








基础篇:STL容器和算法
目录:
- 1. 什么是STL?
- 2. Sequence containers
- 3. Associative containers
- 4. tuple
- 5. 容器配接器
- 6. 算法
- 7. 总结
以下个人总结,如有侵权,请联系删除,如有错误,欢迎大家指正,谢谢!
1. 什么是STL?
1) STL(Standard Template Library),即标准模板库,是一个高效的C++程序库,包含了诸多常用的基本数据结构和基本算法。为广大C++程序员们提供了一个可扩展的应用框架,高度体现了软件的可复用性。
2) 从逻辑层次来看,在STL中体现了泛型化程序设计的思想(generic programming)。在这种思想里,大部分基本算法被抽象,被泛化,独立于与之对应的数据结构,用于以相同或相近的方式处理各种不同情形。
3) 从实现层次看,整个STL是以一种类型参数化(type parameterized)的方式实现的,基于模板(template)。
STL有六大组件,但主要包含容器、算法和迭代器三个部分。
- 容器(Containers):用来管理某类对象的集合。各种数据结构,如vector、list、deque、set、map等,用来存放数据,从实现角度来看,STL容器是一种class template。
- 算法(Algorithms):用来处理对象集合中的元素,各种常用的算法,如sort、find、copy、for_each。从实现的角度来看,STL算法是一种function template。
- 迭代器(Iterators):用来在一个对象集合的元素上进行遍历动作。扮演了容器与算法之间的胶合剂,共有五种类型,从实现角度来看,迭代器是一种将operator* , operator-> , operator++, operator–等指针相关操作予以重载的class template。所有STL容器都附带有自己专属的迭代器,只有容器的设计者才知道如何遍历自己的元素。原生指针(native pointer)也是一种迭代器。
- 仿函数:行为类似函数,可作为算法的某种策略。从实现角度来看,仿函数是一种重载了operator()的class 或者class template。
- 适配器:一种用来修饰容器或者仿函数或迭代器接口的东西。
- 空间配置器:负责空间的配置与管理。从实现角度看,配置器是一个实现了动态空间配置、空间管理、空间释放的class tempalte。
STL 的基本观念就是将数据和操作分离。数据由容器进行管理,操作则由算法进行,而迭代器在两者之间充当粘合剂,使任何算法都可以和任何容器交互运作。通过迭代器的协助,我们只需撰写一次算法,就可以将它应用于任意容器之上,这是因为所有容器的迭代器都提供一致的接口。
STL六大组件的交互关系,容器通过空间配置器取得数据存储空间,算法通过迭代器存储容器中的内容,仿函数可以协助算法完成不同的策略的变化,适配器可以修饰仿函数。
STL的优点:
1) STL 是 C++的一部分,因此不用额外安装什么,它被内建在你的编译器之内。
2) STL 的一个重要特性是将数据和操作分离。数据由容器类别加以管理,操作则由可定制的算法定义。迭代器在两者之间充当“粘合剂”,以使算法可以和容器交互运作。
3) 程序员可以不用思考 STL 具体的实现过程,只要能够熟练使用 STL 就 OK 了。这样他们就可以把精力放在程序开发的别的方面。
4) STL 具有高可重用性,高性能,高移植性,跨平台的优点。
5) 高可重用性:STL 中几乎所有的代码都采用了模板类和模版函数的方式实现,这相比于传统的由函数和类组成的库来说提供了更好的代码重用机会。
6) 高性能:如 map 可以高效地从十万条记录里面查找出指定的记录,因为 map 是采用红黑树的变体实现的。
7) 高移植性:如在项目 A 上用 STL 编写的模块,可以直接移植到项目 B 上。容器和算法之间通过迭代器进行无缝连接。STL 几乎所有的代码都采用了模板类或者模板函数,这相比传统的由函数和类组成的库来说提供了更好的代码重用机会。
STL容器就是将运用最广泛的一些数据结构实现出来。容器用来管理某类对象。常用的数据结构:数组(array) , 链表(list), tree(树),栈(stack), 队列(queue), 集合(set),映射表(map), 根据数据在容器中的排列特性,这些数据分为序列式容器和关联式容器两种。
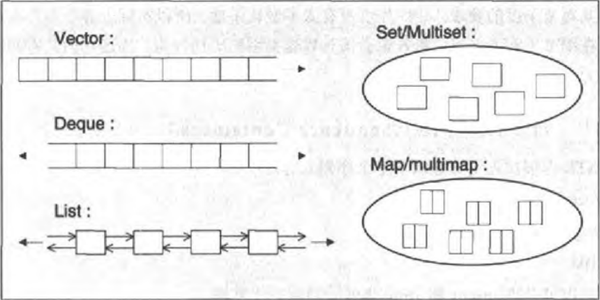
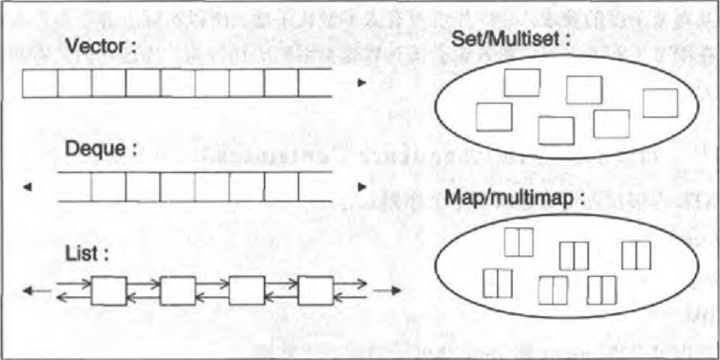
2. Sequence containers
序列式容器(Sequence containers),其中每个元素均有固定位置—取决于插入时机和地点,和元素值无关。如果你以追加方式对一个群集插入六个元素,它们的排列次序将和插入次序一致。STL提供了三个序列式容器:向量(vector)、双端队列(deque)、列表(list),此外也可以把 string 和 array 当做一种序列式容器。
1) vector
vector: 是一种序列式容器,事实上和数组差不多,但它比数组更优越。一般来说数组不能动态拓展,因此在程序运行的时候不是浪费内存,就是造成越界。而 vector 正好弥补了这个缺陷,它的特征是相当于可拓展的数组(动态数组),它的随机访问快,在中间插入和删除慢,但在末端插入和删除快。
优缺点和适用场景
优点:支持随机访问,即 [] 操作和 .at(),所以查询效率高。
缺点:当向其头部或中部插入或删除元素时,为了保持原本的相对次序,插入或删除点之后的所有元素都必须移动,所以插入的效率比较低。
适用场景:适用于对象简单,变化较小,并且频繁随机访问的场景。
2)array
看到这个容器的时候肯定会出现这样的问题:
(1) 为什么要引入 std::array 而不是直接使用 std::vector?
与std::vector不同,std::array对象的大小是固定的,如果容器大小是固定的,那么可以优先考虑使用std::array容器。 另外由于std::vector是自动扩容的,当存入大量的数据后,并且对容器进行了删除操作, 容器并不会自动归还被删除元素相应的内存,这时候就需要手动运行shrink_to_fit()释放这部分内存。
(2) 已经有了传统数组,为什么要用 std::array?
使用std::array能够让代码变得更加“现代化”,而且封装了一些操作函数,比如获取数组大小以及检查是否非空,同时还能够友好的使用标准库中的容器算法,比如std::sort。
当我们开始用上了std::array时,难免会遇到要将其兼容 C 风格的接口,这里有三种做法:
void foo(int *p, int len) {
return;
}
std::array<int, 4> arr = {1,2,3,4};
// C 风格接口传参
// foo(arr, arr.size()); // 非法, 无法隐式转换
foo(&arr[0], arr.size());
foo(arr.data(), arr.size());
// 使用 std::sort
std::sort(arr.begin(), arr.end());
3) deque
deque(double-ended queue)是由一段一段的定量连续空间构成。一旦要在 deque 的前端和尾端增加新空间,便配置一段定量连续空间,串在整个 deque 的头端或尾端。因此不论在尾部或头部安插元素都十分迅速。 在中间部分安插元素则比较费时,因为必须移动其它元素。deque 的最大任务就是在这些分段的连续空间上,维护其整体连续的假象,并提供随机存取的接口。


deque 是 list 和 vector 的折中方案。兼有 list 的优点,也有vector 随机线性访问效率高的优点。
优缺点和适用场景
优点:支持随机访问,即 [] 操作和 .at(),所以查询效率高;可在双端进行 pop,push。
缺点:不适合中间插入删除操作;占用内存多。
适用场景:适用于既要频繁随机存取,又要关心两端数据的插入与删除的场景。
4) list
List 由双向链表(doubly linked list)实现而成,元素也存放在堆中,每个元素都是放在一块内存中,它的内存空间可以是不连续的,通过指针来进行数据的访问,这个特点使得它的随机存取变得非常没有效率,因此它没有提供 [] 操作符的重载。但是由于链表的特点,它可以很有效率的支持任意地方的插入和删除操作。


访问开始和最后两个元素最快,其他元素的访问时间一样。
优缺点和适用场景
优点:内存不连续,动态操作,可在任意位置插入或删除且效率高。
缺点:不支持随机访问。
适用场景:适用于经常进行插入和删除操作并且不经常随机访问的场景。
5) forward_list
std::forward_list 是一个列表容器,使用方法和 std::list 基本类似。
需要知道的是,和 std::list 的双向链表的实现不同,std::forward_list 使用单向链表进行实现, 提供了 O(1) 复杂度的元素插入,不支持快速随机访问(这也是链表的特点), 也是标准库容器中唯一一个不提供 size() 方法的容器。当不需要双向迭代时,具有比 std::list 更高的空间利用率。


3. Associative containers
关联式容器(Associative containers),元素位置取决于特定的排序准则以及元素值,和插入次序无关。如果你将六个元素置入这样的群集中,它们的位置取决于元素值,和插入次序无关。STL提供了四个关联式容器:集合(set)、多重集合(multiset)、映射(map)和多重映射(multimap)。
1) set
set:由红黑树实现,其内部元素依据其值自动排序,每个元素值只能出现一次,不允许重复。set 中的元素都是排好序的,集合中没有重复的元素。
map 和 set 的插入删除效率比用其他序列容器高,因为对于关联容器来说,不需要做内存拷贝和内存移动。
优缺点和适用场景
优点:使用平衡二叉树实现,便于元素查找,且保持了元素的唯一性,以及能自动排序。
缺点:每次插入值的时候,都需要调整红黑树,效率有一定影响。
适用场景:适用于经常查找一个元素是否在某群集中且需要排序的场景。
另外, Multiset 和 set 相同,只不过它允许重复元素,也就是说 multiset 可包括多个数值相同的元素。
2) map
map 由红黑树实现,其元素都是 “键值/实值” 所形成的一个对组(key/value pairs)。每个元素有一个键,是排序准则的基础。每一个键只能出现一次,不允许重复。
map 主要用于资料一对一映射的情况,map 内部自建一颗红黑树,这颗树具有对数据自动排序的功能,所以在 map 内部所有的数据都是有序的。比如一个班级中,每个学生的学号跟他的姓名就存在着一对一映射的关系。
对于迭代器来说,可以修改实值,而不能修改 key。
优缺点和适用场景
优点:使用平衡二叉树实现,便于元素查找,且能把一个值映射成另一个值,可以创建字典。
缺点:每次插入值的时候,都需要调整红黑树,效率有一定影响。
适用场景:适用于需要存储一个数据字典,并要求方便地根据key找value的场景。
multimap 和 map 相同,但允许重复元素,也就是说 multimap 可包含多个键值(key)相同的元素。
std::map/std::set均为有序容器,这些元素内部通过红黑树进行实现, 插入和搜索的平均复杂度均为O(log(size))。在插入元素时候,会根据<操作符比较元素大小并判断元素是否相同, 并选择合适的位置插入到容器中。当对这个容器中的元素进行遍历时,输出结果会按照<操作符的顺序来逐个遍历。
而无序容器中的元素是不进行排序的,内部通过 Hash 表实现,插入和搜索元素的平均复杂度为 O(constant), 在不关心容器内部元素顺序时,能够获得显著的性能提升。
C++11 引入了两组无序容器:std::unordered_map/std::unordered_multimap 和 std::unordered_set/std::unordered_multiset。
它们的用法和原有的 std::map/std::multimap/std::set/set::multiset 基本类似。
4. tuple
了解过 Python 的程序员应该知道元组的概念,纵观传统 C++ 中的容器,除了std::pair外, 似乎没有现成的结构能够用来存放不同类型的数据(通常我们会自己定义结构)。 但std::pair的缺陷是显而易见的,只能保存两个元素。
关于元组的使用有三个核心的函数:
std::make_tuple: 构造元组std::get: 获得元组某个位置的值std::tie: 元组拆包
#include <tuple>
#include <iostream>
auto get_student(int id)
{
// 返回类型被推断为 std::tuple<double, char, std::string>
if (id 0)
return std::make_tuple(3.8, ‘A’, “张三”);
if (id 1)
return std::make_tuple(2.9, ‘C’, “李四”);
if (id == 2)
return std::make_tuple(1.7, ‘D’, “王五”);
return std::make_tuple(0.0, ‘D’, “null”);
// 如果只写 0 会出现推断错误, 编译失败
}
int main()
{
auto student = get_student(0);
std::cout << "ID: 0, "
<< "GPA: " << std::get<0>(student) << ", "
<< "成绩: " << std::get<1>(student) << ", "
<< "姓名: " << std::get<2>(student) << ‘\n’;
<span class="kt">double</span> <span class="n">gpa</span><span class="p">;</span>
<span class="kt">char</span> <span class="n">grade</span><span class="p">;</span>
<span class="n">std</span><span class="o">::</span><span class="n">string</span> <span class="n">name</span><span class="p">;</span>
<span class="c1">// 元组进行拆包
std::tie(gpa, grade, name) = get_student(1);
std::cout << "ID: 1, "
<< "GPA: " << gpa << ", "
<< "成绩: " << grade << ", "
<< "姓名: " << name << ‘\n’;
}
std::get 除了使用常量获取元组对象外,C++14 增加了使用类型来获取元组中的对象:
std::tuple<std::string, double, double, int> t(“123”, 4.5, 6.7, 8);
std::cout << std::get<std::string>(t) << std::endl;
std::cout << std::get<double>(t) << std::endl; // 非法, 引发编译期错误
std::cout << std::get<3>(t) << std::endl;
5. 容器配接器
除了以上基本容器类别,为满足特殊需求,STL还提供了一些特别的(并且预先定义好的)容器配接器,根据基本容器类别实现而成。包括:
1) stack
stack 容器对元素采取 LIFO(后进先出)的管理策略。
2) queue
queue 容器对元素采取 FIFO(先进先出)的管理策略。也就是说,它是个普通的缓冲区(buffer)。
3) priority_queue
priority_queue 容器中的元素可以拥有不同的优先权。所谓优先权,乃是基于程序员提供的排序准则(缺省使用 operators)而定义。Priority queue 的效果相当于这样一个 buffer:“下一元素永远是queue中优先级最高的元素”。如果同时有多个元素具备最髙优先权,则其次序无明确定义。
6. 算法
1) 简单查找算法,要求输入迭代器(input iterator)
// 返回一个迭代器,指向输入序列中第一个等于 val 的元素,未找到返回 end
find(beg, end, val);
// 返回一个迭代器,指向第一个满足 unaryPred 的元素,未找到返回 end
find_if(beg, end, unaryPred);
// 返回一个迭代器,指向第一个令 unaryPred 为 false 的元素,未找到返回 end
find_if_not(beg, end, unaryPred);
count(beg, end, val); // 返回一个计数器,指出 val 出现了多少次
count_if(beg, end, unaryPred); // 统计有多少个元素满足 unaryPred
// 返回一个 bool 值,判断是否所有元素都满足 unaryPred
all_of(beg, end, unaryPred);
// 返回一个 bool 值,判断是否任意(存在)一个元素满足 unaryPred
any_of(beg, end, unaryPred);
// 返回一个 bool 值,判断是否所有元素都不满足 unaryPred
none_of(beg, end, unaryPred);
2) 查找重复值的算法,传入向前迭代器(forward iterator)
// 返回指向第一对相邻重复元素的迭代器,无相邻元素则返回 end
adjacent_find(beg, end);
// 返回指向第一对相邻重复元素的迭代器,无相邻元素则返回 end
adjacent_find(beg, end, binaryPred);
// 返回一个迭代器,从此位置开始有 count 个相等元素,不存在则返回 end
search_n(beg, end, count, val);
// 返回一个迭代器,从此位置开始有 count 个相等元素,不存在则返回 end
search_n(beg, end, count, val, binaryPred);
3) 二分搜索算法,传入前向迭代器或随机访问迭代器(random-access iterator),要求序列中的元素已经是有序的
// 返回一个非递减序列 [beg, end) 中的第一个大于等于值 val 的位置的迭代器,不存在则返回 end
lower_bound(beg, end, val);
// 返回一个非递减序列 [beg, end) 中的第一个大于等于值 val 的位置的迭代器,不存在则返回 end
lower_bound(beg, end, val, comp);
// 返回一个非递减序列 [beg, end) 中第一个大于 val 的位置的迭代器,不存在则返回 end
upper_bound(beg, end, val);
// 返回一个非递减序列 [beg, end) 中第一个大于 val 的位置的迭代器,不存在则返回 end
upper_bound(beg, end, val, comp);
// 返回一个 pair,其 first 成员是 lower_bound 返回的迭代器,其 second 成员是 upper_bound 返回的迭代器
equal_range(beg, end, val);
// 返回一个 bool 值,指出序列中是否包含等于 val 的元素。对于两个值 x 和 y,当 x 不小于 y 且 y 也不小于 x 时,认为它们相等
binary_search(beg, end, val);
4) 排序算法,要求随机访问迭代器(random-access iterator)
sort(beg, end); // 排序整个范围
stable_sort(beg, end); // 排序整个范围(稳定排序)
sort(beg, end, comp); // 排序整个范围
stable_sort(beg, end, comp); // 排序整个范围(稳定排序)
// 返回一个 bool 值,指出整个输入序列是否有序
is_sorted(beg, end);
// 返回一个 bool 值,指出整个输入序列是否有序
is_sorted(beg, end, comp);
// 在输入序列中査找最长初始有序子序列,并返回子序列的尾后迭代器
is_sorted_until(beg, end);
// 在输入序列中査找最长初始有序子序列,并返回子序列的尾后迭代器
is_sorted_until(beg, end, comp);
// 排序 mid-beg 个元素。即,如果 mid-beg 等于 42,则此函数将值最小的 42 个元素有序放在序列前 42 个位置
partial_sort(beg, mid, end);
// 排序 mid-beg 个元素。即,如果 mid-beg 等于 42,则此函数将值最小的 42 个元素有序放在序列前 42 个位置
partial_sort(beg, mid, end, comp);
// 排序输入范围中的元素,并将足够多的已排序元素放到 destBeg 和 destEnd 所指示的序列中
partial_sort_copy(beg, end, destBeg, destEnd);
// 排序输入范围中的元素,并将足够多的已排序元素放到 destBeg 和 destEnd 所指示的序列中
partial_sort_copy(beg, end, destBeg, destEnd, comp);
// nth 是一个迭代器,指向输入序列中第 n 大的元素。nth 之前的元素都小于等于它,而之后的元素都大于等于它
nth_element(beg, nth, end);
// nth 是一个迭代器,指向输入序列中第 n 大的元素。nth 之前的元素都小于等于它,而之后的元素都大于等于它
nth_element(beg, nth, end, comp);
其他还有只读算法,使用输入迭代器的写算法,划分算法,使用前向迭代器的重排算法,使用双向迭代器的重排算法,使用随机访问迭代器的重排算法,最小值和最大值等,请参考:
唐唐:STL总结与常见面试题+资料
7. 总结
在实际使用过程中,到底选择这几种容器中的哪一个,应该根据遵循以下原则:
1、如果需要高效的随机存取,不在乎插入和删除的效率,使用 vector。
2、如果需要大量的插入和删除元素,不关心随机存取的效率,使用 list。
3、如果需要随机存取,并且关心两端数据的插入和删除效率,使用 deque。
4、如果打算存储数据字典,并且要求方便地根据 key 找到 value,一对一的情况使用 map,一对多的情况使用 multimap。
5、如果打算查找一个元素是否存在于某集合中,唯一存在的情况使用 set,不唯一存在的情况使用 multiset。
各容器的时间复杂度分析
- vector 在头部和中间位置插入和删除的时间复杂度为 O(N),在尾部插入和删除的时间复杂度为 O(1),查找的时间复杂度为 O(1);
- deque 在中间位置插入和删除的时间复杂度为 O(N),在头部和尾部插入和删除的时间复杂度为 O(1),查找的时间复杂度为 O(1);
- list 在任意位置插入和删除的时间复杂度都为 O(1),查找的时间复杂度为 O(N);
- set 和 map 都是通过红黑树实现,因此插入、删除和查找操作的时间复杂度都是 O(log N)。
各容器的共性
各容器一般来说都有下列函数:默认构造函数、复制构造函数、析构函数、empty()、max_size()、size()、operator=、operator<、operator<=、operator>、operator>=、operator==、operator!=、swap()。
顺序容器和关联容器都共有下列函数:
begin():返回容器第一个元素的迭代器指针;end():返回容器最后一个元素后面一位的迭代器指针;rbegin():返回一个逆向迭代器指针,指向容器最后一个元素;rend():返回一个逆向迭代器指针,指向容器首个元素前面一位;clear():删除容器中的所有的元素;erase(it):删除迭代器指针it处元素。















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









