







关联分析直观理解
频繁项集(frequent itemset)是指那些经常出现在一起的物品集合,比如{葡萄酒,尿布, 豆奶}就是频繁项集的一个例子。

一般我们使用三个指标来度量一个关联规则,这三个指标分别是:支持度、置信度和提升度。
-
Support(支持度):表示同时包含A和B的事务占所有事务的比例。如果用P(A)表示使用A事务的比例,那么
Support=P(A&B)
-
Confidence(可信度):表示使用包含A的事务中同时包含B事务的比例,即同时包含A和B的事务占包含A事务的比例。
Confidence=P(A&B)/P(A)
-
Lift(提升度):表示“包含A的事务中同时包含B事务的比例”与“包含B事务的比例”的比值。
Lift=(P(A&B)/P(A))/P(B)=P(A&B)/P(A)/P(B)。
提升度反映了关联规则中的A与B的相关性,提升度>1且越高表明正相关性越高,提升度<1且越低表明负相关性越高,提升度=1表明没有相关性。
举一个例子:
10000个超市订单(10000个事务),其中购买三元牛奶(A事务)的6000个,购买伊利牛奶(B事务)的7500个,4000个同时包含两者。
那么通过上面支持度的计算方法我们可以计算出:
三元牛奶(A事务)和伊利牛奶(B事务)的支持度为:P(A&B)=4000/10000=0.4.
三元牛奶(A事务)对伊利牛奶(B事务)的置信度为:包含A的事务中同时包含B的占包含A的事务比例。4000/6000=0.67,说明在购买三元牛奶后,有0.67的用户去购买伊利牛奶。
伊利牛奶(B事务)对三元牛奶(A事务)的置信度为:包含B的事务中同时包含A的占包含B的事务比例。4000/7500=0.53,说明在购买伊利牛奶后,有0.53的用户去购买三元牛奶。
上面我们可以看到A事务对B事务的置信度为0.67,看似相当高,但是其实这是一个误导,为什么这么说?
因为在没有任何条件下,B事务的出现的比例是0.75,而出现A事务,且同时出现B事务的比例是0.67,也就是说设置了A事务出现这个条件,B事务出现的比例反而降低了。这说明A事务和B事务是排斥的。
下面就有了提升度的概念。
我们把0.67/0.75的比值作为提升度,即P(B|A)/P(B),称之为A条件对B事务的提升度,即有A作为前提,对B出现的概率有什么样的影响,如果提升度=1,说明A和B没有任何关联,如果<1,说明A事务和B事务是排斥的,>1,我们认为A和B是有关联的,但是在具体的应用之中,我们认为提升度>3才算作值得认可的关联。
提升度是一种很简单的判断关联关系的手段,但是在实际应用过程中受零事务的影响比较大,零事务在上面例子中可以理解为既没有购买三元牛奶也没有购买伊利牛奶的订单。数值为10000-4000-2000-3500=500,可见在本例中,零事务非常小,但是在现实情况中,零事务是很大的。在本例中如果保持其他数据不变,把10000个事务改成1000000个事务,那么计算出的提升度就会明显增大,此时的零事务很大(1000000-4000-2000-3500),可见提升度是与零事务有关的。
根据《数据挖掘概念与技术》一书的说法,常用的判断方法不是提升度,而是 KULC度量+不平衡比(IR) 。他们可以有效的降低零事务造成的影响。
-
下面补充一下KULC和IR的说明:
KULC=0.5P(B|A)+0.5P(A|B)
IR=P(B|A)/P(A|B)
该公式表示 将两种事件作为条件的置信度的均值,避开了支持度的计算,因此不会受零和事务的影响。在上例中6000个事务包含三元牛奶,75000个包含伊利牛奶,同时购买依旧为4000 则:
KULC=0.5*(4000/75000+4000/6000)=0.36,
IR=(4000/6000)/(4000/75000)=12.5
这说明这两个事务的关联关系非常不平衡,购买三元牛奶的顾客很可能同时会买伊利牛奶,而购买了伊利牛奶的用户不太会再去买三元牛奶。很好理解,A对B的支持度远远高于B对A的支持度。
Apriori算法
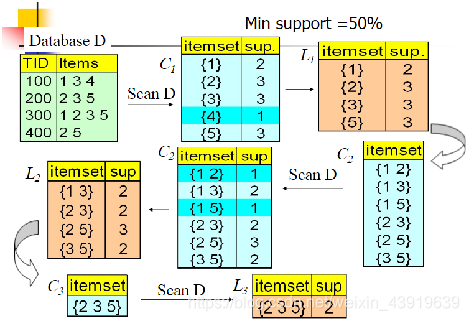
我们的数据集D有4条记录,分别是134,235,1235和25。
现在我们用Apriori算法来寻找频繁k项集,最小支持度设置为50%。
首先我们生成候选频繁1项集,包括我们所有的5个数据并计算5个数据的支持度,计算完毕后我们进行剪枝,数据4由于支持度只有25%被剪掉。我们最终的频繁1项集为1,2,3,5
现在我们链接生成候选频繁2项集,包括12,13,15,23,25,35共6组。
扫描数据集计算候选频繁2项集的支持度,由于12和15的支持度只有25%而被筛除,得到真正的频繁2项集,包括13,23,25,35。
链接生成候选频繁3项集,按照字典序组合,得到235。
Apriori算法改进
从算法的运行过程,我们可以看出该Apriori算法的优点:简单、易理解、数据要求低,然而我们也可以看到Apriori算法的缺点:
(1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;(通常我们会对k-1频繁项集做排序生成k频繁项集)
(2)每次计算项集的支持度时,都对数据库D中的全部记录进行了一遍扫描比较,如果是一个大型的数据库的话,这种扫描比较会大大增加计算机系统的I/O开销。而这种代价是随着数据库的记录的增加呈现出几何级数的增加。因此人们开始寻求更好性能的算法。
- 基于hash表的项集计数
将每个项集通过相应的hash函数映射到hash树(比哈希表节省空间)中的不同的桶中,这样可以通过将桶中的项集技术跟最小支持计数相比较先淘汰一部分项集,因为哈希树删除节点时不需要要调整结构,每次查找不会超过10次计算(10层就够用了)。 - 事务压缩(压缩进一步迭代的事务数)
不包含任何k-项集的事务不可能包含任何(k+1)-项集,这种事务在下一步的计算中可以加上标记或删除。删除事务 - 划分
D中的任何频繁项集必须作为局部频繁项集至少出现在一个部分中。
第一次扫描:将数据划分为多个部分并找到局部频繁项集
第二次扫描:评估每个候选项集的实际支持度,以确定全局频繁项集。 - 选样(在给定数据的一个子集挖掘)
基本思想:选择原始数据的一个样本,在这个样本上用Apriori算法挖掘频繁模式
通过牺牲精确度来减少算法开销,为了提高效率,样本大小应该以可以放在内存中为宜,可以适当降低最小支持度来减少遗漏的频繁模式
可以通过一次全局扫描来验证从样本中发现的模式
可以通过第二此全局扫描来找到遗漏的模式 - 动态项集计数
在扫描的不同点添加候选项集,这样,如果一个候选项集已经满足最少支持度,则在可以直接将它添加到频繁项集,而不必在这次扫描的以后对比中继续计算。














 3316
3316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









