







熟悉大语言模型的对ChatGPT 都不陌生吧!ChatGPT 由于具备出色的人机对话能力和任务解决能力,一经发布就引发了全社会对于大语言模型的广泛关注,众多的大语言模型应运而生,并且数量还在不断增加。
大语言模型发展时间线:
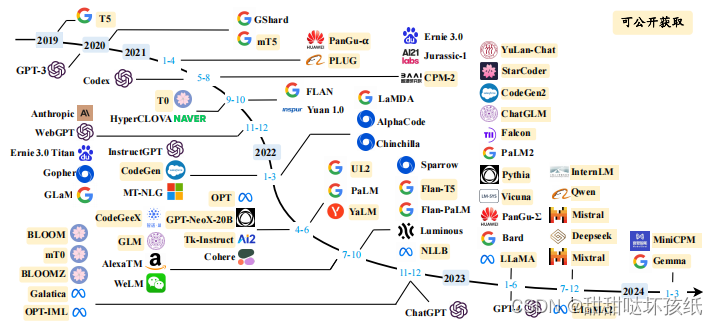
GPT 系列模型技术发展的历程图:
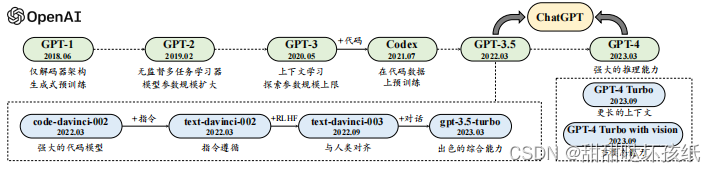
截止到目前,OpenAI 对大语言模型的研发历程大致可分为四个阶段:早期探索阶段、路线确立阶段、能力增强阶段以及能力跃升阶段,下面进行具体介绍。
早期探索阶段
根据对于 Ilya Sutskever(OpenAI 联合创始人、前首席科学家)的采访,OpenAI 在成立初期就尝试使用语言模型研发人工智能系统,但当时使用的是循环神经网络,模型能力和并行训练能力还存在较大的局限性。Transformer 刚刚问世,就引起了 OpenAI 团队的高度关注,并且将语言模型的研发工作切换到 Transformer架构上,相继推出了两个初始的 GPT 模型,即 GPT-1和 GPT-2,这两个早期工作奠定了后续更强大的 GPT 模型(如 GPT-3和GPT-4)的研究基础。
• GPT-1
2017 年,Google 推出 Transformer 模型后,OpenAI 团队马上意识到这种神经网络架构将显著优于传统序列神经网络的性能,有可能对于研发大型神经网络产生重要的影响。他们很快着手使用 Transformer 架构研发语言模型,并于 2018 年发布了第一个 GPT 模型,即 GPT-1,模型名称 GPT 是生成式预训练的缩写。GPT-1 基于生成式、仅有解码器的 Transformer架构开发,奠定了 GPT 系列模型的核心架构与基于自然语言文本的预训练方式,即预测下一个词元。由于当时模型的参数规模还相对较小,模型仍然缺乏通用的任务求解能力,因而采用了无监督预训练和有监督微调相结合的范式。与 GPT-1同期发布的预训练语言模型是大名鼎鼎的 BERT 模型。BERT 与 GPT-1 虽然都采用了基于 Transformer 架构的预训练学习方式,但是它主要面向自然语言理解任务,为此只保留了 Transformer 中的编码器,其中 BERT-Large 模型在众多的自然语言理解任务上取得了非常重要的提升,成为当时备受瞩目的“明星模型”。可以说,BERT 当时引领了自然语言处理社区的研究浪潮,涌现了大量针对它改进与探索的工作。由于 GPT-1 模型规模实际
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









