







前言:本文为原创 若有错误欢迎评论!
描述部分
什么是BP神经网络
这个百度比较多就不赘述了 在看到我的文章前一定也看了不少了!
开篇先说几点
- 本文参考了博客"https://blog.csdn.net/ironyoung/article/details/49455343",对其补充与拓展
- 本文努力去通俗的阐述bp神经网络原理 与结合实际bp网络图重构其代码 尤其核心算法部分 让bp算法使用更清晰明了 并且下面贴的代码注释非常全 也给出了用的哪个具体计算公式 很容易看懂
执行流程
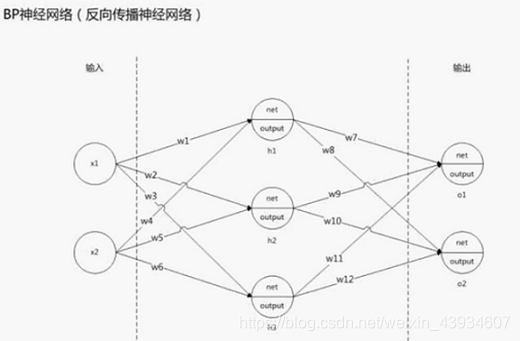
正向:

反向:
![[外链图片转存失败(img-TK28JXKn-1566937228531)(en-resource://database/1288:1)]](https://i-blog.csdnimg.cn/blog_migrate/2bf9047ad37e1b022315454be06b2669.png)
算法原理
误差
![[外链图片转存失败(img-uk0V5onh-1566937228531)(en-resource://database/1437:1)]](https://i-blog.csdnimg.cn/blog_migrate/06deaf32a8dcc0e8cc852a0ada3c6dd9.png)
“d”:输出值的正确结果
“o”:实际输出值
“k”:输出节点的个数(因为如果输出层节点不止一个时 就把多个节点的误差相加)
![[外链图片转存失败(img-OfVTK3Ig-1566937228532)(en-resource://database/1439:1)]](https://i-blog.csdnimg.cn/blog_migrate/c6ffa1564438bb8cdeacf628940fcfff.png)
- 该式子是输出层误差的进一步分解
“f(netk)”:是把输出层误差的"o"替换掉
“f(x)”:指激活函数 本文用的"sigmoid"函数(激活函数通常不是自定 有固定的函数去选择)
“netk”:输入层从隐藏层取到 并且还没有经过激活函数的值
- 第二个式子使把"netk"又进一步分解 用隐藏层的值来表示
“j”:隐藏层节点数(本文用的单层隐藏层)
“w”:隐藏层第j个节点对输出层第k个节点的加权
“y”:第j个隐藏层节点的值(该值是已经经过了激活函数的值)
综上:输出层一个节点未经过激活函数的值"netk" 就等于(隐藏层每个节点的值 都乘其对输出层那个对应节点的加权)的和
![[外链图片转存失败(img-pROmpG30-1566937228533)(en-resource://database/1435:1)]](https://i-blog.csdnimg.cn/blog_migrate/1b2b9fa93543caeae3869fa33076c39d.png)
- 该式子又是对隐藏层误差第二个式子的分解
“f(netj)”:是把“yj"替换掉了("yj"指的隐藏层节点的值) 换成输入层的值来表示
“i”:输入层的节点数
“v”:输入层第i个节点对隐藏层第j个节点的加权
“x”:输入层第i个节点输入的值
综上:隐藏层一个节点未经过激活函数的值"netk" 就等于(输入层每个节点输入的值 都乘其对隐藏层那个对应节点的加权)的和
总结:
- 实际上每次往前一层都是分解该层未经过激活函数的值 把该值用:(上一层每个节点的值*每个节点对该节点的加权)的和来替换 不断向前扩大 用前一层来替换
- 同时可以看到我们可以改变加权“w”、“v"来减小误差
bp神经网络是如何减小误差的
一.修改加权
1.如何修改隐藏层加权
修改的表达式
![[外链图片转存失败(img-cZdonQYJ-1566937228534)(en-resource://database/1463:1)]](https://i-blog.csdnimg.cn/blog_migrate/18dbdbee5e337b38789c1cce09313782.png)
链式原则
![[外链图片转存失败(img-JeG5NVlJ-1566937228535)(en-resource://database/1393:1)]](https://i-blog.csdnimg.cn/blog_migrate/1852188def1b2dd0d40232d1dd0cf8bb.png)
“w7”:一个隐藏层的一个加权
“net”:输出层从隐藏层取到未经过加权的值
“out”:经过加权函数后的值
“Eo1”:o1节点的误差
“Etotal”:所有节点最终的误差和
-
根据上面的链式原则可以把式子变为
![[外链图片转存失败(img-6SW53z75-1566937228538)(en-resource://database/1367:1)]](https://i-blog.csdnimg.cn/blog_migrate/f5752f648d4e0770a369567593eaf499.png)
-
这就相当于
![[外链图片转存失败(img-uqHdHe51-1566937228538)(en-resource://database/1375:1)]](https://i-blog.csdnimg.cn/blog_migrate/da7e8706c79a2f9f1c61a4c3624f4ad0.png)
分别计算每个偏导
第一个偏导
-
因为:
![[外链图片转存失败(img-VM7lwo2H-1566937228539)(en-resource://database/1397:1)]](https://i-blog.csdnimg.cn/blog_migrate/f0931a0d509753673802c303be8de837.png)
![[外链图片转存失败(img-3dfb1uPy-1566937228540)(en-resource://database/1403:1)]](https://i-blog.csdnimg.cn/blog_migrate/46116ccecb9d27c6fa8157c4be4fa66c.png)
![[外链图片转存失败(img-2uM1o9Kb-1566937228541)(en-resource://database/1405:1)]](https://i-blog.csdnimg.cn/blog_migrate/e6fa95b7d4937d6eacc5fc4afc5deb1a.png)
-
相当于除了E(t1) 有"o1"其他都没有 所以都被看作常数了(即:用E(t1)对out(o1)求导得该结果)
![[外链图片转存失败(img-JOv1Ljeg-1566937228541)(en-resource://database/1457:1)]](https://i-blog.csdnimg.cn/blog_migrate/91aa11c24f03ca7db7d4cefa664753ee.png)
target指的是正确结果的值*
第二个偏导
- 该偏导就相当于对激活函数sigmoid得偏导 所有使用sigmoid激活函数的 out对net的求导都是该值
![[外链图片转存失败(img-2Lu9Yipi-1566937228542)(en-resource://database/1445:1)]](https://i-blog.csdnimg.cn/blog_migrate/25f36856a11bc0e134a9761e993baf5a.png)
第三个偏导
![[外链图片转存失败(img-vfvqKQa6-1566937228543)(en-resource://database/1409:1)]](https://i-blog.csdnimg.cn/blog_migrate/e8cf3b59af0676e469b04b9f08e4a39d.png)
![[外链图片转存失败(img-dLR1nUAD-1566937228543)(en-resource://database/1449:1)]](https://i-blog.csdnimg.cn/blog_migrate/04befd3696bfb666a95b23a1b370d13a.png)
综上所得各个偏导的乘积
![[外链图片转存失败(img-0MBNhMsN-1566937228544)(en-resource://database/1339:1)]](https://i-blog.csdnimg.cn/blog_migrate/f1e7c1625ae7ca2eb6ed5a1fa2912d4a.png)
2.如何修改输入层加权
修改的表达式
![[外链图片转存失败(img-hqu45bT3-1566937228545)(en-resource://database/1453:1)]](https://i-blog.csdnimg.cn/blog_migrate/cb6bfac708e43da618ef70c4dc4cc0c3.png)
链式原则
![[外链图片转存失败(img-nqICtA4j-1566937228545)(en-resource://database/1389:1)]](https://i-blog.csdnimg.cn/blog_migrate/63ea21e7c7c3a13c38629119878528a7.png)
“w1”:输入层加权
“neth1”:隐藏层获取输入层 且没经过激活函数的值
“outh1”:经过激活函数的值
“neto1”:输出层没加权的值
“outo1”:输出层经过加权的值 也是最终输出结果
“Eo1”:o1节点得误差
o2同理…
- 可以看出输出层的加权影响的输出节点不止一个
- 根据上面的链 写出下面表达式
![[外链图片转存失败(img-n7q4NzBl-1566937228546)(en-resource://database/1431:1)]](https://i-blog.csdnimg.cn/blog_migrate/749a3edee4b96a14072c74ae1782efb0.png)
"outh1"为分叉处 所以用"Etotal"对"outh1"的偏导表示其之后所有的影响
下面又把对"outh1"的偏导进行拆分 分成两路
![[外链图片转存失败(img-Y0t4dKVF-1566937228547)(en-resource://database/1433:1)]](https://i-blog.csdnimg.cn/blog_migrate/739a1550de8db53101e697985f31d727.png)
- 所以每次计算输入层偏导时要分成两部分来算
二.修改偏移
- 上面的bp图没有画偏移 这又找了一个
![[外链图片转存失败(img-fgmnE2t0-1566937228547)(en-resource://database/1335:1)]](https://i-blog.csdnimg.cn/blog_migrate/d62a365778becc11cd2b403af9f5cb5e.png)
b1和b2指的是偏移(即:在加到下一层的时候 加权永远都是+1 但自己的值是改变的)
- 用o1的值举例偏移怎莫用
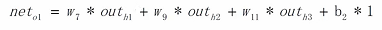
注意:b1的值对o1、o2是不同的值 一个节点有一个自己偏移值(输入层的节点都没有偏移值) 最后再加上该值就是未经过激活函数的net值 - 要修改偏移的话同理 用链式先画出影响的链 再一步一步偏导(下面的代码中有实现和讲解)
其他减小误差的方法就不赘述了 欢迎大佬补充
代码实现
一.神经网络图
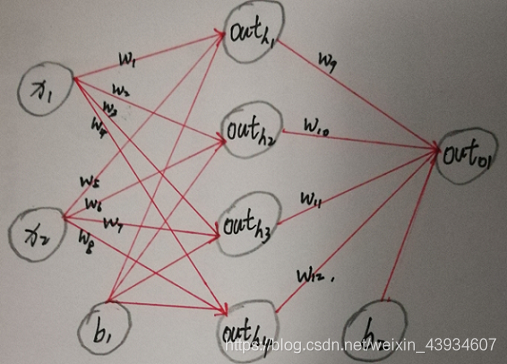
这个图就是我们一会儿要解决xor问题的神经网络图:
两个输入节点、一层隐藏层,且4个节点、一个输出节点
注意:
- 图中b1和b2指的是偏移 每个节点只有一个该值 用于从上一层获取到值之后加上该值
所以隐藏层每个节点都有其不同偏移b1、输出层每个节点也有其不同的偏移b2(输入层节点都没有偏移)- net和out的区别是 net没经过激活函数但是已经加了偏移 out是net经过激活函数后的值
图中写成out形式 代表该节点的最终输出值
二.怎莫计算误差
![[外链图片转存失败(img-kT3CO7OK-1566937228549)(en-resource://database/1539:1)]](https://i-blog.csdnimg.cn/blog_migrate/d859705da2d5a91f234e4b75e62e84df.png)
因为我们要用代码实现的神经网络图只有一个输出节点 所以这里的Etotal就是那一个输出节点的误差
三.怎莫计算改变量
怎莫计算反向传递时输出节点偏移的改变量

1)依然用上面说的链式的原则 一直进行偏导 就得到上面的结果
2)最后"*1"是因为"neto1"对"b2"的偏导时 因为b2是偏移量 直接相加 所以偏移量对下一层的加权是1
怎莫计算反向传递时隐藏层节点加权的改变量
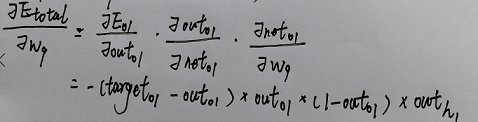
这里以w9进行举例 其他加权做法相同
怎莫计算反向传递时隐藏层节点偏移的改变量
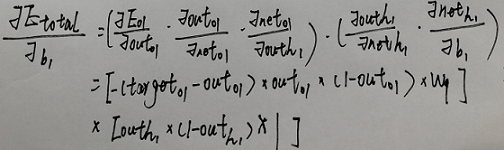
- 这里之所以用两个括号括起来 因为虽然咱们实现的bp网络只有一个输出节点 但是咱们在代码要遍历输出层的节点 遍历的时候咱们并不知道有多少个输出节点 所以用括号括起来
- 如果输出有多个节点 参照上面的"如何订正输入层加权" 把第一个括号里的式子进行拓展
- 最后对b1偏导的结果是1的道理跟上面相同
怎莫计算反向传递时输入层节点加权的改变量
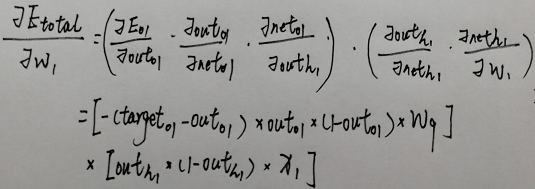
- 这里用w1进行举例 其他加权求变化量原理相同
- 用括号括起来也是因为代码中遍历输出节点时不知道节点个数 第一个式子会变成多个节点情况的和 但实际只有一个
- 通过上面可以看到,输出层节点偏移量的改变值和隐藏层加权的改变值只是最后一个偏导不同,隐藏层节点的偏移量和输入层节点加权的该变量也只是最后一个偏导的值不同
四.有了变化量到底怎样更新该值
![[外链图片转存失败(img-m1PLAwk7-1566937228553)(en-resource://database/1551:1)]](https://i-blog.csdnimg.cn/blog_migrate/7fe79408c0cee09654a03a0926f8e336.png)
偏移更新的表达式同理
五.写代码前注意事项
- 在正向传播获取值时:在遍历当前层节点时 遍历上一层节点(从隐藏层开始)
- 在反向传播获修改加权时:在遍历当前层节点时 遍历下一层节点 找到对应的加权
"bpnet"头文件
#ifndef BPNET_H
#define BPNET_H
#include <iostream>
#include <cmath>
#include <vector>
#include <cstdlib>
#include <ctime>
#define INNODE 2 // 输入结点数
#define HIDENODE 4 // 隐含结点数
#define OUTNODE 1 // 输出结点数
#define LEARNINGRATE 0.9 // 学习速率(注意:越高虽然越快 也容易误差较大)
/**
* 输入层节点
*/
typedef struct inputNode{
double value; // 输入值
std::vector<double> weight // 输入层单个节点对下一层每个节点的加权值
, wDeltaSum; // 单个加权的不同样本和
}InputNode;
/**
* 输出层节点
*/
typedef struct outputNode{
double o_value // 节点最终值 经过偏移与激活函数后的值
, rightout // 正确输出值
, bias // 偏移量 每个节点只有一个
, bDeltaSum; // 反向传播时 经过计算后的偏移量需要改变的值 因为有多个样本所以是sum
}OutputNode;
/**
* 隐含层节点
*/
typedef struct hiddenNode{
double o_value // 节点最终值 经过偏移与激活函数后的值
, bias // 偏移量 每个节点只有一个
, bDeltaSum; // 反向传播时 经过计算后的偏移量需要改变的值 因为有多个样本所以是sum
std::vector<double> weight // 隐藏层单个节点对下一层每个节点的加权值
, wDeltaSum; // 单个加权的不同样本和
}HiddenNode;
/**
* 单个样本
*/
typedef struct sample{
std::vector<double> in // 输入层value的迭代器 里面的数据有输入层节点数个(输入层每个节点的value值 代表一份样本数据中 一个输入属性的值)
, out; // 输出层rightout的迭代器 里面的数据也有输出层层节点数个(输出层每个节点的rightout值 代表一份样本数据 应该输出属性的正确值)
}Sample;
/**
* BP神经网络
*/
class BpNet{
public:
BpNet(); // 构造函数 用来初始化加权和偏移
void fp(); // 单个样本前向传播
void bp(); // 单个样本后向传播
void doTraining(std::vector<Sample> sampleGroup, double threshold,int mostTimes); // 训练(更新 weight, bias)
void afterTrainTest(std::vector<Sample>& testGroup); // 神经网络学习后进行预测
void setInValue (std::vector<double> inValue); // 设置学习样本输入
void setOutRightValue(std::vector<double> outRightValue); // 设置学习样本输出
public://设置成public就不用get、set麻烦
double error; //误差率
InputNode* inputLayer[INNODE]; // 输入层(任何模型都只有一层)
OutputNode* outputLayer[OUTNODE]; // 输出层(任何模型都只有一层)
HiddenNode* hiddenLayer[HIDENODE]; // 隐含层(我们这个只有一个隐藏层所以一维数组 但如果有多层是二维数组)
};
#endif // BPNET_H
"bpnet"实现类
#include "BpNet.h"
using namespace std;
/**
* 产生-1~1的随机数
*/
inline double getRandom() {
return ((2.0*(double)rand()/RAND_MAX) - 1);
}
/**
* sigmoid 函数(激活函数 要保证单调 且只有一个变量)
*/
inline double sigmoid(double x){
// 一般bp用作分类的话都用该函数
double ans = 1 / (1+exp(-x));
return ans;
}
/**
* 初始化(给加权或者偏移赋初值)
*/
BpNet::BpNet(){
srand((unsigned)time(NULL));
// error初始值,只要能保证大于阀值进入训练就可以
error = 100.f;
/*
* 初始化输入层每个节点对下一层每个节点的加权
*/
for (int i = 0; i < INNODE; i++){
inputLayer[i] = new InputNode();
for (int j = 0; j < HIDENODE; j++){
inputLayer[i]->weight.push_back(getRandom());
inputLayer[i]->wDeltaSum.push_back(0.f);
}
}
/*
* 初始化隐藏层每个节点对下一层每个节点的加权
* 初始化隐藏层每个节点的偏移
*/
for (int i = 0; i < HIDENODE; i++){
hiddenLayer[i] = new HiddenNode();
hiddenLayer[i]->bias = getRandom();
// 初始化加权
for (int j = 0; j < OUTNODE; j++){
hiddenLayer[i]->weight.push_back(getRandom());
hiddenLayer[i]->wDeltaSum.push_back(0.f);
}
}
/*
* 初始化输出层每个节点的偏移
*/
for (int i = 0; i < OUTNODE; i++){
outputLayer[i] = new OutputNode();
outputLayer[i]->bias = getRandom();
}
}
/**
* 正向传播 获取一个样本从输入到输出的结果
*/
void BpNet::fp(){
/*
* 隐藏层向输入层获取数据
*/
// 遍历隐藏层节点
for (int i = 0; i < HIDENODE; i++){
double sum = 0.f;
// 遍历输入层每个节点
for (int j = 0; j < INNODE; j++){
sum += inputLayer[j]->value * inputLayer[j]->weight[i];
}
// 增加偏移
sum += hiddenLayer[i]->bias;
// 调用激活函数 设置o_value
hiddenLayer[i]->o_value = sigmoid(sum);
}
/*
* 输出层向隐藏层获取数据
*/
// 遍历输出层节点
for (int i = 0; i < OUTNODE; i++){
double sum = 0.f;
// 遍历隐藏层节点
for (int j = 0; j < HIDENODE; j++){
sum += hiddenLayer[j]->o_value * hiddenLayer[j]->weight[i];
}
sum += outputLayer[i]->bias;
outputLayer[i]->o_value = sigmoid(sum);
}
}
/**
* 反向传播 从输出层再反向
*
* 该方法目的是返回:多个样本加权应该变化值的和【wDeltaSum】、多个样本偏移应该变化值的和【bDeltaSum】
* 在训练时根据样本数变化值的求平均值 用该平均值修改加权、偏移
*
*/
void BpNet::bp(){
/*
* 求误差值error
*/
for (int i = 0; i < OUTNODE; i++){
double tmpe = fabs(outputLayer[i]->o_value - outputLayer[i]->rightout);
// 计算误差 参照上面第一个公式
error += tmpe * tmpe / 2;
}
/*
* 求输出层偏移的变化值
*/
for(int i = 0; i < OUTNODE ; i++){
// 偏移应该变化的值 参照b2公式
double bDelta=(-1) * (outputLayer[i]->rightout - outputLayer[i]->o_value) * outputLayer[i]->o_value * (1 - outputLayer[i]->o_value);
outputLayer[i]->bDeltaSum += bDelta;
}
/*
* 求对输出层加权的变化值
*/
for (int i = 0; i < HIDENODE; i++){
for(int j = 0;j < OUTNODE;j++){
// 加权应该变化的值 参照w9公式
double wDelta=(-1) * (outputLayer[j]->rightout - outputLayer[j]->o_value) * outputLayer[j]->o_value * (1 - outputLayer[j]->o_value) * hiddenLayer[i]->o_value;
hiddenLayer[i]->wDeltaSum[j] += wDelta;
}
}
/*
* 求隐藏层偏移
*/
for(int i = 0; i < HIDENODE; i++){
double sum=0; // 因为是遍历输出层节点 不可以确定有多少个输出节点 参照b1公式的第一个公因式
for(int j = 0;j < OUTNODE; j++){
sum += (-1) * (outputLayer[j]->rightout - outputLayer[j]->o_value) * outputLayer[j]->o_value * (1 - outputLayer[j]->o_value) * hiddenLayer[i]->weight[j];
}
// 参照公式b1
hiddenLayer[i]->bDeltaSum += (sum * hiddenLayer[i]->o_value * (1 - hiddenLayer[i]->o_value));
}
/*
* 求输入层对隐藏层的加权变化
*/
for(int i = 0; i < INNODE; i++){
// 从公式b1和w1可以看出 两个公式是有公因式 所以这部分代码相同
double sum = 0;
for(int j = 0;j < HIDENODE; j++){
for(int k = 0; k < OUTNODE; k++){
sum += (-1) * (outputLayer[k]->rightout - outputLayer[k]->o_value) * outputLayer[k]->o_value * (1 - outputLayer[k]->o_value) * hiddenLayer[j]->weight[k];
}
// 参照公式w1
inputLayer[i]->wDeltaSum[j] += (sum * hiddenLayer[j]->o_value * (1 - hiddenLayer[j]->o_value) * inputLayer[i]->value);
}
}
}
/**
* 进行训练 参照上面最后修改的公式
*/
void BpNet::doTraining(vector<Sample> sampleGroup, double threshold, int mostTimes){
int sampleNum = sampleGroup.size();
int trainTimes = 0;
bool isSuccess = true;
while(error >= threshold){
// 判断是否超过最大训练次数
if(trainTimes >mostTimes){
isSuccess = false;
break;
}
cout<<"训练次数:"<<trainTimes++<<"\t\t"<<"当前误差: " << error << endl;
error = 0.f;
// 初始化输入层加权的delta和
for (int i = 0; i < INNODE; i++){
inputLayer[i]->wDeltaSum.assign(inputLayer[i]->wDeltaSum.size(), 0.f);
}
// 初始化隐藏层加权和偏移的delta和
for (int i = 0; i < HIDENODE; i++){
hiddenLayer[i]->wDeltaSum.assign(hiddenLayer[i]->wDeltaSum.size(), 0.f);
hiddenLayer[i]->bDeltaSum = 0.f;
}
// 初始化输出层的偏移和
for (int i = 0; i < OUTNODE; i++){
outputLayer[i]->bDeltaSum = 0.f;
}
// 完成所有样本的调用与反馈
for (int iter = 0; iter < sampleNum; iter++){
setInValue(sampleGroup[iter].in);
setOutRightValue(sampleGroup[iter].out);
fp();
bp();
}
// 修改输入层的加权
for (int i = 0; i < INNODE; i++){
for (int j = 0; j < HIDENODE; j++){
//每一个加权的和都是所有样本累积的 所以要除以样本数
inputLayer[i]->weight[j] -= LEARNINGRATE * inputLayer[i]->wDeltaSum[j] / sampleNum;
}
}
// 修改隐藏层的加权和偏移
for (int i = 0; i < HIDENODE; i++){
// 修改每个节点的偏移 因为一个节点就一个偏移 所以不用在节点里再遍历
hiddenLayer[i]->bias -= LEARNINGRATE * hiddenLayer[i]->bDeltaSum / sampleNum;
// 修改每个节点的各个加权的值
for (int j = 0; j < OUTNODE; j++){
hiddenLayer[i]->weight[j] -= LEARNINGRATE * hiddenLayer[i]->wDeltaSum[j] / sampleNum;
}
}
//修改输出层的偏移
for (int i = 0; i < OUTNODE; i++){
outputLayer[i]->bias -= LEARNINGRATE * outputLayer[i]->bDeltaSum / sampleNum;
}
}
if(isSuccess){
cout << endl << "训练成功!!!" << "\t\t"<<"最终误差: " << error << endl << endl;
}else{
cout << endl <<"训练失败! 超过最大次数!" << "\t\t"<<"最终误差: " << error << endl << endl;
}
}
/**
* 训练后进行测试使用
*/
void BpNet::afterTrainTest(vector<Sample>& testGroup){
int testNum = testGroup.size();
for (int iter = 0; iter < testNum; iter++){
// 把样本输出清空
testGroup[iter].out.clear();
setInValue(testGroup[iter].in);
// 从隐藏层从输入层获取数据
for (int i = 0; i < HIDENODE; i++){
double sum = 0.f;
for (int j = 0; j < INNODE; j++){
sum += inputLayer[j]->value * inputLayer[j]->weight[i];
}
sum += hiddenLayer[i]->bias;
hiddenLayer[i]->o_value = sigmoid(sum);
}
// 输出层从隐藏层获取数据
for (int i = 0; i < OUTNODE; i++){
double sum = 0.f;
for (int j = 0; j < HIDENODE; j++){
sum += hiddenLayer[j]->o_value * hiddenLayer[j]->weight[i];
}
sum += outputLayer[i]->bias;
outputLayer[i]->o_value = sigmoid(sum);
// 设置输出的值
testGroup[iter].out.push_back(outputLayer[i]->o_value);
}
}
}
/**
* 给输入层每个节点设置输入值 每个样本进行训练时都要调用
*/
void BpNet::setInValue(vector<double> sampleIn){
// 对应一次样本 输入层每个节点的输入值
for (int i = 0; i < INNODE; i++){
inputLayer[i]->value = sampleIn[i];
}
}
/**
* 给输出层每个节点设置正确值 每个样本进行训练时都要调用
*/
void BpNet::setOutRightValue(vector<double> sampleOut){
// 对应一次样本 输出层层每个节点的正确值
for (int i = 0; i < OUTNODE; i++){
outputLayer[i]->rightout = sampleOut[i];
}
}
"util.h"工具类
#ifndef UTIL_H
#define UTIL_H
#include <vector>
/**
* 工具类
*/
class Util
{
public:
// 获得txt文件中准备的数据
std::vector<double> getFileData(char* fileName);
};
#endif // UTIL_H
"util.cpp"实现类
#include "Util.h"
#include <string>
#include <cstring>
#include <cstdlib>
#include <fstream>
#include <vector>
using namespace std;
vector<double> Util::getFileData(char* fileName){
vector<double> res;
ifstream input(fileName);
if(!input){
return res;
}
string buff;
while(getline(input,buff)){
char* datas = (char*)buff.c_str();
const char* spilt = " ";
// strtok字符串拆分函数
char* data = strtok(datas,spilt);
while(data != NULL){
// atof是stdlib头文件下转化字符串为数字的函数
res.push_back(atof(data));
// NULL代表从上次没拆分完地方继续拆
data = strtok(NULL,spilt);
}
}
input.close();
return res;
}
"main.cpp"训练及测试
#include "BpNet.h"
#include "Util.h"
using namespace std;
void getInput(double& threshold,int& mostTimes); // 获得输入的阀值和误差大小
vector<Sample> getTrianData(); // 从文件获取训练数据 没获取到直接退出
vector<Sample> getTestData(); // 从文件获取测试数据 没获取到直接退出
void showTest(vector<Sample>testGroup); // 输出测试数据的结果
int main(){
// 准备所有数据
BpNet bpNet;
vector<Sample> sampleGroup = getTrianData();
vector<Sample> testGroup = getTestData();
double threshold; // 设定的阀值
int mostTimes; // 最大训练次数
// 获取输入 并提示数据已经录入
getInput(threshold,mostTimes);
// 进行训练
bpNet.doTraining(sampleGroup,threshold,mostTimes);
// 训练后测试录入的数据 这里的参数是引用
bpNet.afterTrainTest(testGroup);
// 打印提前录入数据的测试结果
showTest(testGroup);
return 0;
}
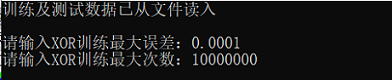
void getInput(double& threshold , int& mostTimes){
cout << "训练及测试数据已从文件读入" << endl<<endl;
cout << "请输入XOR训练最大误差:"; //0.0001最好
cin >> threshold;
cout << "请输入XOR训练最大次数:";
cin >> mostTimes;
}
void showTest(vector<Sample> testGroup){
// 输出测试结果
cout << "系统测试数据:" << endl;
for (int i = 0 ; i < testGroup.size() ; i++){
for (int j = 0 ; j<testGroup[i].in.size() ; j++){
cout << testGroup[i].in[j] << "\t";
}
cout << "-- XOR训练结果 :";
for (int j=0;j<testGroup[i].out.size();j++){
cout << testGroup[i].out[j] << "\t";
}
cout << endl;
}
cout << endl << endl;
system("pause");
}
vector<Sample> getTestData(){
Util util;
vector<double> testData = util.getFileData("test.txt");
if(testData.size() == 0){
cout << "载入测试数据失败!" << endl;
exit(0);
}
int groups = testData.size()/2;
// 创建测试数据
Sample testInOut[groups];
for (int i = 0,index=0; i < groups; i++){
for(int j=0;j<2;j++){
testInOut[i].in.push_back(testData[index++]);
}
}
// 初始化数据
return vector<Sample>(testInOut,testInOut+groups);
}
vector<Sample> getTrianData(){
Util util;
vector<double> trainData = util.getFileData("data.txt");
if(trainData.size() == 0){
cout << "载入训练数据失败!" << endl;
exit(0);
}
int groups = trainData.size()/3;
// 创建样本数据
Sample trainInOut[groups];
// 把vector设置给样本Sample
for (int i = 0,index=0; i < groups; i++){
for(int j=0;j<3;j++){
if(j%3!=2){
trainInOut[i].in.push_back(trainData[index++]);
}else{
trainInOut[i].out.push_back(trainData[index++]);
}
}
}
// 初始化录入的个数据
return vector<Sample>(trainInOut,trainInOut+groups);
}
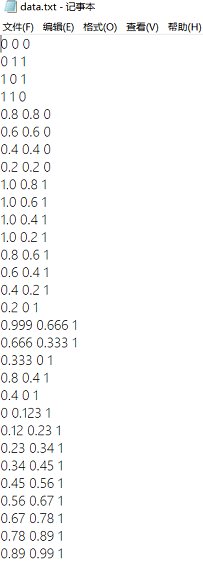
训练数据
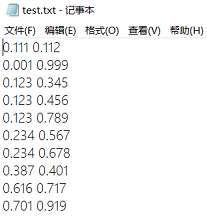
测试数据
运行结果
- 误差:0.001
输入:
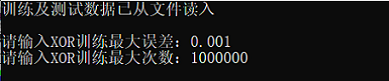
三次测试结果
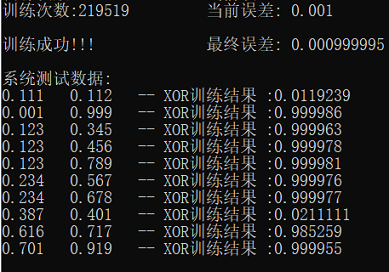
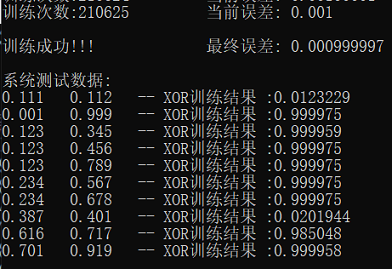
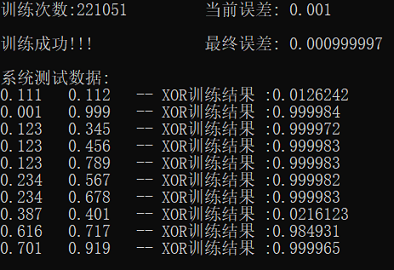
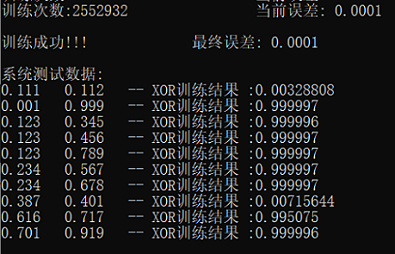
- 误差:0.0001
输入
两次测试结果
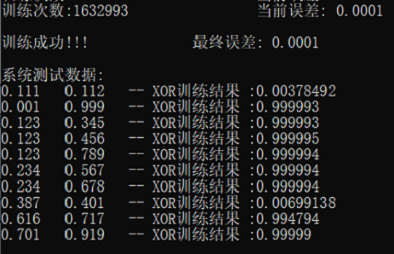
总结:
- 可以看出结果还是比较符合预期 在两个数相差很小时的判断结果就很接近0 其余情况就很接近1
- 在进行调整时 通过减少样本数提高误差的减小速度 从而可以输入更低的误差 但效果不是并很好 所以就选择增加样本 增大学习效率 同时输入一个折中的误差 似乎效果更好点
- 在设置训练数据的时候要尽量包含的范围段全一些 可以大幅提高准确率
但是训练数据如果设置的不太合理的话 可能会导致训练时误差减少的特别慢 最后训练次数可能达到最大值但也没到设置的误差阀值 - 在把误差从0.001降到0.0001之后 训练次数也是大幅翻倍甚至达到250w+次 但是准确率也明显提高 每组结果都更加接近0或1
(附 codeblocks 运行的源码地址:https://github.com/yzx-66/bpNet)
如果有其他看法欢迎留言!!!


















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









