








此系列文章我命名一般是:具身智能xxx模型在lerobot机械臂上复现,但这篇文章不得不改一下名字,叫"跑通",而不是"复现",因为在实际的机械臂上效果不太好,抖动比较厉害,我训练了2种模型:
1,直接预测action
2,预测action的增量,也就是action与当前state之间的delta
第1种效果好于第2种,虽然不能完成抓取动作,但机械臂伸向目标,尝试抓取的意思是有了。另外,人工将目标放在盘子中后,机械臂也会自动还原到初始位置,说明整体上任务逻辑是学习到了,只是动作的精度不高,导致无法完成。整体上动作抖动比较厉害,因为3D打印的机械臂比较脆弱,我非常担心它会抖断了,^ v ^,从推理出来的数值来看,确实在抖动。第2种效果更差一些,因为infer的是动作的delta,所以可能出现delta一直大于0,最终动作失控的情况发生。
效果层面上与csdn上的一篇文章(如下)评价基本一致,“拾取水瓶然后放到盒子上,但实际上测试下来性能很一般,在拾取到水瓶后放置过去的过程手臂上下抖动幅度很大,最终也只能勉强完成任务。”
经过粗步思考,可能有以下几点原因吧:
1,未使用action chunk。以前复现成功的模型act,rdt,都使用了action chunk的思路,这样在模型训练的时候,相当于positive的样本会更多,模型更易收敛。
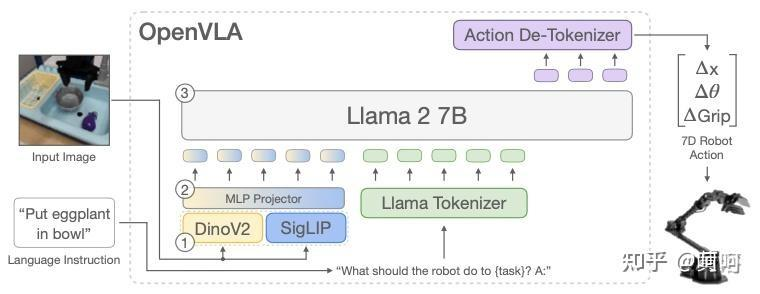
2,输入单一。openvla只使用了一个camera和一个指令,没有使用state信息,相对于其它模型使用2个以上相机,信息的丰富度上也差一些。
3,输出有误差。openvla将动作分成了256个bin,将连续值变成了离散值,引入了误差。另外,大语言模型预测next token的机制,在需要高精度控制的场景中,似乎也不是那么的合适。
4,与预训练模型所使用的数据的差异。预训练的openvla使用的数据,大部分都是ee控制,我这边的机械臂只有joint控制,这方面有一些不一致。
5,采集数据不够(50 epoches)?代码实现有bug ?等
无论如何,在这里先总结一下,提交一下代码,作为一个milestone,若大家有较好的实现或发现代码中的bug,欢迎指正。
1,数据处理
openvla模型默认使用的是rlds格式的数据,rlds格式是一种比较广泛使用的格式,而lerobot采集的数据有自有的格式,所以直接的思路就是将lerobot格式直接转换为rlds格式,作者也提供了一个代码库,可以实现数据格式转换为rlds格式,地址:GitHub - kpertsch/rlds_dataset_builder: An example RLDS dataset builder for X-embodiment dataset conversion., 但实操过程中,发现lerobot的环境与这个库的环境中numpy版本有冲突,导致lerobot环境中生成的npy文件(数据首先要转换成npy格式,然后再用这个库转换为rlds格式)在上面的库中不能使用,所以就曲线救国:
1,先将lerobot格式数据转换为hdf5格式(这个转换在上一篇文章中已经讲过了,链接)
2,然后将hdf5格式再转换为npy格式
代码提交在git@github.com:hxdoit/rlds_dataset_builder.git的lerobot_dataset/hdf5_2_npy.py
3,npy格式转rlds
直接按照官方的readme指引进行操作,使用tfds build命令即可生成,我将我采集的数据集命名为lerobot_dataset,所以会在下面的目录中生成文件,格式如下,转换后体积大大缩小,从20G(npy格式)->3G(tlds格式):
/home/ubuntu/tensorflow_datasets/lerobot_dataset/
└── 1.0.0
├── dataset_info.json
├── features.json
├── lerobot_dataset-train.tfrecord-00000-of-00032
├── lerobot_dataset-train.tfrecord-00001-of-00032
├── lerobot_dataset-train.tfrecord-00002-of-00032
......
2,模型训练
作者的训练代码对内存的需求比较高,刚开始训练需要30G(每gpu),然后可能有内存泄露,训练过程中内存会缓慢增长,在checkpoint保存的时候会突然升高到60G,训练时,建议持续关注内存使用,避免训练大半天,保存时失败的情况…。因为没有使用deepspeed等技术,只使用了torch的DDP,所以多gpu训练时,每个gpu配套的内存建议在80G以上。我使用了autodl上的vGPU(32G显存)*3,每个GPU配套有90G内存。batch size=20(grad_accumulation_steps)*4(micro_batch_size)*3(gpus)=240,共训练了1200个iter,花费6小时,每小时5元,训练成本30元左右
命令:
torchrun --standalone --nnodes 1 --nproc-per-node 3 vla-scripts/finetune.py --vla_path "/root/autodl-tmp/openvla/openvla-7b+lerobot_dataset+b80+lr-0.0005+lora-r32+dropout-0.0" --data_root_dir /root/autodl-tmp/needmove/tensorflow_datasets/ --dataset_name lerobot_dataset --run_root_dir /root/autodl-tmp/openvla/ --adapter_tmp_dir /root/autodl-tmp/openvla/adapter/ --lora_rank 32 --batch_size 4 --grad_accumulation_steps 20 --learning_rate 5e-4 --image_aug False >> train.log.1 2>&1 &
最终收敛:
{'train_loss': 0.05764721524901688, 'action_accuracy': 0.9803571492433548, 'l1_loss': 0.0006302521008403358, 'step': 400}
其中的action_accuracy是98%左右,根据作者的文章描述,应该能达到接近100%,所以成功率偏低,也是效果不达标的原因之一。
训练代码需要修改如下几个地方:
prismatic/vla/datasets/rlds/oxe/configs.py
+ "lerobot_dataset": {
+ "image_obs_keys": {"primary": "image", "secondary": None, "wrist": None},
+ "depth_obs_keys": {"primary": None, "secondary": None, "wrist": None},
+ "state_obs_keys": ["EEF_state", None, None],
+ "state_encoding": StateEncoding.JOINT,
+ "action_encoding": ActionEncoding.EEF_POS,
+ },
prismatic/vla/datasets/rlds/oxe/mixtures.py
+ "lerobot_dataset": [
+ ("lerobot_dataset", 1.0),
+ ],
prismatic/vla/datasets/rlds/oxe/transforms.py
+def lerobot_dataset_transform(trajectory: Dict[str, Any]) -> Dict[str, Any]:
+
+ trajectory["action"] = tf.concat(
+ [
+ trajectory["action"][:, :6],
+ tf.zeros_like(trajectory["action"][:, -1:]),
+ ],
+ axis=1,
+ )
+ trajectory["observation"]["EEF_state"] = trajectory["observation"]["state"][:, :6]
+ #trajectory["observation"]["gripper_state"] = trajectory["observation"]["state"][:, -2:] # 2D gripper state
+ return trajectory
OXE_STANDARDIZATION_TRANSFORMS = {
@@ -919,4 +931,5 @@ OXE_STANDARDIZATION_TRANSFORMS = {
"libero_object_no_noops": libero_dataset_transform,
"libero_goal_no_noops": libero_dataset_transform,
"libero_10_no_noops": libero_dataset_transform,
+ "lerobot_dataset": lerobot_dataset_transform,
}
可以看到,针对不同来源的数据,作者是通过不同数据源定义上述配置来做到统一处理,参与训练的。与RDT (链接)的实现方式类似。
3,测试评估
我已经将openvla与lerobot机械臂打通,代码提交在git@github.com:hxdoit/lerobot.git中,文件:lerobot/scripts/control_robot_openvla.py,在本地的3090上,可以达到3hz的推理频率,还是稍微有些慢的。

















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









