







Lempel-Ziv 压缩方法
粗略定义:
Lempel-Ziv(LZ)是一种压缩方法,可用于任何大小长度的任何字母的文件压缩
历史及简介
LZ算法最早由亚伯拉罕·伦佩尔(Abraham Lempel)和雅各布·齐夫(Jacob Ziv)于1977年在论文“A Universal Algorithm for Sequential Data Compression”中引入。
LZ算法拥有自适应的能力,通过下面所介绍的一种数字搜索树的数据结构,能够完成多种输入符号的文件的压缩。目前许多主流的压缩软件,例如:7z、zip等,均是通过此类算法的变形,LZ77,LZ78包括其他种种整合而成。
应用方法
- 从左到右遍历,将所有之前未出现的字符组合标号
- 通过刚刚标号的新数组重新表示整个数组,其中,最后一位用字母表中的一个数表示
- 通过刚刚得到的字符加数组的组合,将每个字符组合定义为标号长度+定长的字母表的编码,完成压缩
EXAMPLE
我们知道某个文件有三种字符,{a,b,c}。并且现有一种文件,它输入的内容为:
abaabcaaabbcaaaa
我们对此开始进行一系列的标号操作,从最左端开始。
对所有之前没有出现的都进行标注。
如以下表格所示,一开始,从空集为0开始,给后来未出现的情况进行标号1~8
然后第三行开始,我们都用前面出现过的代号,加一个全新的符号,来进行标识,如第三行表示。
| - | a | b | aa | bc | aaa | bb | c | aaaa |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 0 | 0a | 0b | 1a | 1b | 3a | 2b | 0c | 5a |
接下来,我们在已经构造的输出中构造位序列。编码输出序列所需的位数是编码指向当前片段前缀的整数所需的最小位数加上编码一个符号B所需的位数。
其中B为大小为k的字母表进行编码所需要的位数,其计算方法为
B = [ log 2 k ] B = [\log_{2}{k}] B=[log2k]
继续进行编辑
| - | a | b | aa | bc | aaa | bb | c | aaaa |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 0 | 0a | 0b | 1a | 1b | 3a | 2b | 0c | 5a |
| 0 | 0+B | 1+B | 2+B | 2+B | 3+B | 3+B | 3+B | 3+B |
上面的例子中,第八位aaaa,翻译成5a,需要3位来表示编号5,然后有一个B位表示a。
其中B位表示了所需的所有字母表的数据,{a,b,c}
数字搜索树(DST)
粗浅定义:
数字搜索树是一个k元树,其中k是输入文件的字母表的大小,每个边对应于k个符号中的一个。
图示
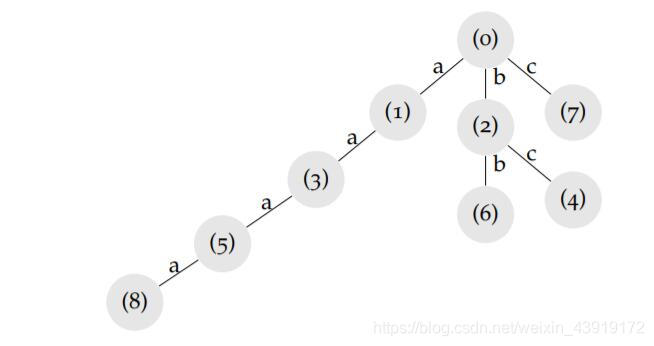
数字搜索数的简单描述
- 为LZ算法进行编码的数字搜索树,从根节点“0”开始,每个节点与每个“碎片段”相连接,构成树。每个情况的标号,或者说,权重,如图所标识。
- 连接的上端为父节点,下面为子节点,所标注的即为权重。
编码
在分析输入字符串时创建上述数字搜索树,通过处理每个符号来跟踪DST中的正确路径,直到达到数码0(nil)或需要新的分支,在这种情况下,编码时在树中插入相应的节点。由于每个输入符号在编码器中引起一个步骤,很明显这需要O(n)时间,其中n是输入符号的数目。编码器完成编码后,可以丢弃DST,因为压缩信息完全包含在上面描述的输出序列中。因此,我们完全可以把编码视为构建DST本身。
解码
Lempel-Ziv方法的解码是通过观察带有父指针的数字搜索树,因此可以应用数组来实现对数据的解码,如下所示:
| pointer | parent | edge value |
|---|---|---|
| 1 | 0 | a |
| 2 | 0 | b |
| 3 | 1 | a |
| 4 | 2 | c |
| 5 | 3 | a |
| 6 | 2 | b |
| 7 | 0 | c |
| 8 | 5 | a |
从LZ方法解码压缩信息所用的时间是O(n),与编码一样,通过将DST逆向为一个数组,每个符号一次解压缩一个。每个数组索引都有一个指向其父索引的指针,该指针允许解码器在O(n)时间内重新创建原始信息。
注意
假设在某个概率模型下,输入序列具有熵E,那么对于很广泛的模型序列情况下,输出序列的预期长度非常接近其理论下限即香农下界,即所覆盖的模型包括从一组具有给定概率的单词中提取的独立单词数据流。有趣的是,与前缀固定编码不同,我们不需要事先知道这些概率,因为Lempel-Ziv方法会自动调整自身,来适应各种状况
关于香农下界和前缀编码等说明,可以参照我另一篇博客,对信息论、编码熵等进行了简单的描述:
浅谈香农定理、信息论、熵
本文的是在学习下面的公开演讲与文章后、整合处理来的,附上文件名,有兴趣的朋友可以自行阅读
A Lecture on the Lempel-Ziv Compression Method
Jacob Bettencourt
March 30, 2018

















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









