







一.概述
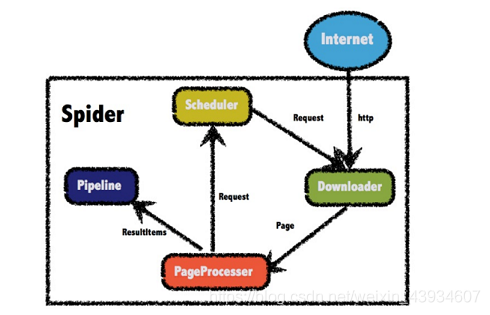
四大组件
-
Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了 ApacheHttpClient作为下载工具 -
PageProcessor
- PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup 作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
- 在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
-
Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供 了“输出到控制台”和“保存到文件”两种结果处理方案。 -
Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内 存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
二.各个组件的使用
1.依赖
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<!--要用redis去保存已经爬取过的链接-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.PageProcessor
- 新建一个类 implements PageProcessor
- 重写:process()、getSite()
public class MyProcessor implements PageProcessor {
public void process(Page page) {
//对爬取到的页面进行的操作
}
public Site getSite() {
//在爬取页面时对http请求的一些设置 例如编码、HTTP头、超时时间、重试策略 等、代理等
return Site.me().setSleepTime(100).setRetryTimes(3);
}
}
-
Page的常用操作
- 将当前页面 里的所有链接都添加到目标页面中
page.addTargetRequests( page.getHtml().links().all() );- 对下面要爬取的链接进行正则表达式的限制
page.addTargetRequests( page.getHtml().links().regex("https://blog.csdn.net/[a‐z 0‐9 ‐]+/article/details/[0‐9]{8}").all() );- 获得爬取到的整个html页面代码
page.getHtml().toString()- 对获取的整个html页面只取得想要部分的标签里的内容
page.getHtml().xpath("//* [@id=\"nav\"]/div/div/ul/li[5]/a").toString();- 获取标签里的属性使用‘@’(比如获取<a herf="" 的herf)
page.getHtml().xpath("/html/body/div/div[4]/div[3]/h2[1]/a/@href")- 把取到的内容保存下来 让Pipeline可以取出 然后保存的数据库或者打印
page.putField("title",page.getHtml().xpath("//* [@id=\"mainBox\"]/main/div[1]/div[1]/h1/text()").toString()) -
Site的可选设置
- setCharset(String):设置编码
- setUserAgent(String):设置UserAgent
- setTimeOut(int):设置超时时间,单位是毫秒
- setRetryTimes(int):设置重试次数
- setCycleRetryTimes(int):设置循环重试次数
- addCookie(String,String):添加一条cookie
- setDomain(String):设置域名,需设置域名 后,addCookie才可生效
- addHeader(String,String): 添加一条 addHeader
- setHttpProxy(HttpHost):设置Http代理
-
注意
- 在process() 方法中一般就是:对下面要爬取的链接进行正则表达式的限制、将要要用的字段保存下来 让Pipeline可以处理
- 在使用page.putField()存入数据之前要先判断在html中取得的数据是否为空
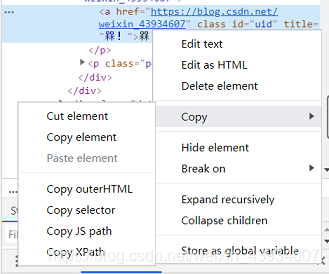
String title= page.getHtml().xpath("//* [@id=\"mainBox\"]/main/div[1]/div[1]/h1/text()").get(); //页面标题 String content= page.getHtml().xpath("//* [@id=\"article_content\"]/div/div[1]").get(); //页面内容 if(title!=null && content!=null){ //如果有标题和内容 page.putField("title",title); page.putField("content",content); }else{ page.setSkip(true);//跳过 }- 在获取XPath的时候 可用通过右键要用的部分 查看该部分网页源代码 然后在该部分html代码再右键选择复制xpath
3.Pipeline
-
常用的自带的有:
- ConsolePipeline:控制台输出
- FilePipeline:文件保存
- JsonFilePipeline:以json方式文件保存
-
定制Pipline(最常用)
import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.pipeline.Pipeline; public class MyPipeline implements Pipeline { public void process(ResultItems resultItems, Task task) { //获得刚才page.putField() 放入的值 String title=resultItems.get("title"); System.out.println("我的定制的 title:"+title); /* * 一般都会在这里放入数据库中持久化 */ } }
- 注意
- 必须要在page. putField()时 给要放入的值调用tostring()方法 不然到时无法转化为string类型
4 Scheduler
-
使用Scheduler的目的是防止重复爬取同一链接 所以需要把爬取过的链接保存下来
-
三种实现方式
- QueueScheduler:内存队列(保存在内存中 不常用)
- FileCacheQueueScheduler :文件队列(保存在本机的文件里 只适合单机 不适合分布式爬虫)
- RedisScheduler:Redis队列(生产环境最常用)
5.Spider
-
Spider是爬虫启动的入口
- create(PageProcessor):创建Spider
- addUrl(String…):添加初始的URL
- thread(n):开启n个线程
- run():启动 会阻塞当前线程执行
- start()/runAsync():异步启动 当前线程继续执行
- stop():停止爬虫
- addPipeline(Pipeline):添加一个 Pipeline 一个Spider可以有多个Pipeline
- setScheduler(Scheduler):设置Scheduler 一 个Spider只能 有个一个Scheduler
- setDownloader(Downloader):设置Downloader 一个Spider只能有个一个Downloader
- get(String):同步调用 并直接取得结果
- getAll(String…):同步调用 并直接取得一堆结果
public static void main(String[] args) { Spider.create( new MyProcessor() ) .addUrl("https://blog.csdn.net") .addPipeline(new ConsolePipeline()) //把已经爬过的链接存入内存 .addPipeline(new FilePipeline("e:/data")) //以一般格式存入文件已经爬过的链接 .addPipeline(new JsonFilePipeline("e:/json")) //以json格式存入文件已经爬过的链接 .addPipeline(new MyPipeline()) //定制化输出(可以写入数据库、文件或者打印等等) //.setScheduler(new QueueScheduler()) //设置内存队列 //.setScheduler(new FileCacheQueueScheduler("E:\\scheduler")) //设置文件队列 .setScheduler(new RedisScheduler("127.0.0.1")) //设置Redis队列(只能有一个Scheduler) .run(); }
6.如果要爬取得内容是图片
- 怎么获得便签中的属性值
//获取到<img>变迁的上一级标签就停止 然后再用.css获取image标签的属性 String image= page.getHtml().xpath("//* [@id=\"asideProfile\"]/div[1]/div[1]/a").css("img","src").toString(); - 爬到链接后下载图片的工具类
import java.io.*; import java.net.URL; import java.net.URLConnection; /** * 下载工具类 */ public class DownloadUtil { public static void download(String urlStr,String filename,String savePath) throws IOException { URL url = new URL(urlStr); //打开url连接 URLConnection connection = url.openConnection(); //请求超时时间 connection.setConnectTimeout(5000); //输入流 InputStream in = connection.getInputStream(); //缓冲数据 byte [] bytes = new byte[1024]; //数据长度 int len; //文件 File file = new File(savePath); if(!file.exists()){ file.mkdirs(); } OutputStream out = new FileOutputStream(file.getPath()+"\\"+filename); //先读到bytes中 while ((len=in.read(bytes))!=‐1){ //再从bytes中写入文件 out.write(bytes,0,len); } //关闭IO out.close(); in.close(); } } - Pipeline怎么下载使用
@Override public void process(ResultItems resultItems, Task task) { String image = resultItems.get("image");//图片地址 String fileName = image.substring(image.lastIndexOf("/")+1); //下载图片 try { DownloadUtil.download(image,fileName,"e:/userimg"); } catch (IOException e) { e.printStackTrace(); } //之后图片已经下载到本地 就可以把该文件路径保存起来了 }
注意:爬取一般都会有定时任务每天去定时爬取
三.案例(爬取csdn的用户名和头像)
1.配置启动类
@SpringBootApplication
@EnableScheduling
public class UserReptileApplication {
//读取在配置文件自己配置的redis地址
@Value("${spring.redis.host}")
private String redis_host;
public static void main(String[] args) {
SpringApplication.run(UserCrawlerApplication.class, args); ''
}
@Bean
public RedisScheduler redisScheduler(){
return new RedisScheduler(redis_host);
}
}
2.爬取类
import org.springframework.stereotype.Component;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* 爬取类
**/
@Component
public class UserProcessor implements PageProcessor {
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/ [a‐z 0‐9 ‐]+/article/details/[0‐9]{8}").all());
/**
* /text():取标签中间的值 不然获取的结果是<>值</>
* /@属性名:取标签里的属性值 比如取<a href="">的href
*/
String nickname= page.getHtml().xpath("//* [@id=\"uid\"]/text()").get();
String image= page.getHtml().xpath("//* [@id=\"asideProfile\"]/div[1]/div[1]/a/img/@src").toString();
if(nickname!=null && image!=null){
//如果有昵称和头像
page.putField("nickname",nickname);
page.putField("image",image);
}else{
page.setSkip(true);//跳过
}
}
@Override
public Site getSite() {
return Site.me().setRetryTimes(3000).setSleepTime(100);
}
}
3.入库类
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import util.DownloadUtil; //上面的文件下载工具类
import java.io.IOException;
@Component
public class UserPipeline implements Pipeline {
@Autowired //无法注入
//自己封装的一个将爬取到用户名和图片保存起来的实体类 这个是该实体类的dao层用来存储实体类
private UserDao userDao;
private static UserPipeline userPipeline ;
@PostConstruct //通过@PostConstruct实现初始化bean之前进行的操作
public void init() {
userPipeline = this;
/**
* 这个类必须用@Component注入spring
* 初使化时将已静态化的userDao实例化
* 使用方式 userDao的方式:userPipeline.userDao
*/
userPipeline .userDao= this.userDao;
}
@Override
public void process(ResultItems resultItems, Task task) {
User user=new User();
user.setNickname(resultItems.get("nickname"));
String image = resultItems.get("image");//图片地址
String fileName = image.substring(image.lastIndexOf("/")+1);
try {
//下载图片
DownloadUtil.download(image,fileName,"e:/userimg");
} catch (IOException e) {
e.printStackTrace();
}
user.setImage(fileName);
userPipeline.userDao.save(user);
}
}
4.任务类
@Component
public class UserTask {
@Autowired
private RedisScheduler redisScheduler; //启动类配置的RedisScheduler
@Autowired
private UserPipeline userPipeline; //自定的Pipeline
@Autowired
private UserProcessor userProcessor;//实现的PageProcessor的类
//springboot定时任务还要给启动类注解 @EnableScheduling
@Scheduled(cron="0 0 0 * * ?") //每天的0点执行
public void userTask(){
System.out.println("爬取用户");
Spider spider = Spider.create(userProcessor);
spider.addUrl("https://blog.csdn.net");
spider.addPipeline(userPipeline);
spider.setScheduler(redisScheduler);
//异步爬取
spider.start();
}
}














 1689
1689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









