







Hadoop小文件优化
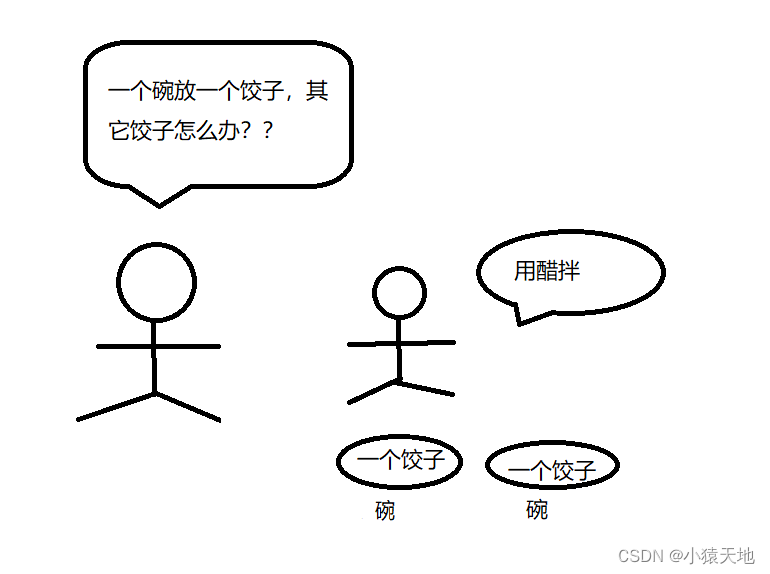
一、小文件的影响
小文件过多会造成元数据量大的情况,因此NameNode会消耗大量内存空间用于存储小文件的元数据,过多的元数据,也会导致寻址索引速度变慢;
小文件过多,会在进行MapReduce运算时,产生多个切片,启动多个MapTask用于计算,就有可能导致MapTask启动时长比运算时长也长。
二、小文件的解决方法
1)数据采集时,进行文件的合并
使用 Hadoop Archive(能高效将小文件放入HDFS的文件存档工具) 将多个小文件打包为一个HAR文件,减少NameNode的内存使用。
2)在HDFS上,使用MapReduce对小文件进行合并
3)采用CombinTextInputFormat处理小文件
CombinTextInputFormat可以将小文件从逻辑上规划到一个切片中。
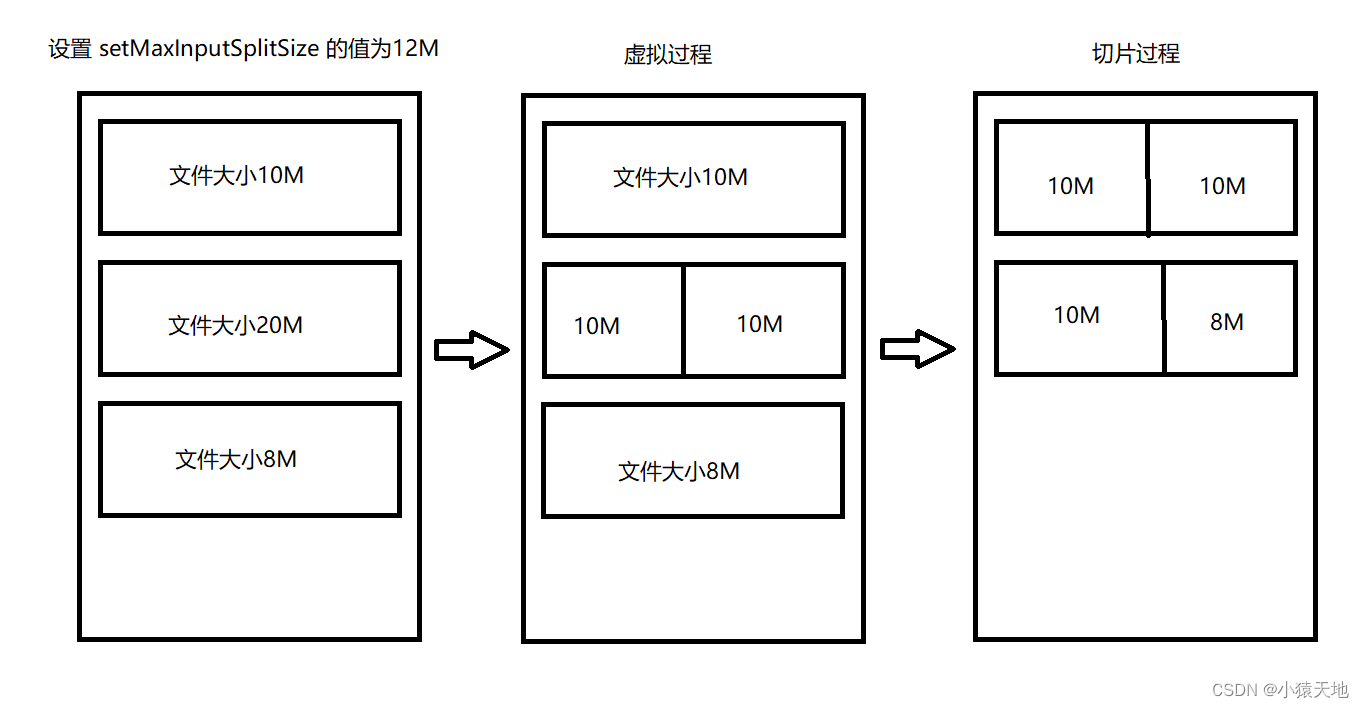
在生成切片时,过程中包括虚拟过程以及切片过程;
虚拟过程:
在文件输入过程中,依次与 setMaxInputSplitSize 的值进行比较,如果文件不大于设置的setMaxInputSplitSize 最大值,会将本文件划分为一个单独的虚拟文件存储块;
如果文件的大于最大值切小于最大值的2倍,会将文件分成两个虚拟存储块,切分后的两个文件的存储大小一致;
如果文件的大于最大值的2倍,会先按最大值切分一个数据块,然后将剩余的文件对半切分;
例如,setMaxInputSplitSize 的值为128M,文件大小为150M,会将文件切分为两个75M虚拟存储文件;如果按128M和22M的大小进行切分,会导致22M的小虚拟存储文件。
切片过程:
在切片过程中会判断虚拟文件的大小是否大于setMaxInputSplitSize 的值,大于则形成一个单独的切片;小于就会与下一个切片进行合并,共同形成一个切片。
4)开启uber模式,实现jvm重用
通常情况下,每个Task任务需要启动一个JVM虚拟环境来运行,如果Task任务计算的数据很小时,我们可以让多个Task任务运行在同一个JVM中。
具体配置,开启uber模式,在 mapred-site.xml 中添加如下配置:
<!-- 开启uber模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- uber模式中最大的mapTask数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- uber模式中最大的reduce数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
<!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value></value>
</property>
<!--可以同时运行多少个job(计算)-->
<property>
<name>mapreduce.job.jvm.numtasks</name>
<value>10</value>
</property>















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









