






一、目标
- 从给定的一组事务中寻找某些依赖规则,是的可以通过一些项目的出现来预测另外一些项目的出现。
- 寻找支持度、置信度大于给定阈值的关联规则。
二、基本概念
- 项集Itemset:包含有多项的集合;
- 支持度计数Support count(σ ):某一项集的出现次数;
- 支持度Support:某一项集出现次数的比例;P(A),及项集A出现的概率(频数);
-
置信度:P(B / A), 条件概率; P(B / A)= P(AB)/P(A);
- 频繁项集Frequent Itemset:支持度大于阈值minsup的某一项集;
- 关联规则Association Rule:一个项集到另一个项集的映射X - > Y;
- 关联规则评价标准:1)支持度:X、Y合并项集的支持度;2)置信度Confidence:包含X的事务中包含Y的比例。


三、挖掘过程
- 设定参数minsup、minconf;
- 生成频繁子集:寻找所有支持度大于阈值的项集;
- 生成关联规则:从频繁项集中生成高置信度的关联规则,每一个规则都是对应频繁子集的二分划分。
四、寻找频繁子集
1.寻找过程
- 构建项目Item的子集树
- 利用Apriori算法进行剪枝
- 构造候选项集的哈希树来减少比较次数
2.Apriori原理(先验原理)
如果一个项集是频繁的,那么它的所有子集都是频繁的。Apriori原理的精妙在于他的逆否命题,若子集不是频繁的,则所有包含它的项集都是不频繁的。


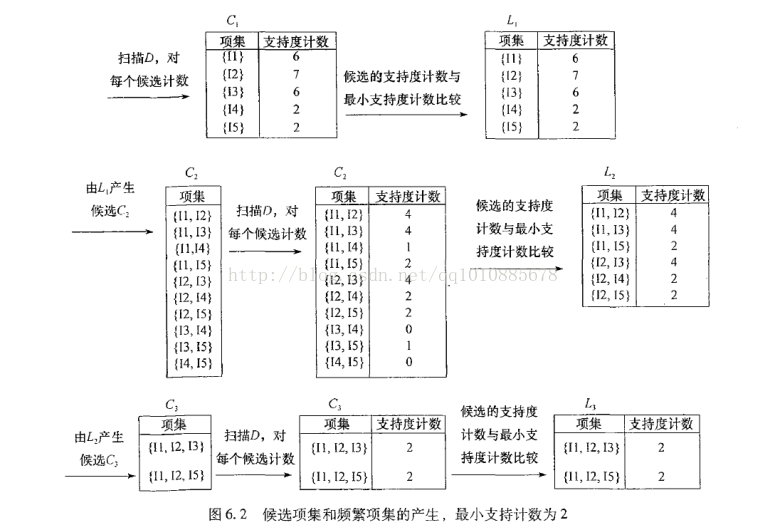
3.Apriori算法
- 令k=1;生成1-频繁项集;重复此步骤
- 从k-频繁项集生成( k + 1) - 候选项集
- 减掉不频繁k - 项集的后代项集
- 扫描数据库,计算每个候选项集的支持度
- 将支持度低于阈值的项集滤除直至没有新的候选项集生成
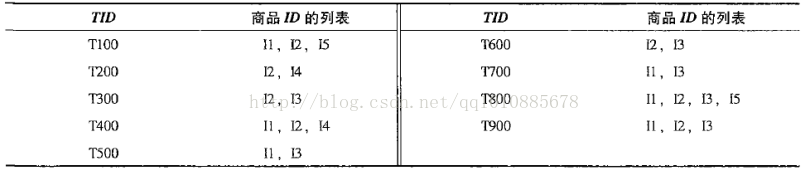
{i1,i2}=>i3,表示购买了i1,i2的用户中还购买了i3的用户所占的比例。{i1,i2,i3}的出现次数为2,{i1,i2}的出现次数为4,故置信度为2/4=50%
类似的可以算出
{i1,i3}=>i2,confidence=50%
{i2,i3}=>i1,confidence=50%
i1=>{i2,i3},confidence=33%i2=>{i1,i3},confidence=28%
i3=>{i1,i2},confidence=33%
4.频繁项集的紧致表示
- 极大项集:直接超级都不频繁的项集;形成了可以到处所有频繁项集的最小的项集的集合。
- 闭项集:直接超级的支持度都比它自己小的项集
- 如果一个项集是闭项集,并且满足最小支持度要求,称为闭频繁项集
五、FP增长算法
1.FP树表示
课本224详细过程(nb239)

2.频繁项集的产生
FP增长是一种自底向上方式探索树 PPT55~85过程

https://blog.csdn.net/yutao03081/article/details/77127500 (算法详解)
六、关联规则产生

七、关联模式评估
1.兴趣度的客观度量:是一种评估关联模式质量的数据驱动方法。
- 提升度
- 兴趣因子
- 相关分析
- 性质:反演性、零加性、缩放性
2.多个二元变量的度量
3.辛普森悖论
















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









