







摘要
本文提出的是一种用于体积分割的Transformer架构,这个架构需要在编码局部和全局空间线索时保持复杂的平衡,并沿体积的所有轴保留信息。提出的编码器受益于同时编码局部和全局线索的自我注意机制,而解码器采用并行的自我和交叉注意力公式来捕捉精细细节以进行边界细化。
本文提出的网络称为VT-UNet。一些3D医学影像数据被划分为2D切片,并将2D切片作为输入。这种做法对于封装切片间的依赖关系至关重要的大量的潜在体积信息将被丢失。在基于UNet的架构中,本文提出了两种类型的Transformer块。
首先在编码器的块以分层方式直接作用于3D体积,以共同捕获局部和全局信息。其想法与Swin-Transformer相似。其次对于解码器我们在扩展路径中引入并行交叉注意和自我注意,这在来自解码器的q和来自编码器的k,v之间建立的桥梁。通过交叉注意和自我注意的并行化,本文的目标是在解码过程中保持完整的全局上下文,这对于分割任务很重要。由于VT UNet是纯Transformer没有卷积,并且在解码过程中组合了两个模块的注意力输出,因此序列的顺序对于获得准确的预测结果就非常重要。
方法
我们假设X={X1,X2,....Xr}是输入MRI的体积序列,我们称Xi为一个Token。本文认为原始形式的Token可能不适合定义跨度,因此我们在自注意力机制中,我们通过从输入Token学习线性映射来定义跨度。我们对本文的自注意力进行了如下的修改:
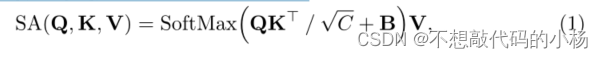
VTUNet网络的整体架构
下图显示了VTUNet网络的架构图
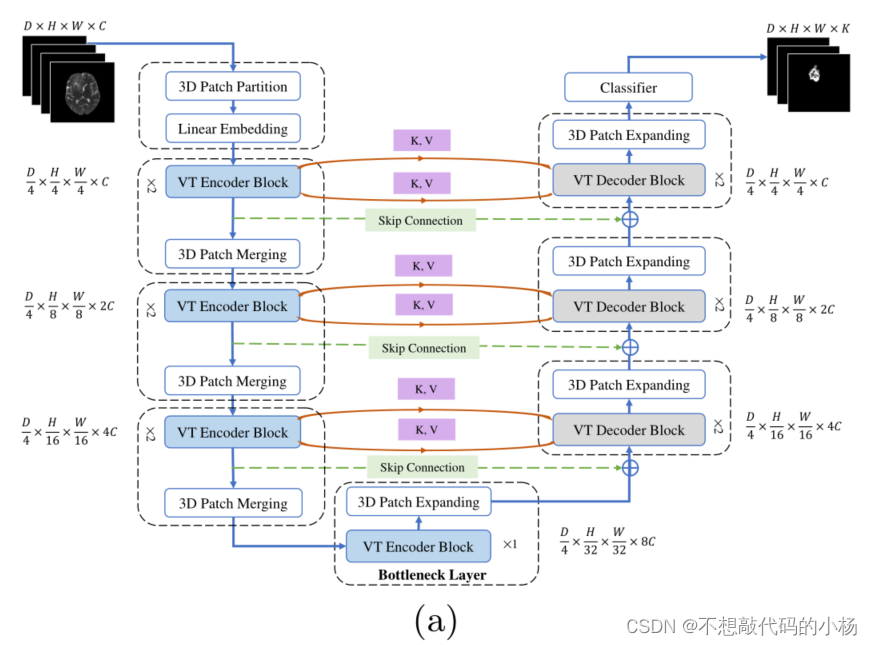
我们的输入是一个尺寸为D*H*W*C的3D体素,输出是D*H*W*K的3D体素,其中K表示分割得到的类的数量。
VTUNet的编码器
编码器部分由3D Patch Partitioning 层和Linear Embedding层和3D Pach merging层以及两个连续的VT编码器块组成。
3D Patch Partitioning
基于Transformer的模型使用一系列序列的Token,VTUnet的第一个块接受D*H*W*C维度的医学数据的3D输入。并将其分割为不重叠的3Dpatch并为其创建一组标记如下图所示
分区核的大小是P*M*M,因此用 ![]() 来表示Token。3D patch Partitioning之后是一个Linear embedding将维度为P*M*M的每个Token映射到一个C维向量。
来表示Token。3D patch Partitioning之后是一个Linear embedding将维度为P*M*M的每个Token映射到一个C维向量。
VT Encoder Block
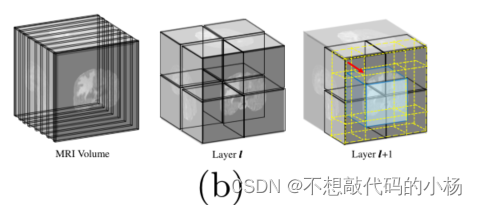
在VIT中,Token携带着重要的空间信息,在最近的研究中使用窗口来执行注意力机制已经得到了证明。我们在VT Encoder Block中也进行3D窗口操作,具体来说我们提出了两种类型的窗口即规则窗口和移位窗口。分别用VT-W-MSA和VT-SW-MSA来表示,细节如图B所示
VT-W-MSA和VT-SW-MSA都采用了带窗口的注意层,然后是中间带有高斯误差线性单元(GELU)非线性的2层多层感知器(MLP)。在每个MSA和MLP之前应用层归一化(LN),在每个模块之后应用残差连接。窗口使我们能够在建模令牌之间的长期依赖关系时注入归纳偏差。在VT-W-MSA和VT-SW-MSA中,在窗口内跨标记的注意有助于表示学习
在VT-W-MSA中,我们将体积均匀的分割为图(b)所示的较小的不重叠窗口。由于相邻窗口中的Token不能通过VT-W-MSA看到彼此,我们利用VT-SW-MSA中的移位窗口来桥接VT-W-MSA相邻窗口中的Token。整个过程用公式表示为
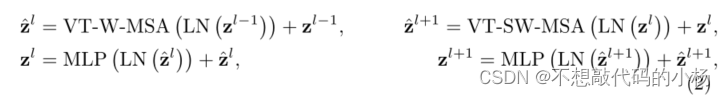
其中![]() 表示VT-W-MSA的输出以及MIP的输出特征。
表示VT-W-MSA的输出以及MIP的输出特征。
3D Patch Merging
在VT-UNet编码器中,我们利用3D Pacth merging合并生成特征层次结构。
在通过 VT-Enc-Blk之后,我们沿着空间轴以不重叠的方式合并相邻的Token,以产生新的Token。为此,我们首先将每组2*2的相邻Token的特征连接起来。得到的向量通过线性映射投影到维度翻倍的空间。
The VT Decoder
在经过VT-ENc-Blk和3D Patch Expanding层组成的Bottleneck层之后。VT解码器从连续的VIT解码器块,3D Patch Expanding层和最后的分类器生成最终的预测结果。
3D Patch Expanding
为了构造具有与输入相同空间分辨率的输出,我们需要在解码器中创建新的Token。为了便于讨论,考虑瓶颈层之后的Patch Expanding。
Patch Expanding之后的输入Token是维度是8C。在Patch Expanding中我们首先使用线性映射将输入Token的维度增加两倍。经过重塑以后,我们可以从维度为2*8C的结果向量中获得维度为4C的2*2Token。我们将沿着空间轴进行重塑。因此对于![]()
我们创建 ![]() 的Token。
的Token。
VT Decoder Block
每个VT-Dec-Blk从位于VT-UNet同一阶段的VT-Enc-Blk接收其前一个VT-Dec-Blk生成的Token即K值和V值。VT-Dec-Blk具有类似的窗口操作,但使用了分组为SA模块和交叉注意(CA)模块的四个SA块。功能可以描述为:
![]()
在这个式子中r和l表示解码器模块的左右分支,根据式子注意力机制的右分支作用于前一个VT-Dec-Blk生成的Token。我们强调通过其中的下标D从解码器发出的信息流。然而交叉注意力的左侧分支使用解码器生成的q以及从计算图中同级的VT-Enc-Blk获得的键和值。这里的思想是使用编码器跨越的键和值,以受益于编码器收集的空间信息,这些块也使用规则和移位的窗口,向模型注入更多的归纳偏差。
需要注意的是,来自具有相同窗口操作的SA的值和键需要合并,因此形成了图2(c)所示的交叉连接形式
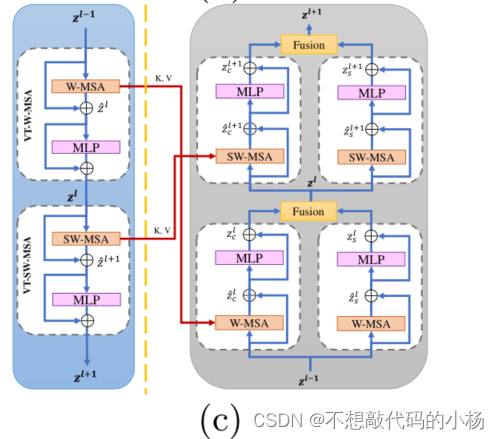
Fusion Module
融合模块如下图所示

将交叉注意力CA模块和MSA模块生成的Token组合在一起,并将其送入下一个VT-Dec-Blk,Zl通过的线性函数计算为:
![]()
其中F() 表示傅里叶特征位置编码,α控制着每个CA模块和MSA模块的权重。
Classifier Layer
在解码器的最后一个3D Patch expanding层之后,引入了一个分类器层,其中包含一个三维卷积层,用于将C维特征映射到K个分割类。
总结
本文提出了一种用于医学图像分割的Transformer,该网络在处理大尺寸3D体积时计算效率很高,并学习对人工制品具有鲁棒性的表示。
















 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









