







原文:https://zhuanlan.zhihu.com/p/28483168335
多模态大模型在自动驾驶领域的落地是一个必然的趋势,它的泛化性是其它较小模型,即使是e2e模型(uniAD等)都比不了的。关于大模型,以前看过llama2的源码,也了解过大模型在自动驾驶领域的一些经典模型的基本原理,但都停留在表面。地平线去年底发了一个Senna的模型,初步看了下,感觉设计得挺好,因此把它当成深入研究多模型自动驾驶大模型的一个入口。原理层面一些其它的文章写得已经比较好了,例如:
但没有找到一些实际部署环境和训练的指导性文章,因此,我把官方github代码中的训练流程初步走了一下,有一些心得发这里,希望对大家有一些帮助。
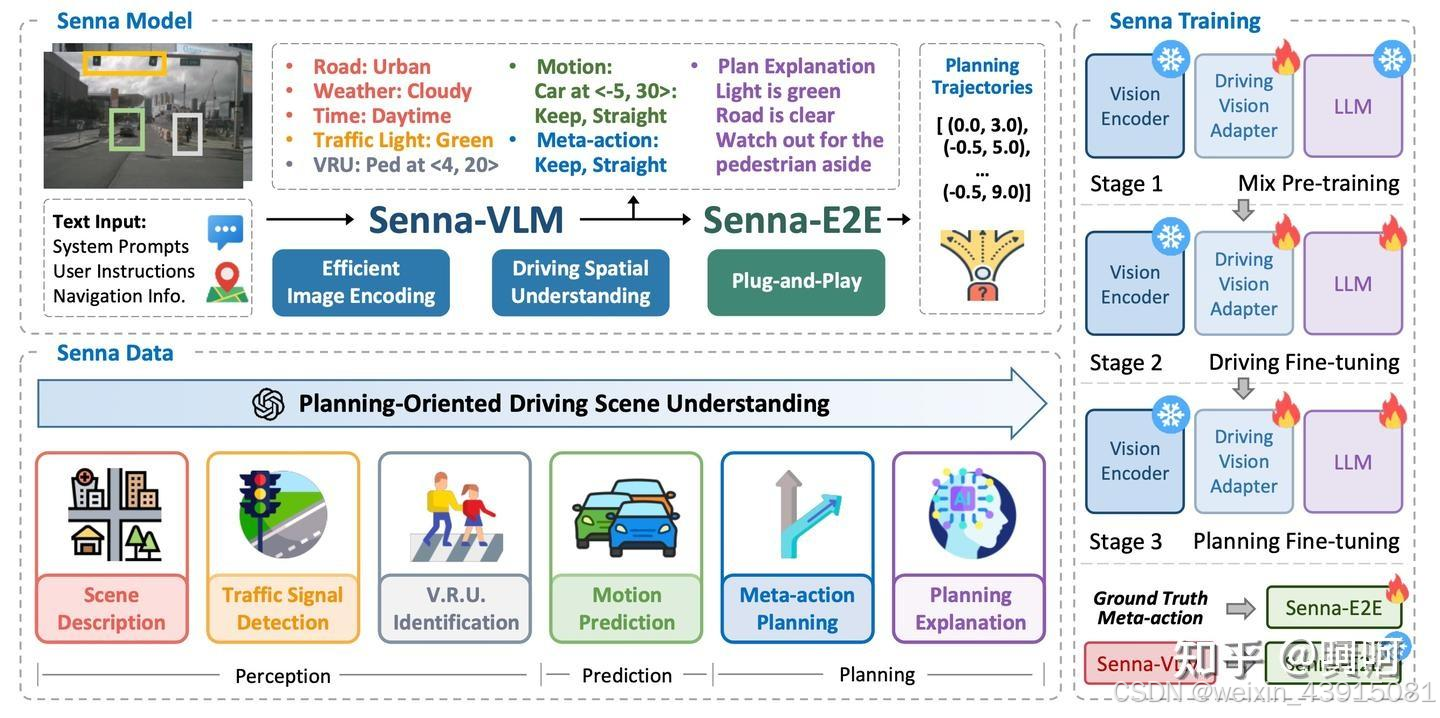
论文中有一些模型名称,例如 Senna , Llava, vicuna, llama等。刚开始也是搞不太清楚,在跑的过程中,也逐渐把它理清楚了。
- llama在最低层级,它是meta开源的比较有名的大语言模型
- vicuna是在llava的基础上,用比较少的数据(70K)在8卡A100环境下,一天内就可以微调出来,效果也比较更好。
- LLava是在
vicuna基础之上,叠加了图像模态的输入,也是用了500K+的数据训练出来,用比较低的成本(硬件+时间),分为2个步骤进行训练(下面这篇文章写得比较好了,可以参考):- 阶段一:特征对齐预训练。由于从CLIP提取的特征与word embedding不在同一个语义表达空间,因此,需要通过预训练,将image
token embedding对齐到text word embedding的语义表达空间。这个阶段冻结Vision
Encoder和LLM模型的权重参数,只训练插值层Projection W的权重 - 阶段二:端到端训练。这个阶段,依然冻结Vision Encoder的权重,训练过程中同时更新插值层Projection
W和LLM语言模型的权重
- 阶段一:特征对齐预训练。由于从CLIP提取的特征与word embedding不在同一个语义表达空间,因此,需要通过预训练,将image
【LLM多模态】LLava模型架构和训练过程 | CLIP模型
- Senna,是本文的主角,它也是基于vicuna进行了跟llava基本一样的微调方法,代码应该也是基于llava进行开发的(我猜的,等研究完代码再确认)。也就是Senna约等于LLava,模型结构都差不多,训练过程也差不多,只是senna是用在自动驾驶领域,llava是图文通用领域,所以它们用的数据是不一样。所以在看代码的时候,遇到比较长的类名,例如SennaLlavaLlamaForCausalLM(Senna版的LLava,继承自LLama),大家了解了它们之间的继承关系,就比较容易理解了。
训练过程
第一步:混合预训练
(上图的右上角stage1),用单图像数据训练驾驶视觉适配器,同时保持 Senna-VLM 中其他模块的参数不变。这样可以将图像特征映射到 LLM 特征空间。
sh train_tools/pretrain_senna_llava.sh
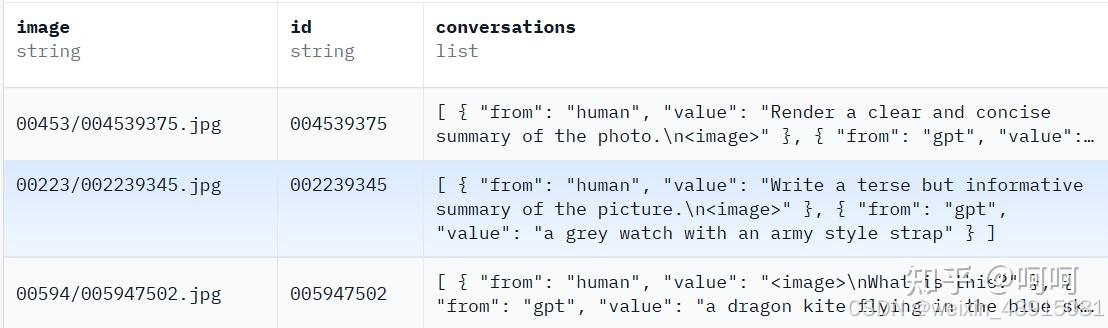
使用的数据是llava pretrain使用的数据,在hugging face中搜索数据集liuhaotian/LLaVA-Pretrain(链接如下):
数据链接
数据示意如下:
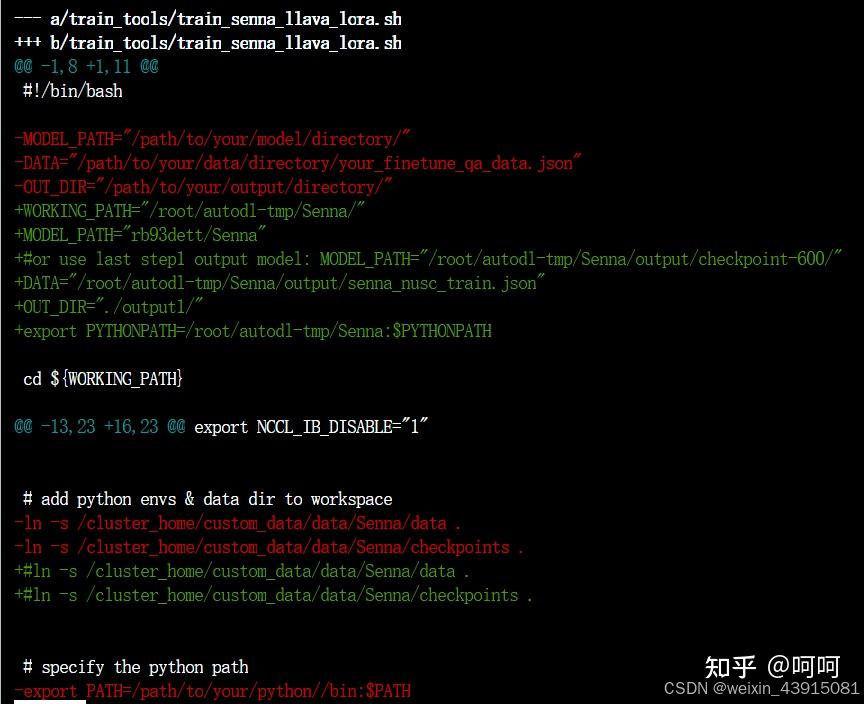
我改了一些官方的配置,大家仅供参考(git diff):
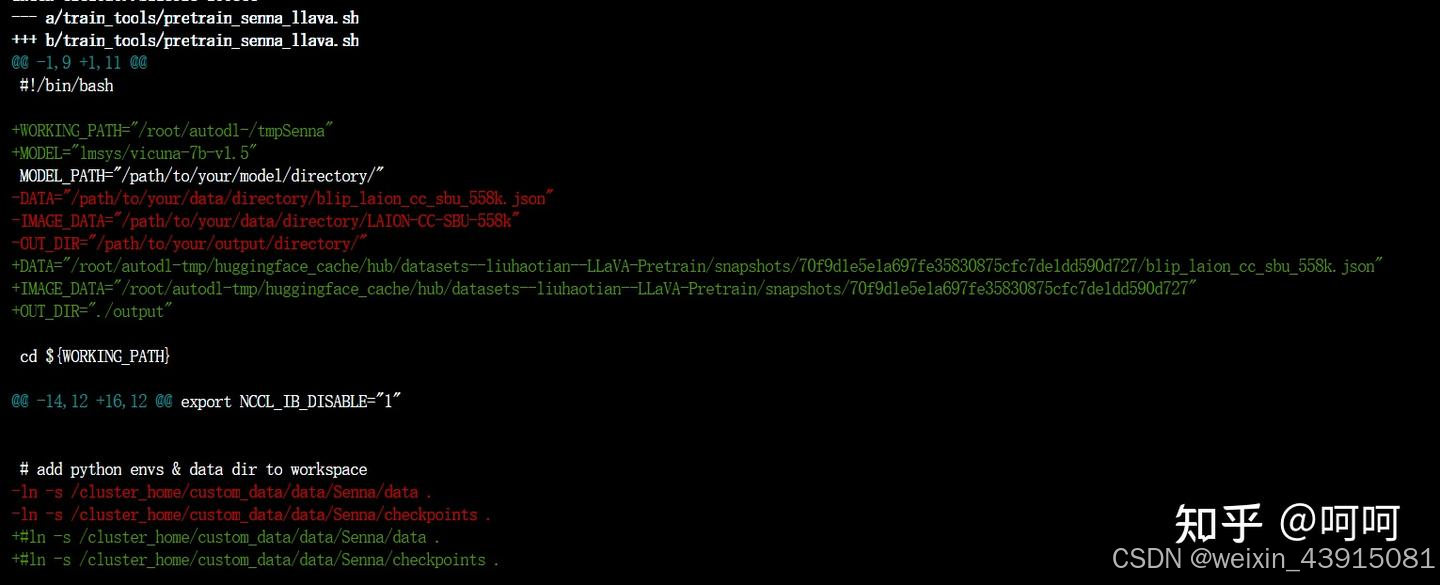
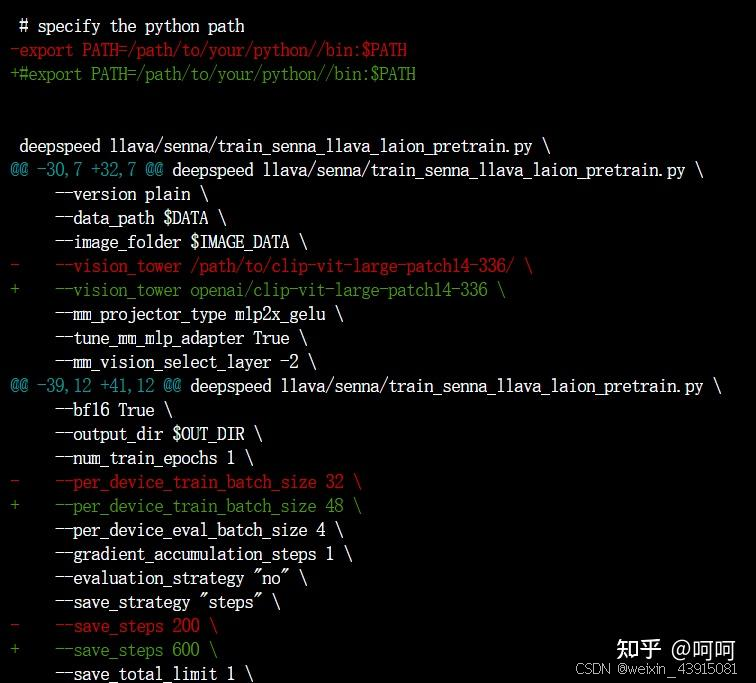
DATA和IMAGE_DATA就是上面数据集下载后你放的路径。base model就是lmsys/vicuna-7b-v1.5, 图片编码器用的是openai/clip-vit-large-patch14-336。这3部分(数据+base模型+图片编码模型)建议提前用 huggingface-cli提前下载下来。分别约27G+13G+3G。
这一步的训练我用了2个32G显存的GPU,所以batch size我调得比较大。刚试了下,只用一个gpu,per_device_train_batch_size=8时,显存用17G。
huggingface-cli配置方法文章后面有个链接可参考。huggingface-cli在初次登录时需要访问hugging face网站获取token,所以需要科学上网(我用的是“一支红杏”,链接见文末,100元/年,每个月100G流量,用起来还不错,不过在ubuntu下面只能用命令行开启程序,介意的请忽略),后续设置HF_ENDPOINT后就可以不用科学上网了。
再多说一些,我本地有一个3090GPU,微调7B的模型显存不太够。所以我用的是autodl算力平台(链接在文末),也是最近刚发现的,感觉真不错(不是广告)。我用了一个32G显存的GPU,可以正常的跑起来训练(忽略训练时间,主要目标就是跑起来),一个小时1.58,睡觉可以关机不要钱,比阿里云便宜太多,流量也不收费,以前用阿里云服务器下载数据,一个G 0.5元…,下载数据时可以用无卡模式,0.1元/时,好久没发现这么良心企业了。
第二,三步:驾驶微调
(上图的右上角stage2-3),根据提出的面向规划 QA 对 Senna-VLM 进行微调,但不包括meta-action规划 QA。在此步,使用环视多图像输入代替单图像输入。第三步是规划微调,仅使用meta-action规划 QA 进一步微调 Senna-VLM。在第二步和第三步,都微调 Senna-VLM 的所有参数,但视觉编码器除外,它保持冻结状态。
sh train_tools/train_senna_llava.sh
或sh train_tools/train_senna_llava_lora.sh
若显存不够,全量微调可以改为lora微调。
- 模型:此步用的base模型是第一步产出的模型,当然做实验的话,也可以用官方最终发布的模型,例如rb93dett/Senna,也是在huggingface下载。
- 数据:官方论文中一直提到driveX数据集,找了半天也没找到,如果有找到的,辛苦评论给我。另一部分数据是nuscene数据,下个章节单独讲它的生成。当然只用nuscene数据把训练跑起来没有问题。
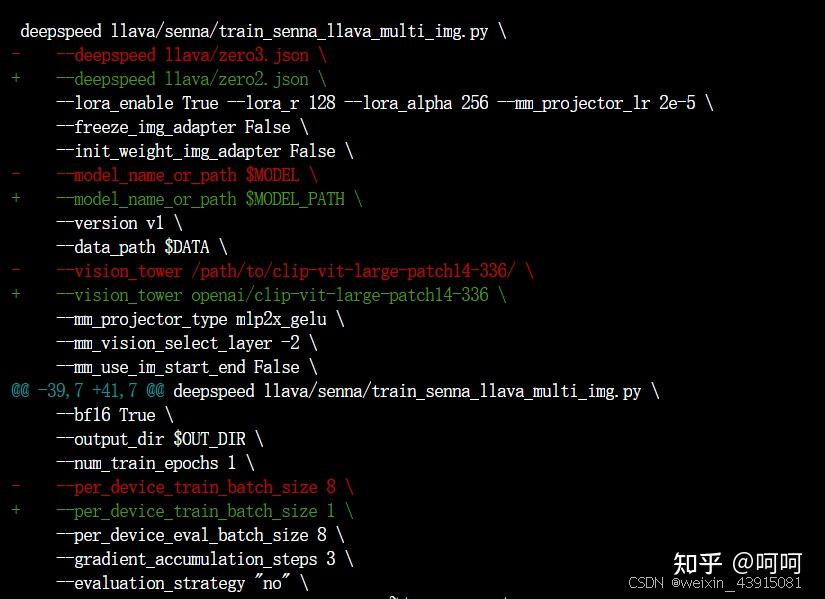
- 硬件:我用了一个32G的GPU,训练配置贴在下面。共用了25.4G的显存,开启了lora+gradient_checkpointing+batch size=2。
我改了部分配置如下,仅供参考:
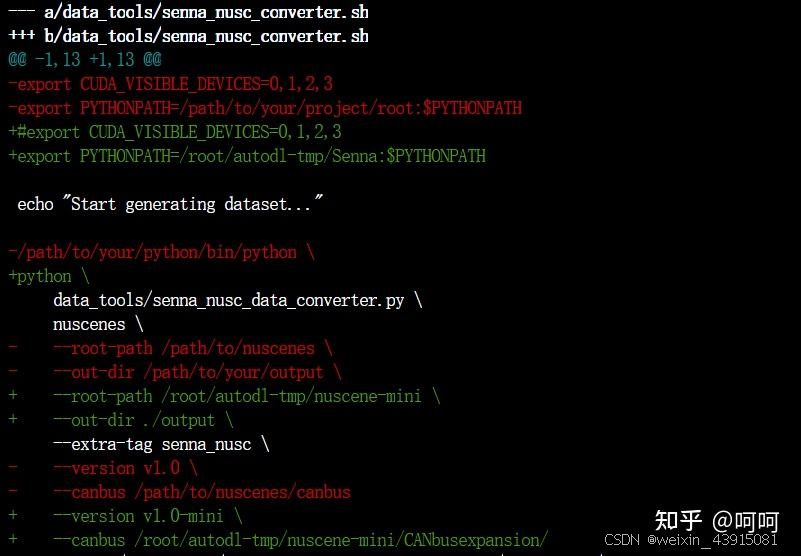
nuscene数据生成
sh data_tools/senna_nusc_converter.sh
官方用了LLaVA-v1.6-34b生成微调数据,这个模型比较大,如果不做量化的话,一个32G的GPU放不下。代码中默认的量化load_8bit一直出错,后来改为load_4bit就可以了,但效果可能会差一些,整体显存用了22.9G。生成数据太慢,一条数据生成需要6分钟左右,所以我只生成了5条数据用于测试,为什么这么慢,不知道原因,有知道的可以解答一下。
我生成的5条数据放在文末了,有需要的可以下载,有部分质量还不错,有的就不忍直视。
有篇讲量化的文章不错,链接放在文末,可以参考。
下面是我基于官方改的一些配置,仅供参考。
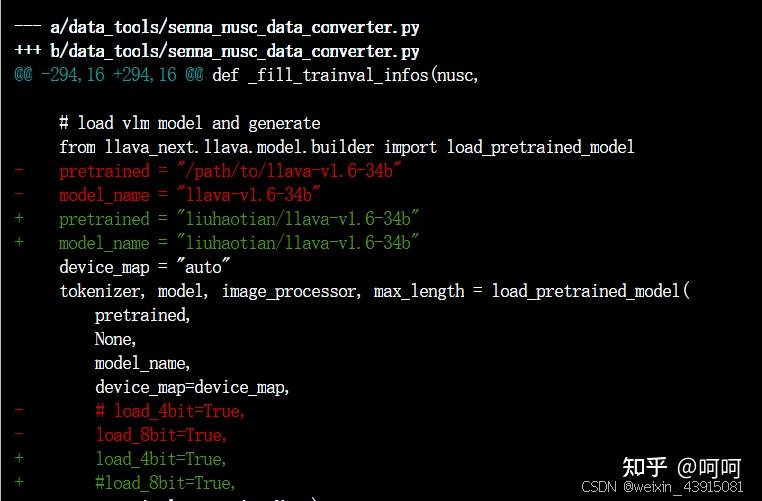
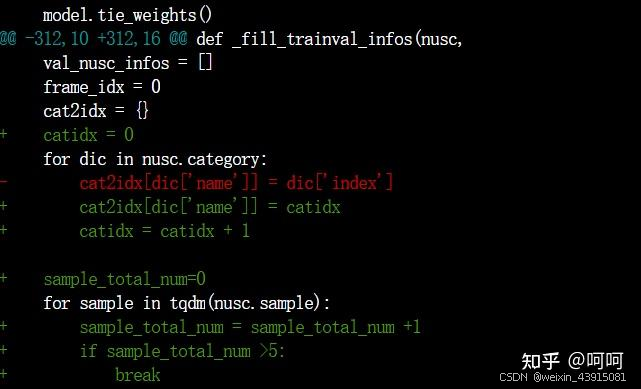
上图:1,修复了一个代码bug;2,只生成5条数据用于测试
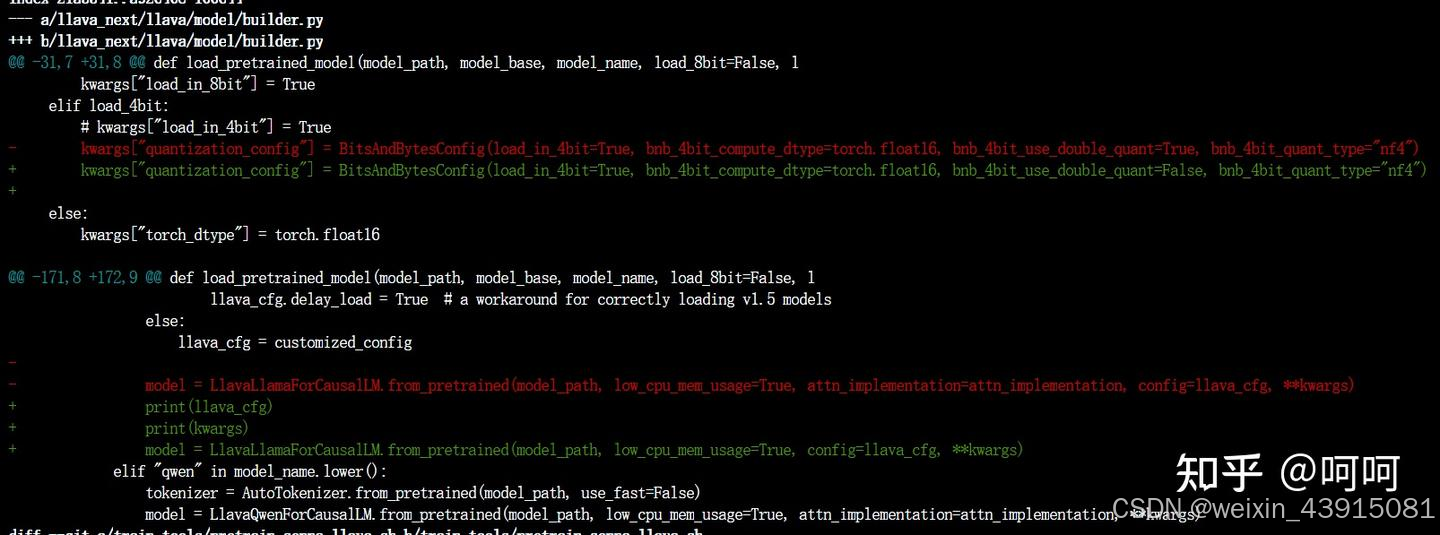
上图:attn_implementation参数提示不支持,我就把它删除了
另外,整个训练环境我没有完全按照官方github的配置,一般都是遇到问题再打平版本,建议大家还是按照官方的版本来配置,训练环境方面感觉不会有太大问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









