







 本文深入探讨Transformer模型,介绍了输入编码、多头自注意力机制、前馈网络层、编码器和解码器的工作原理。Transformer通过多头自注意力解决了长距离依赖问题,适合大规模参数优化,并在编码器和解码器中应用层归一化和残差连接增强训练稳定性。
本文深入探讨Transformer模型,介绍了输入编码、多头自注意力机制、前馈网络层、编码器和解码器的工作原理。Transformer通过多头自注意力解决了长距离依赖问题,适合大规模参数优化,并在编码器和解码器中应用层归一化和残差连接增强训练稳定性。
当前主流的大语言模型都基于 Transformer 模型进行设计的。Transformer 是由多层的多头自注意力模块堆叠而成的神经网络模型。原始的 Transformer 模型由编码器和解码器两个部分构成,而这两个部分实际上可以独立使用,例如基于编码器架构的 BERT 模型和解码器架构的 GPT 模型。与 BERT 等早期的预训练语言模型相比,大语言模型的特点是使用了更长的向量维度、更深的层数,进而包含了更大规模的模型参数,并主要使用解码器架构,对于 Transformer 本身的结构与配置改变并不大。本部分内容将首先介绍 Transformer模型的基本组成,包括基础的输入、多头自注意力模块和前置网络层;接着分别介绍 Transformer 模型中的编码器和解码器模块。
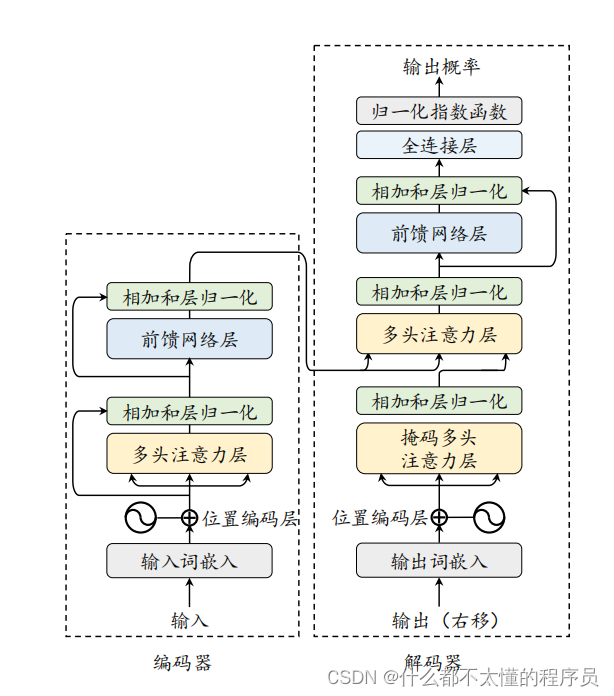
输入编码
在 Transformer 模型中,输入的词元序列 (𝒖 = [𝑢1, 𝑢2, . . . , 𝑢𝑇]) 首先经过一个输入嵌入模块(Input Embedding Module)转化成词向量序列。具体来说,为了捕获词汇本身的语义信息,每个词元在输入嵌入模块中被映射成为一个可学习的、具有固定维度的词向量 𝒗𝑡 ∈ R𝐻。由于 Transformer 的编码器结构本身无法识别序列中元素的顺序,位置编码(Position Embedding, PE)被引入来表示序列中的位置信息。给定一个词元 𝑢𝑡,位置编码根据其在输入中的绝对位置分配一个固定长度的嵌入向量 𝒑&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









