







目录
综述:A review: Deep learning for medical image segmentation using multi-modality fusion
深度学习中的多模态融合技术是模型在分析和识别任务时处理不同形式数据的过程。
多模态融合技术主要包括模态表示,融合,转换,对齐技术。多模态融合技术的主要目标是缩小语义子空间中的分布差异,同时保持模态特定语义的完整性。
多模态融合架构分为联合架构,协同架构和编解码器架构。1)联合架构是将单模态表示投影到一个共享的语义子空间中,以便能够融合多模态特征 2)协同结构包括跨模态相似性模型和典型相关分析,其目标是寻找协调子空间中模态间的关联关系。
3)编解码器架构是将一个模态映射到另一个模态的多模态转换任务中
编解码器结构
这种结构主要由编码器和解码器两部分组成。编码器将源模态映射到向量V中,解码器基于向量V生成一个新的目标模态样本。
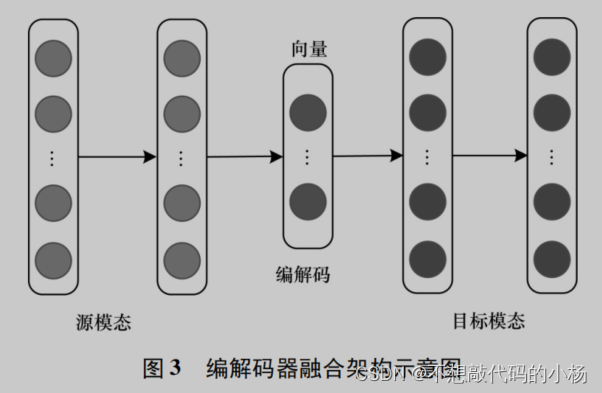
目前,编解码器结构重点关注的是共享语义捕获和多模序列的编解码问题,为有效捕获源模态和目标模态两种模态的共享语义。,主流的解决方案是通过一些正则化术语保持模态之间的语义一致性,需确保编码器能正确检测和编码信息,而解码器能推理高级语义和生成语法,以保证源模态中语义的正确理解和目标模态中新样本的生成。
多模态融合方法
多模态的融合方法分为模型无关的方法和基于模型的方法,前者不直接依赖于特定的深度学习方法,后者利用深度学习模型显式的解决多模态融合问题
模型无关的融合方法
模型无关的融合方法可以分为早期融合(基于特征),晚期融合(基于决策)和混合融合策略,早期融合在提取特征后立即集成特征,晚期融合在每种模态输出结果后才执行集成。混合融合结合早期融合方法和单模态预测器的输出。
当模态之间的相关性较大时晚期融合优于早期融合,当各个模态在很大程度上不相关时采用晚期融合的方法则更合适。混合融合策略在综合了二者的优点的同时也增加了模型的结构复杂度和训练难度。
综上,三种融合方法各有缺点,早期融合能比较好的捕获特征之间的关系,但容易过拟合。晚期融合能够较好的处理过拟合问题,但不允许分类器同时训练所有的数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









