







头文件
import numpy as np
import matplotlib.pyplot as plt
import mglearn
import pandas
from sklearn.model_selection import train_test_split
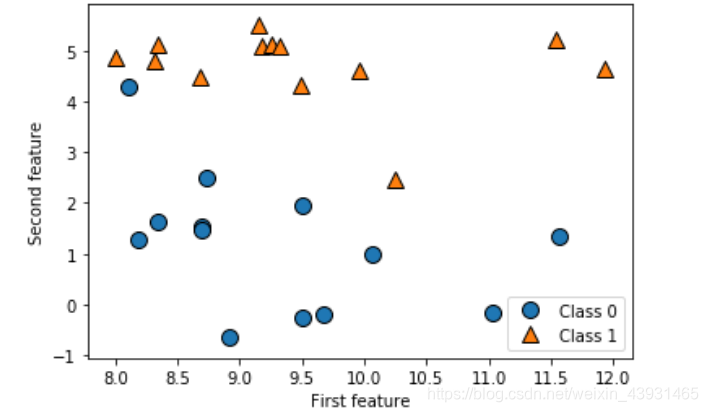
forge数据集
可以用于模拟二分类问题,数据集包含26个数据点和2个特征,两种输出。
from sklearn.model_selection import train_test_split
# 生成数据集
X, y = mglearn.datasets.make_forge() # 输入,目标
X_train, x_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 数据集绘图
mglearn.discrete_scatter(X[:, 0], X[:, 1], y) # 第一个特征为x轴,第二特征为y轴,不同的点是输出y
plt.legend(['Class 0', 'Class 1'], loc=4) # 给图像加图例(文字说明),loc参数指向图例位置
plt.xlabel('First feature')
plt.ylabel('Second feature')
print('X.shape:{}'.format(X.shape))
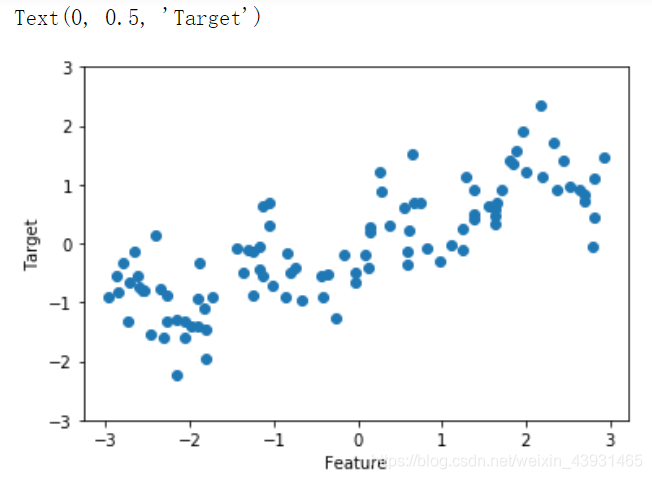
wave数据集
用来测试回归算法,数据集只有一个输入特征,一个连续的目标变量/响应。
x, y = mglearn.datasets.make_wave(n_samples=40)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
plt.plot(x, y, 'o') # 圆点表示
plt.ylim(-3, 3)
plt.xlabel('Feature')
plt.ylabel('Target')
cancer数据集
威斯康星州乳腺癌数据集,二分类问题,569个数据点,30个特征,两个目标(良性/恶性)
包含在scikit_learn中的数据集通常保存为Bunch对象。
Bunch对象类似字典,并且可以用点操作符来访问对象的值。bunch.ket = bunch['key']
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() # Bunch对象
x_train, x_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)
print('Cancer Keys:\n{}'.format(cancer.keys()))
print('Target:\n{}'.format({n: v for n, v in
zip(cancer.target_names, np.bincount(cancer.target))}))
np.bincount()=函数衡量权重(出现了多少次)
zip()函数将可迭代对象封装成列表,列表的元素为元组。
boston数据集
波士顿房价数据集,回归问题,506个数据点,13个特征。
普通bosten
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.data.shape)
含有交互项的bosten:13个特征两两组合成91个特征,共有104个特征
x, y = mglearn.datasets.load_extended_boston()
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
lr = LinearRegression().fit(x_train, y_train)
print(x.shape)
two-moons数据集
二分类数据集,想两个月亮一样(太极)
from sklearn.datasets import make_moons
# two_moons数据集
x, y = make_moons(n_samples=100, noise=0.25, random_state=3)
x_train, x_test, y_train, y_test = train_test_split(x, y, stratify=y, random_state=42)

















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









