







决策树
决策树是广泛运用于分类和回归任务的模型。它从一层层的if/else问题中进行学习,并得出结论。
构造决策树
scilit-learn在DecisionTreeRegressor类和DecisionTreeClassifier类中实现决策树。
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=0).fit(x_train, y_train)
二叉树:根节点是问题(测试)【特征i的值是否大于a】,叶节点是分类结果。
学习决策树,就是学习一系列if/else问题,一分二,二分四…对数据进行反复递归划分,直到划分后的每个区域(叶结点)只包含单一目标值(属于同一类或者单一回归值),称叶结点为纯的。
由于每个测试只关注一个特征,所以划分后的区域边界始终与坐标轴平行。
对新数据点进行预测,就从根节点开始遍历一遍找到对应区域。
回归问题的这一数据点输出为此叶结点中所有训练点的平均目标值。
控制决策树的复杂度
若所有叶结点都是纯的,模型过于复杂,训练集拟合度过高,出现过拟合。
两种方法防治过拟合:
- 预剪枝:限制树的生长到某一次停止。限制树的最大深度、叶结点的最大数目…
- 后剪枝:生成纯树以后把信息少的结点删掉。
scikit-learn中预剪枝在cancer数据集
scikit-learn中没有实现后剪枝。
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
cancer = load_breast_cancer()
x_train, x_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=42)
tree = DecisionTreeClassifier(random_state=0).fit(x_train, y_train)
# 纯决策树
print(tree.score(x_train, y_train)) # 1.0
print(tree.score(x_test, y_test)) # 0.9370629370629371
# 限制树的深度
tree2 = DecisionTreeClassifier(max_depth=4, random_state=0).fit(x_train, y_train)
print(tree2.score(x_train, y_train)) # 0.9882629107981221
print(tree2.score(x_test, y_test)) # 0.951048951048951
max_depth参数限制树的深度
可视化:分析决策树
import graphviz
from sklearn.tree import export_graphviz
export_graphviz(tree, out_file='tree.dot', class_names=['malignant', 'begin'],
feature_names=cancer.feature_names, impurity=False, filled=True)
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)

tree模块的export_graphviz函数可生成一个.dot格式文件(用于保存图形的文本文件格式)。
graphviz模块可以将.dot文件可视化。
树的特征重要性
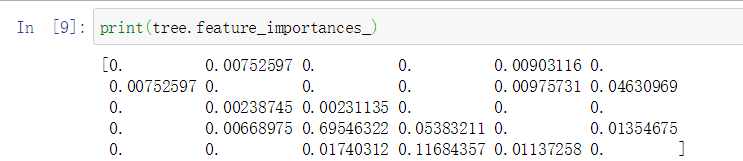
feature_importances_属性,特征重要性为每个特征对树的决策的重要性进行排序,0(根本没用到)-1(完美预测目标值),始终为正数。
特征重要性可视化:柱状图
# s树的特征重要性可视化
def plot_feature_importances_cancer(model):
n_features = cancer.data.shape[1]
plt.barh(range(n_features),model.feature_importances_,align = 'center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plot_feature_importances_cancer(tree)
plt.barh函数:生成柱状图。
align参数:水平对齐,valign参数:垂直对齐。center/left/right
plt.yticks函数:设置y轴标签

回归决策树:DecisionTreeRegressor
回归的决策树大致都和分类的决策树类似。
但回归决策树不能外推(不能在训练数据范围以外进行预测),所有基于树的模型都有这个缺点。
在用决策树进行回归预测价格时,可以对价格取对数,是的线性相对性更好,对DecisionTreeRegressor没什么影响。但是对线性模型的回归有很大影响。
plt.semilogy(x,y)函数使用y轴的对数绘制图像。
参数
控制决策树模型复杂度的参数是预剪枝参数,用以防止过拟合。max_depth、max_leaf_nodes、min_samplies_leaf
优缺点
优:得到的模型容易可视化;算法不受数据缩放的影响(不需要特征预处理)
缺:即使做了预剪枝,仍然会过拟合,泛化性能差















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









