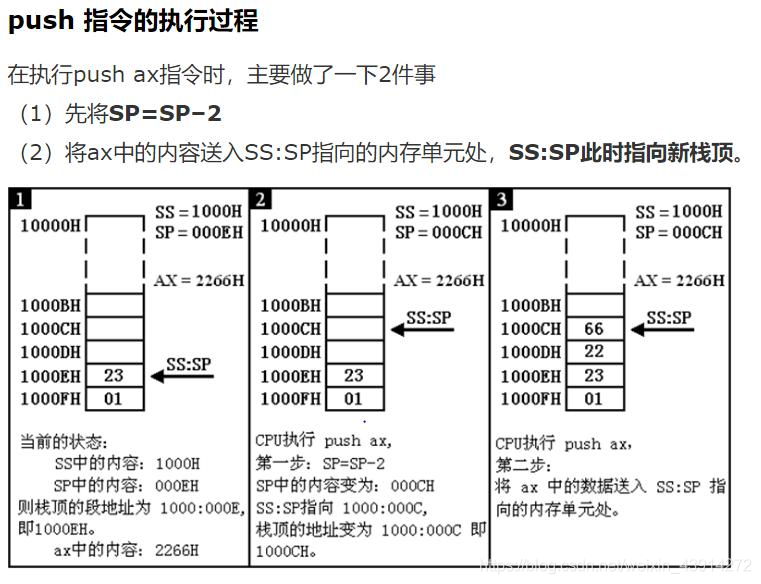
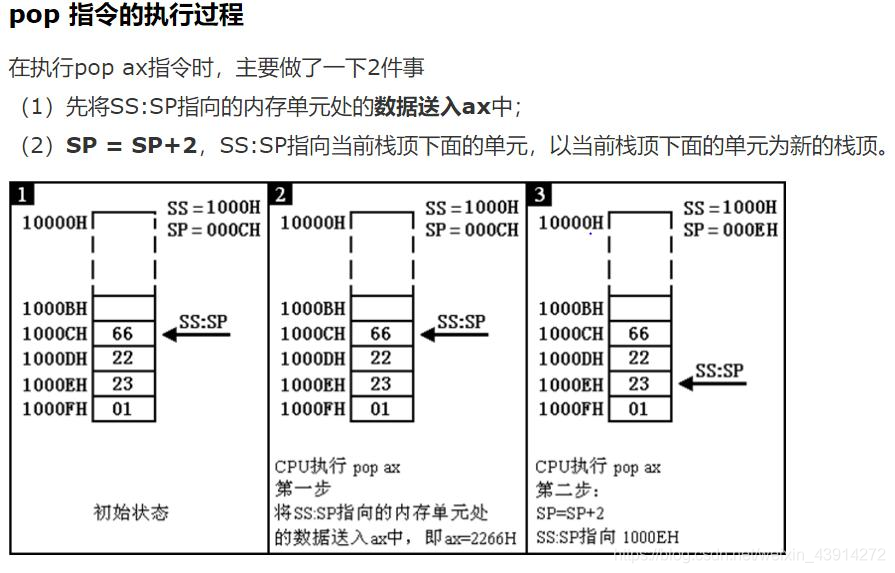
注意:执行PUSH AX后, 栈顶指针SP-2, 而POP后, 栈顶指针SP+2
;---错误---
pop 123h;pop不支持立即数寻址方式
;---正确---
push 123h;PUSH支持所有的寻址方式
push ax
XCHG
此指令可以在寄存器之间或寄存器与储存器之间交换信息
(高级语言中需要使用3条语句)
格式:
XCHG OPR1 OPR2
使用要点:
两个操作数必须有一个在寄存器中
不允许使用段寄存器
IN输入指令 & OUT输出指令
IN & OUT用于所有的I/O端口与CPU之间的通信
XLAT换码指令
通常用于编码的快速转换
首先在使用XLAT指令前, 通常已经在Data Segment数据段建立的一个转换表(如数码管的段显示表, 其实就是一个数组), 将此表的首地址加载给BX, 并在AX中装入偏移量, 用XLAT后, CPU会将DS+BX+AX指向的值(注意是指向的值)装入AX中
XLAT OPR ;OPR为操作数, 通常是符号化的首地址, 这种写法提高程序的可读性
XLAT ;直接就这样, 简化版
;执行效果:
;16位: 将BX+AL的值赋给AL, 此时必须零扩展到16位
;32位: 将EBX+AL的值赋给AL, 此时必须零扩展到32位
如:
;执行前: (BX)=0040H, (AL)=0FH, (DS)=F000H,
XLAT
;执行后, AX的值为F000H+0040H+0FH地址处储存的值
地址传送指令
注意这里和之前的MOV指令不同的是, MOV传送的是源操作数中的值, 而地址传送指令传送的是源操作数的地址
LEA(load effective address)有效地址送寄存器指令
格式:
LEA REG, SRC
;将SRC的有效地址存入REG寄存器中
REG可以是16位或32位寄存器, 但是不可以使用段寄存器
SRC可以是除立即寻址方式和寄存器寻址方式以外的任何一种储存器寻址方式(即前头的8 种)
如:
;执行前: (BX)=0400H, (SI)=003CH
LEA BX, [BX+SI+0F62H]
;执行后: (BX)=0400+003C+0F62=139EH, 这里得到的是有效地址, 而不是地址指向的值
类型转换指令
此类型指令均不影响标志位
CBW ;convert byte to word 字节转换为字, 将AL符号扩展到AX
;如果AL的最高有效位为0, 则AH=0, 否则AH=0FFH
CWD/CWDE ;convert word th double word 字转换为字节, 将AX符号扩展到DX,
;形成DX:AX双字, 如果AL的最高有效位为0, 则DX=0, 否则DX=0FFFFH
CDQ ;convert double to quad 双字转换为4字, 将EAX符号扩展到EDX,
;形成EDX:EAX中的4字
BSWAP ;byte swap 字节交换
;使指令指定的32位寄存器的字节次序变反, 即1,4互换, 2,3互换
算数指令
此类指令与FLAGS标志位关联紧密
加法指令
| 指令 | 功能 | 格式举例 |
|---|---|---|
| ADD DST, SRC | 普通加法指令 | add ax,bx |
| ADC DST, SRC (add with carry) | 带进位加法,计算双精度数 | ADC DX, BX |
| INC | 自增加1, 相当于++ | inc cx |
ADD:
普通加法指令, 对CF进位标志有影响
指令对标志位的影响:
CF=1 最高有效位向高位有进位
CF=0 最高有效位向高位无进位
OF=1 两个同符号数相加(正数+正数 或 负数+负数),结果符号与其
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









